




前言:
在训练深度学习模型时,通常需要处理大量的数据。GPU的高带宽内存和并行处理能力使其能够更高效地处理大规模数据。,大大缩短训练时间。本文主要记录自己在使用GPU训练YOLOV5所遇到的问题和解决方案。
硬件:
NVIDIA GeForce GTX 1650
软件:
vscode、anaconda
具体步骤:
Step1:搭建环境(优先看注释)

图1 anaconda终端
打开anaconda终端,使用命令进行pytorch的虚拟环境安装,并进入创建好的ptyorch_GPU虚拟环境。
conda create -n pytorch_GPU python=3.10
conda activate pytorch_GPU
注:Python版本选择Python 3.10具体原因为:在Step3中要导入 导入GPU版本的pytorch,在导入时,pytoecc官网中有明显提示Python版本要求在3.9及以上,因此在创建虚拟环境时,先跳到Step3中确认所需要的Python版本,再进行虚拟环境创建。如图2所示。
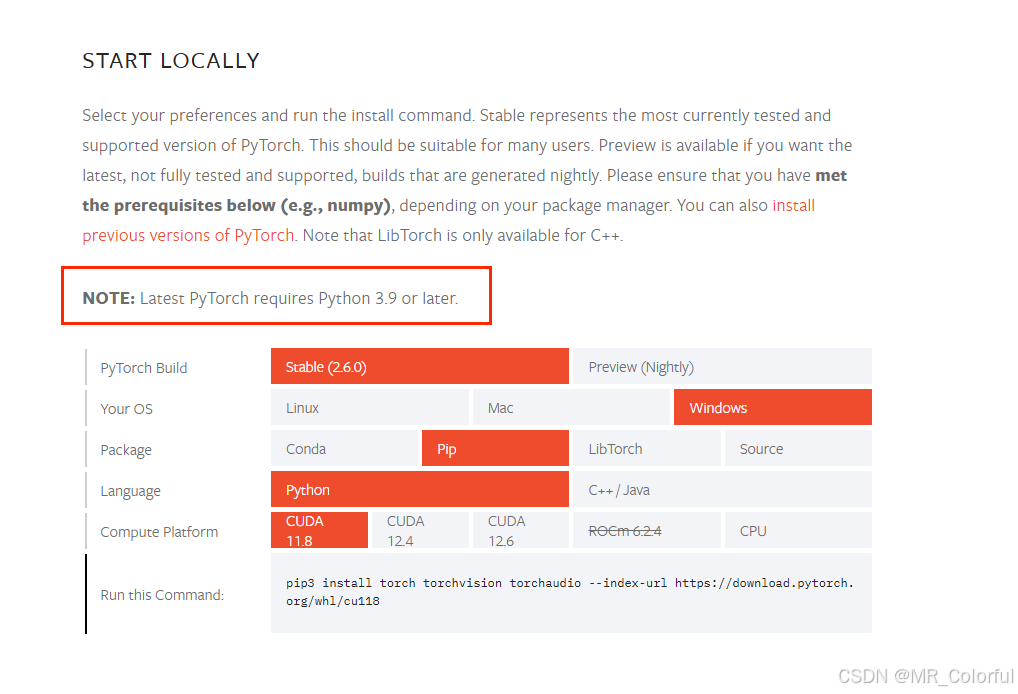
图2 pytoecc官网部分截图1
Step2:查询CUDA版本号
打开计算机终端(win+R,输入cmd,即可进入),输入:
nvidia-smi如图3所示,可以看到自己的 cudaversion的版本,也可以看到本机显卡的编号。记住自己的 cudaversion的版本,在Step3中需要用到。
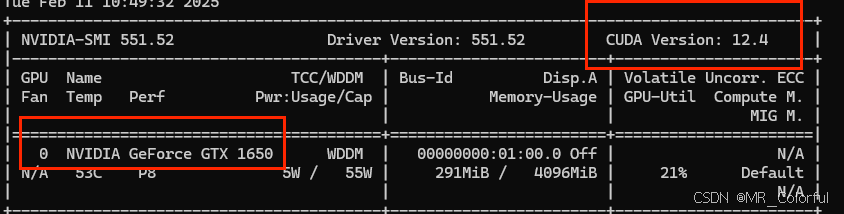
图3 终端运行结果
Step3:导入GPU版本的pytorch
前往pytorch官网:PyTorch,选择相应的GPU版本。根据自己的 cudaversion的版本选择相应的pytorch版本,例如本文的cudaversion的版本为12.4,因此可以选择12.4及以下,本文选择CUDA12.4。选择好后复制Run this Command 中的命令行,到上面创建好的虚拟环境pytorch_GPU中执行即可。如图4所示。
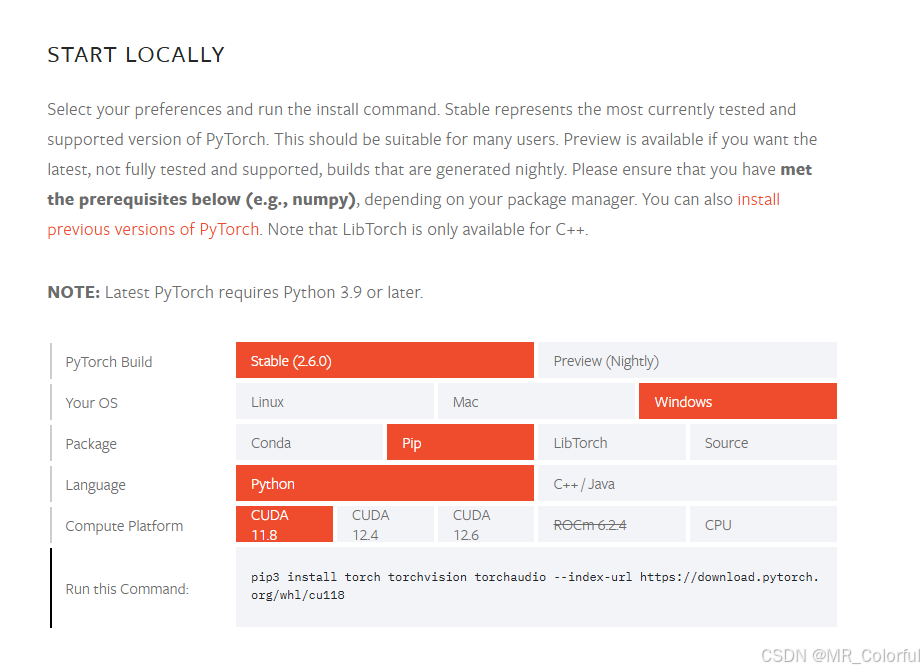
图4 pytoecc官网部分截图2
注:conda安装方式在本文编写的时候,官网已经不再运行使用,故选择pip安装方式。
Step4:在vscode里面添加配置好的环境
打开vscode,在vscode底栏处,选择自己创建好的虚拟环境。如图5所示。

图5 vscode
Step4: 下载安装依赖
在vscode终端中输入:
pip install -r requirements.txt
在安装时若是遇到安装错误,则在该命令末尾加上 -i https://pypi.tuna.tsinghua.edu.cn/simple。其作用是更换镜像源来加速下载。即
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
Step5: 运行train.py
打开train.py,找到下面语句,将 default=' ' 修改至 default='0'。以确保训练时是调用GPU进行训练的。“0”为自己的显卡编号,具体编号查询参考Step2.
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
修改完后开始运行,根据报错信息逐一修改。
运行train.py所遇到的报错信息
报错1:安装 OpenCV 时遇到了网络超时错误
安装某个模块时出现超时问题,报错信息如下:
"D:\Users\23665\miniconda3\envs\pytorch_GPU\lib\ssl.py", line 1163, in read return self._sslobj.read(len, buffer) TimeoutError: The read operation timed out使用国内的镜像源来加速下载。对于 pip,可以使用如下命令:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple报错2:系统页面文件太小,无法加载所需的 DLL 文件
报错信息如下:
[WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\Users\23665\miniconda3\envs\pytorch_GPU\lib\site-packages\torch\lib\cufft64_11.dll" or one of its dependencies.报错原因:该提示所指“页面文件太小”是指系统虚拟内存所设置的页面大小过小,无法支持项目训练时所需内存。
解决方案1:降低Batch_Size大小。
本文所使用的显卡不支持设置过高的batch_size,修改batch_size大小之后,该报错就相应地解决掉了。
解决方案2:调整虚拟内存可用硬盘空间大小
方案参考:Pytorch训练提示错误:“页面文件太小,无法完成操作”
运行效果;
训练时,打开任务管理器,查看gpu1是否有被调用,若有则表明调用GPU训练成功,若没有则应继续根据相应的报错信息进行排查。如图5所示,GPU1基本处于满载运行,因此可以说明调用GPU训练成功。
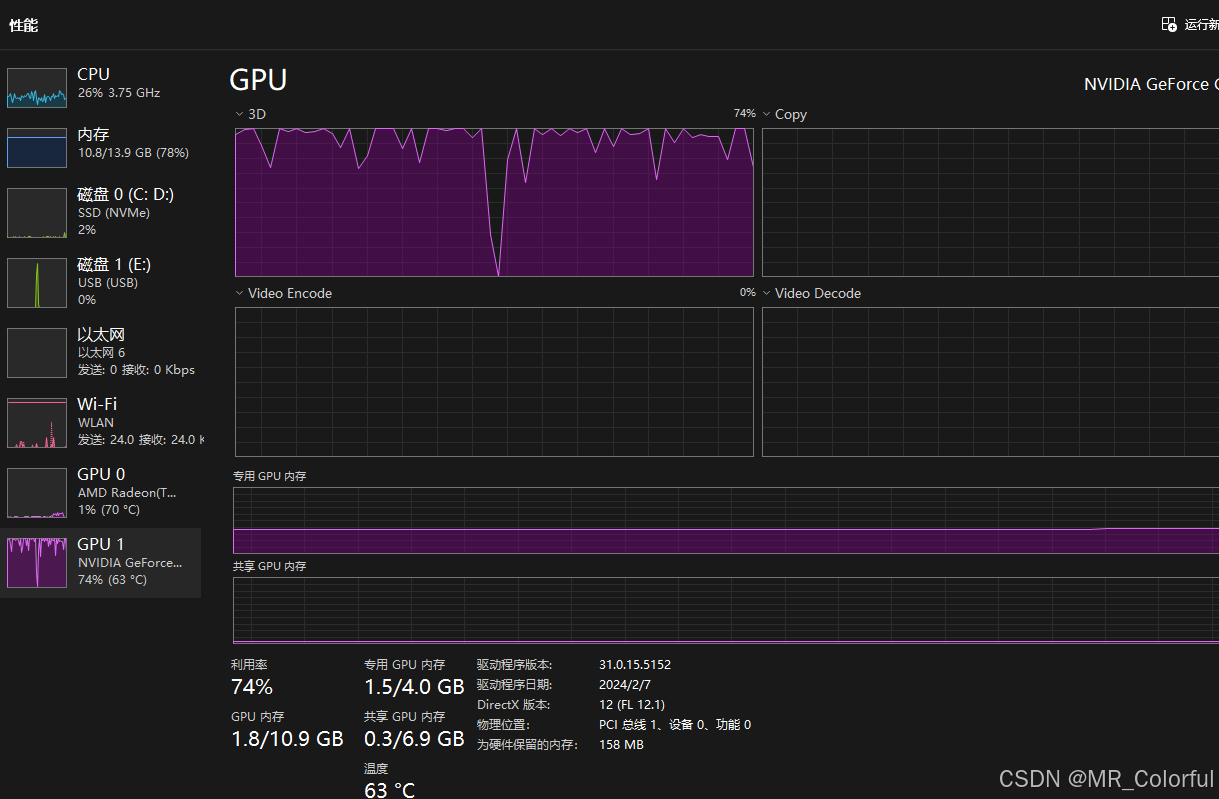
图6 任务管理器
报错3:标签更改后,训练后标签并没有发生改变
1. 标签文件未被正确加载
YOLO 的训练过程并不会直接使用 classes.txt 文件,而是依赖于数据集配置文件(如 orange.yaml)中的 names 字段来定义类别名称。
解决方法:
-
确保
orange.yaml文件中的names字段与 classes.txt 的内容
2. 标签缓存未清除
YOLO 在训练时会生成标签缓存文件(如 labels.cache),如果缓存未清除,可能会导致训练时仍然使用旧的标签数据。
rm /home/jetson/Desktop/ultralytics/data/yahboom_data/orange_data/train/labels.cache
rm /home/jetson/Desktop/ultralytics/data/yahboom_data/orange_data/val/labels.cache

















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









