






题目描述
小蓝正在学习一门神奇的语言,这门语言中的单词都是由小写英文字母组成,有些单词很长,远远超过正常英文单词的长度。小蓝学了很长时间也记不住一些单词,他准备不再完全记忆这些单词,而是根据单词中哪个字母出现得最多来分辨单词。
现在,请你帮助小蓝,给了一个单词后,帮助他找到出现最多的字母和这个字母出现的次数。
输入描述
输入一行包含一个单词,单词只由小写英文字母组成。
对于所有的评测用例,输入的单词长度不超过 1000。
输出描述
输出两行,第一行包含一个英文字母,表示单词中出现得最多的字母是哪个。如果有多个字母出现的次数相等,输出字典序最小的那个。
第二行包含一个整数,表示出现得最多的那个字母在单词中出现的次数。
输入输出样例
示例 1
输入
lanqiao
输出
a
2示例 2
输入
longlonglongistoolong
输出
o
6运行限制
- 最大运行时间:1s
- 最大运行内存: 256M
分析
首先看到题目,第一反应就是用两个数组来做(暴力解)
1.一个数组放字符串,一个数组放每个字母的出现次数
2.把每个字母的出现次数统计完了之后,就要进行大小比较
2.5 .首先要确定大小比较要怎么比较,题中说如果有多个字母出现次数相等,就输出字典序中最小的(例如a和b出现次数一样,则输出a)
3.先把大小比较的第一级框架写好(a的次数比b大,max为a)
4.再把大小比较的第二级框架写好(a的次数和b一样大,max为a)
5.最后输出字母和出现次数(注意输出两行)
编写
碎片代码
先把每个片段的代码思考个大概出来
1.放字符串
直接用gets函数
char arr[1000] = { 0 };
gets(arr);2.统计字母出现次数
这里直接用暴力法(如果有更好的思路,就尝试用更优解,若没有,则先用暴力法,再通过暴力法进行优化,进而找到更优解)
具体就是用switch函数,字母对应的那个数组(a字母对应的数组下标为0)变量值加1,同时判断用数组的下标加1,末尾跟上break
int take[26] = { 0 }, A = 0;
while (arr[A] != '\0')
{
switch (arr[A])
{
case 'a': take[0]++; A++; break;
case 'b': take[1]++; A++; break;
case 'c': take[2]++; A++; break;
case 'd': take[3]++; A++; break;
case 'e': take[4]++; A++; break;
case 'f': take[5]++; A++; break;
case 'g': take[6]++; A++; break;
case 'h': take[7]++; A++; break;
case 'i': take[8]++; A++; break;
case 'j': take[9]++; A++; break;
case 'k': take[10]++; A++; break;
case 'l': take[11]++; A++; break;
case 'm': take[12]++; A++; break;
case 'n': take[13]++; A++; break;
case 'o': take[14]++; A++; break;
case 'p': take[15]++; A++; break;
case 'q': take[16]++; A++; break;
case 'r': take[17]++; A++; break;
case 's': take[18]++; A++; break;
case 't': take[19]++; A++; break;
case 'u': take[20]++; A++; break;
case 'v': take[21]++; A++; break;
case 'w': take[22]++; A++; break;
case 'x': take[23]++; A++; break;
case 'y': take[24]++; A++; break;
case 'z': take[25]++; A++; break;
}
}2.5 .预计要用两个else if函数来判断比较,同时前面要跟上一个for循环进行依次比较
for (A = 0; A < 26; A++)
{
}3.第一级大小比较
主要是比较字母对应的出现次数与最大值的大小
if (take[A] > max)
{
max = take[A];
word = A;
}
else if (take[A] == max)
{
}4.第二级大小比较
主要是比较字母在字典序中的次序
if (A < word)
{
max = take[A];
word = A;
}
else//这里的else可以省略不写,只是暴力解时为了主观上的逻辑完整
{
max = max;
word = word;
}5.最后是输出
完整代码(暴力解)
#include<stdio.h>
int main()
{
char arr[1000] = { 0 };
gets(arr);
int take[26] = { 0 }, A = 0;
while (arr[A] != '\0')
{
switch (arr[A])
{
case 'a': take[0]++; A++; break;
case 'b': take[1]++; A++; break;
case 'c': take[2]++; A++; break;
case 'd': take[3]++; A++; break;
case 'e': take[4]++; A++; break;
case 'f': take[5]++; A++; break;
case 'g': take[6]++; A++; break;
case 'h': take[7]++; A++; break;
case 'i': take[8]++; A++; break;
case 'j': take[9]++; A++; break;
case 'k': take[10]++; A++; break;
case 'l': take[11]++; A++; break;
case 'm': take[12]++; A++; break;
case 'n': take[13]++; A++; break;
case 'o': take[14]++; A++; break;
case 'p': take[15]++; A++; break;
case 'q': take[16]++; A++; break;
case 'r': take[17]++; A++; break;
case 's': take[18]++; A++; break;
case 't': take[19]++; A++; break;
case 'u': take[20]++; A++; break;
case 'v': take[21]++; A++; break;
case 'w': take[22]++; A++; break;
case 'x': take[23]++; A++; break;
case 'y': take[24]++; A++; break;
case 'z': take[25]++; A++; break;
}
}
int max = 0, word = 0;
for (A = 0; A < 26; A++)
{
if (take[A] > max)
{
max = take[A];
word = A;
}
else if (take[A] == max)
{
if (A < word)
{
max = take[A];
word = A;
}
else
{
max = max;
word = word;
}
}
}
printf("%c\n%d", 'a' + word, max);
return 0;
}优化
这个时候,如果有闲心,那么可以再看看写的暴力解代码
全篇最占篇幅的代码块是哪一块?
首当其冲的就是switch那一块
细细分析,其实优化方法也很简单
0 = 字母a - 'a'
1 = 字母b - 'a'
2 = 字母c - 'a'
……
而arr[A]就是表示字母
所以可以将一长串的switch函数删掉
直接动记录次数的数组
while (arr[A] != '\0')
{
take[arr[A] - 'a']++;
A++;
}修改后V2
#include<stdio.h>
int main()
{
char arr[1000] = { 0 };
gets(arr);
int take[26] = { 0 }, A = 0;
while (arr[A] != '\0')
{
take[arr[A] - 'a']++;
A++;
}
int max = 0, word = 0;
for (A = 0; A < 26; A++)
{
if (take[A] > max)
{
max = take[A];
word = A;
}
else if (take[A] == max)
{
if (A < word)
{
max = take[A];
word = A;
}
else
{
max = max;
word = word;
}
}
}
printf("%c\n%d", 'a' + word, max);
return 0;
}再观察修改后的代码
除了输入字符串的代码块外,最占篇幅的只剩大小比较的代码块了
因为take数组表示字母,数组的下标则可以用来表示字母的字典序
又因为0下标表示字母a,所以从表示字母b的下标1开始(A = 1; A < 26; A++)
这样一来,不用再比较字母的字典序
可以直接比较各字母的出现次数,以第一次最大的为最大值,当后面没有更大的值时,最大值始终为第一次出现的最大出现次数,其下标所对应的字母就是出现次数最大的
int max = 0, word = 0;
for (A = 1; A < 26; A++)
{
if (take[A] > take[max])
{
max = A;
}
}
printf("%c\n%d", 'a' + max, take[max]);修改后V3
#include<stdio.h>
int main()
{
char arr[1000] = { 0 };
gets(arr);
int take[26] = { 0 }, A = 0;
while (arr[A] != '\0')
{
take[arr[A] - 'a']++;
A++;
}
int max = 0, word = 0;
for (A = 1; A < 26; A++)
{
if (take[A] > take[max])
{
max = A;
}
}
printf("%c\n%d", 'a' + max, take[max]);
return 0;
}其他优化
其实吧,到这里这道题的代码就差不多够简洁了,不过在蓝桥杯上此题还有一个优解的方法
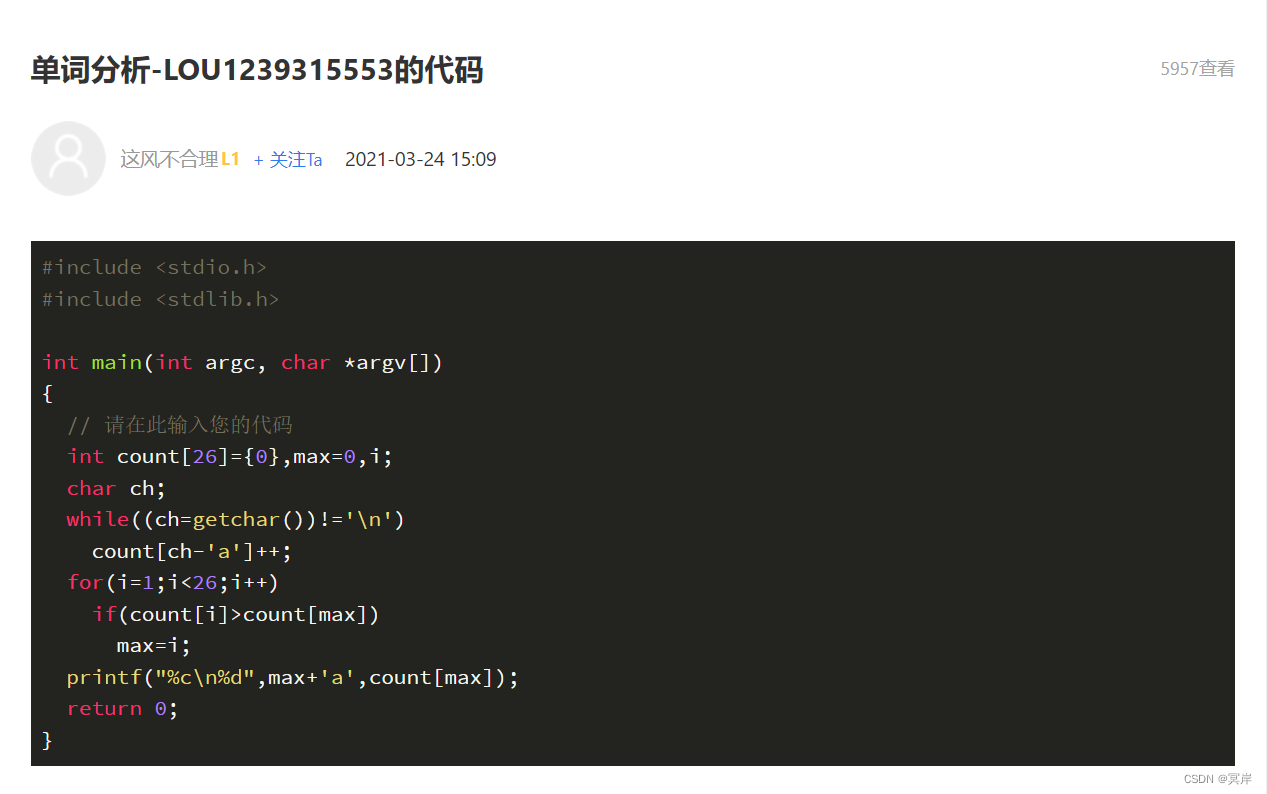
这里这个优解法是用getchar输入每个字母并进行出现次数记录,与gets输入字符串进行次数记录没有太大区别,要注意的点就是用gets输入while判断是!='\0'而getchar输入while判断是!='\n'
除此之外两种优解在内存占用和耗时上没有太大区别
或者说这其实就是一种优解,没有区别
原题网址
单词分析 - 蓝桥云课 (lanqiao.cn) https://www.lanqiao.cn/problems/504/learning/
https://www.lanqiao.cn/problems/504/learning/
题号 - 504

















 1604
1604





 到【灌水乐园】发言
到【灌水乐园】发言







