







在当今的电商时代,淘宝作为全球最大的电子商务平台之一,拥有海量的商品数据。对于商家、市场分析师和数据爱好者来说,了解淘宝商品的销量信息具有至关重要的意义。
首先,对于商家而言,通过采集淘宝商品销量数据,可以深入了解市场需求和竞争态势。他们能够分析哪些商品畅销,哪些商品需要调整营销策略,从而优化产品布局,提高销售业绩。例如,商家可以根据销量数据调整库存管理,避免库存积压或缺货情况的发生。
其次,市场分析师可以利用这些数据进行市场趋势分析。通过对不同品类商品销量的变化趋势进行研究,他们可以预测市场走向,为企业的战略决策提供有力支持。据统计,每年淘宝平台上的商品销量数据呈稳步增长趋势,其中某些热门品类的增长速度更是惊人。
对于数据爱好者来说,淘宝商品销量数据也是一个丰富的数据源,可以用于数据分析和挖掘项目。他们可以通过分析销量数据与其他因素(如商品价格、评价等)之间的关系,探索消费者行为模式。
总之,利用 Python 采集淘宝商品销量数据具有广泛的应用场景和重要价值,可以为不同的用户群体提供有价值的信息和决策支持。
二、采集方法概述
(一)网络爬虫技术基础
网络爬虫是一种自动获取网页信息的程序,在 Python 中,爬取淘宝商品销量通常有以下几种方式。一是利用淘宝提供的公开 API(如果有的话),例如通过淘宝商品销量数据接口可以获取淘宝平台上商品的销量数据。注册并登录淘宝开放平台后,获取 API 密钥,按照接口文档的要求发送 HTTP 请求调用接口,处理和解析返回的 JSON 格式数据,从而提取出所需的销量信息。二是使用第三方的抓取工具库,如 Scrapy、BeautifulSoup 等。对于静态数据,可以使用 requests 和 BeautifulSoup 等基础库;如果是动态加载的,可能需要用到 Selenium 或者 PyQuery 等库配合。例如使用 Selenium 模拟人工操作,绕过简单的反爬机制,通过编写脚本,可以灵活采集页面上的动态数据,适用于复杂页面结构的采集。
(二)面临的挑战
淘宝有严格的反爬虫策略,这给数据采集带来了诸多挑战。一方面,可能会遇到 IP 限制问题。当频繁请求淘宝页面时,淘宝服务器可能会识别出异常的 IP 访问行为,进而限制该 IP 的访问。为应对此问题,可以使用代理 IP,轮换 IP 地址以降低被封禁的风险。另一方面,验证码也是常见的难题。当系统检测到异常访问时,可能会弹出验证码要求验证,这会中断数据采集过程。为了尽量避免验证码的出现,可以控制请求频率,避免过于频繁的请求被封禁。同时,随机设置 User-Agent,模拟不同浏览器的请求头,使请求看起来更像正常的用户访问。此外,还可以设置合理的请求间隔时间,并尽量模拟真实用户行为,如在不同操作的时候插入一个随机暂停执行函数等。总之,在采集淘宝商品销量数据时,需要综合运用各种技术手段来应对淘宝的反爬虫策略。
三、具体步骤详解
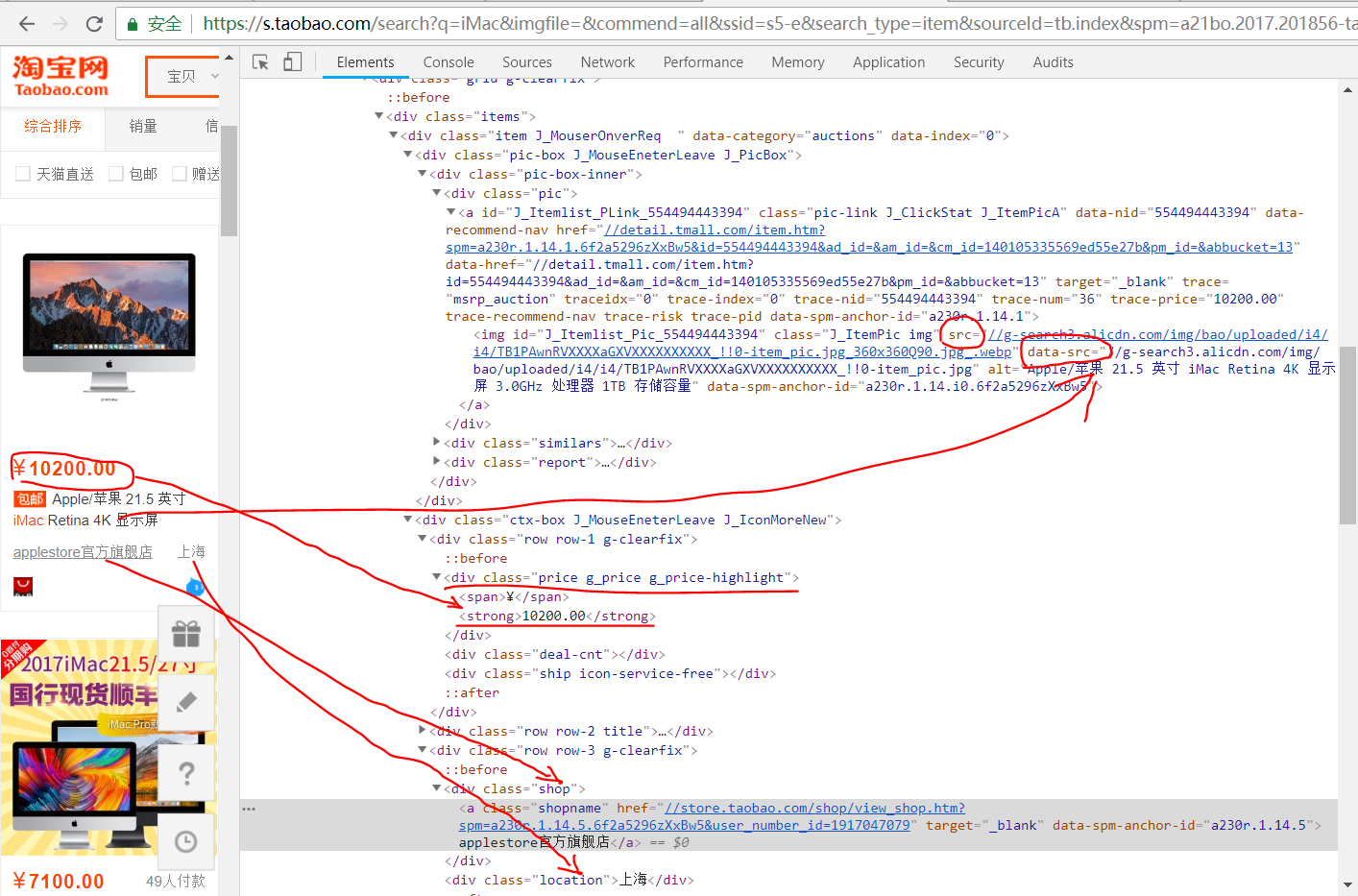
(一)分析网页结构
首先,我们可以通过浏览器的开发者工具来查看目标页面的 HTML 源码。以谷歌浏览器为例,在页面上右键点击,选择 “检查”,即可打开开发者工具。在开发者工具中,我们可以找到 “Elements” 选项卡,这里展示了当前页面的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









