



desc pdb_analysis_c.ads_flow_rank_num_d,
使用上面的desc 关键字就可以知道hive表当中有多少字段,每个字段的数据类型和解释
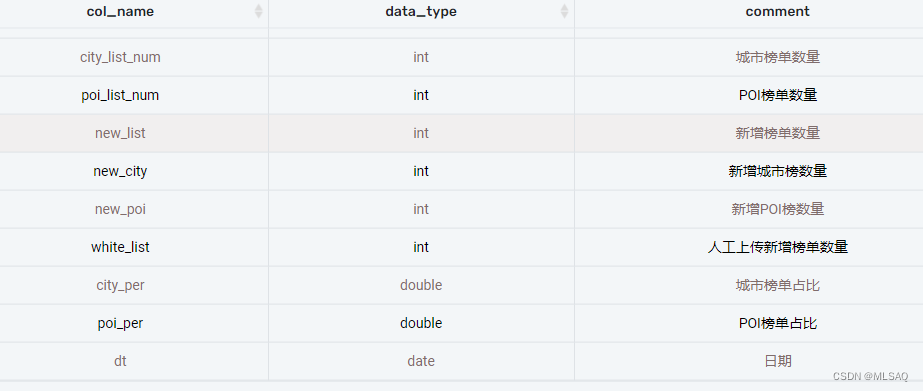
如果查看建表语句可以用另外篇
 本文介绍了如何使用descpdb函数在Hive中分析表结构,关注字段数量、数据类型及其解释。另一篇文章则探讨了查看建表语句的方法。
本文介绍了如何使用descpdb函数在Hive中分析表结构,关注字段数量、数据类型及其解释。另一篇文章则探讨了查看建表语句的方法。
desc pdb_analysis_c.ads_flow_rank_num_d,
使用上面的desc 关键字就可以知道hive表当中有多少字段,每个字段的数据类型和解释
如果查看建表语句可以用另外篇
 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























