





摘要:在进行SWAT-CUP进行SWAT模型的调参率定的过程中,输入站点实测径流量的操作(制备Observed rch.txt)中,如果数据量过多,手动输入会导致工作量增加并且导致人为误差,为了减少繁琐程度和工作量,利用AI编写了一个python代码,可以将excel中记录的径流量数据转换为能够直接复制粘贴到“Observed rch.txt”中的txt文本格式,方便调参。本代码操作简单,设置了专门的用户配置区,老少咸宜。
一句话讲明白代码功能:给它一个按年、月顺序整理好的 Excel(或一列顺序的月径流),设定时间范围和列/行位置,它就能自动生成从起始年到结束年,每月一行、格式符合 SWAT-CUP 要求的径流输入 txt,并在最后帮你检查年月是否缺失或数据条数是否匹配。
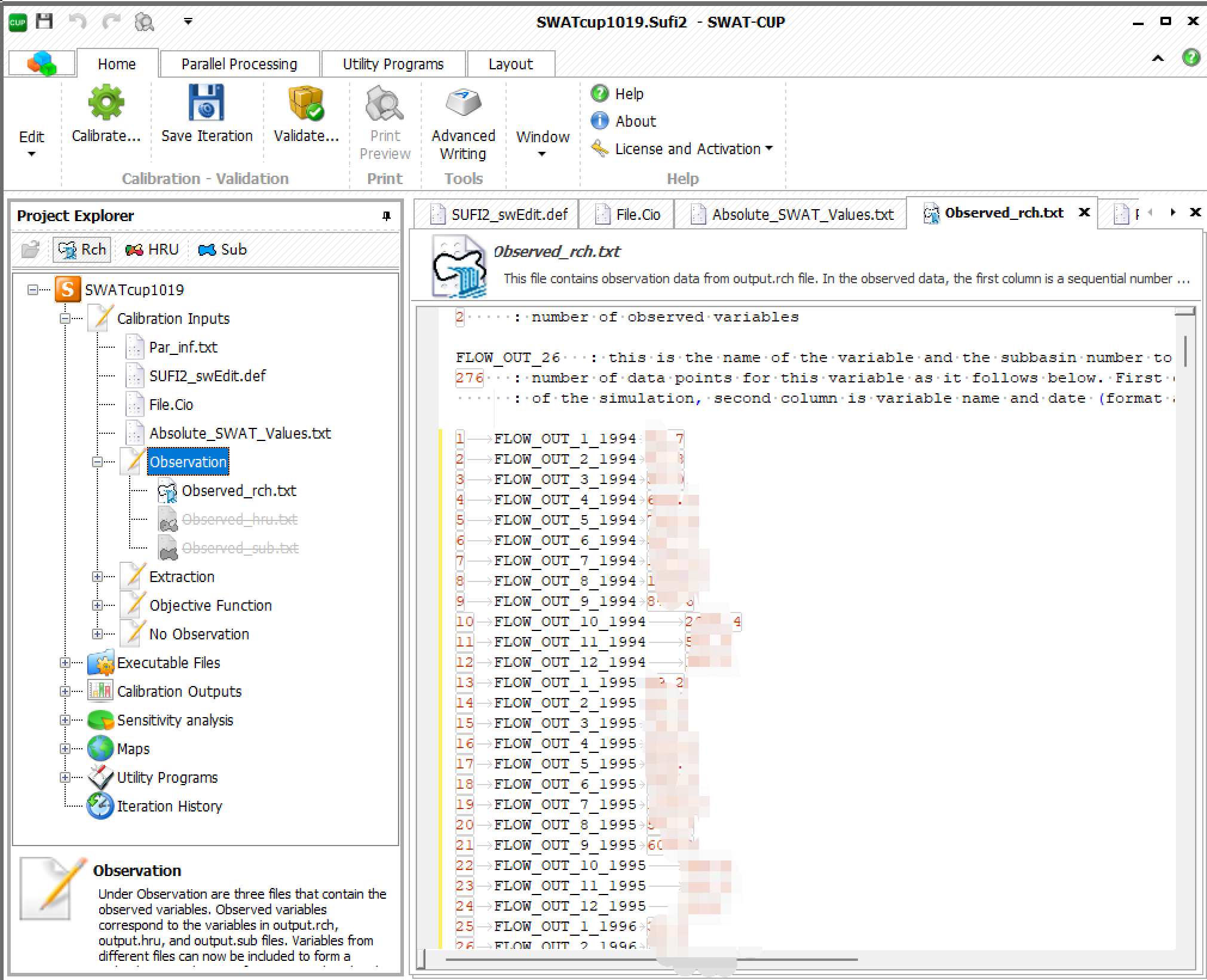
图1:SWAT-CUP中Observed rch.txt界面
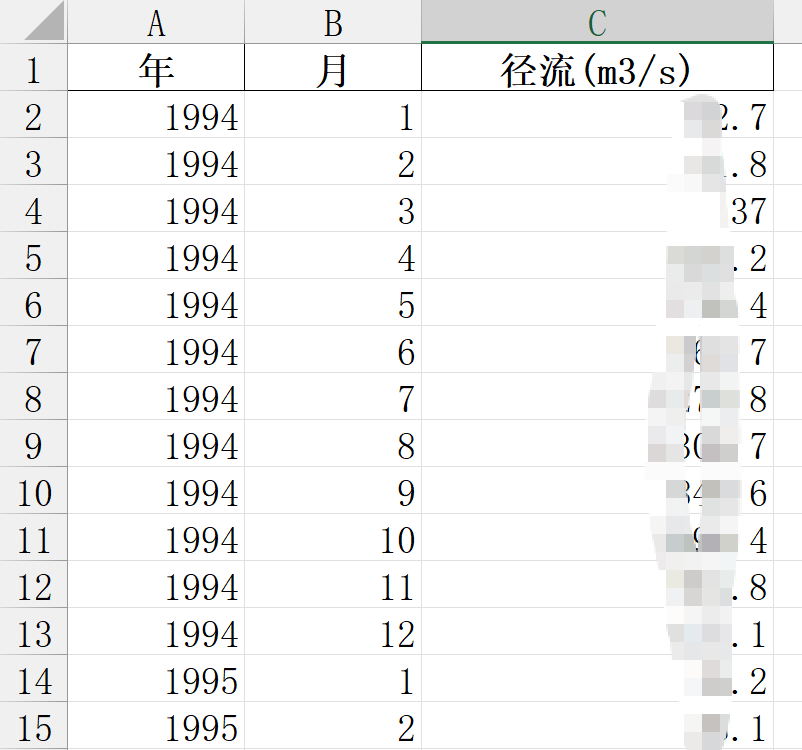
图2:代码所需的excel格式(可以有年月,不是必须,只有径流列也可以生成txt,不过要按日期排序)
具体代码如下:
# -*- coding: utf-8 -*-
"""
功能:
1.自动生成完整年月序列:代码根据你设定的 START_YEAR/START_MONTH 和 END_YEAR/END_MONTH,
从起始年月一直推到结束年月,按月生成一个完整的时间序列。序列中的每一行都会自动生成一个标签,
格式为 FLOW_OUT_月_年,前面带从 1 开始依次递增的行号,为后续径流填充和 SWAT-CUP 读取打好“骨架”。
2.输出 SWAT-CUP 需要的 txt 格式:在生成好年月序列后,代码会把每个月的信息写成一行 txt,
行内用制表符(Tab)分隔,固定格式为 行号\tFLOW_OUT_月_年\t径流量。
最终 txt 的总行数等于起止年月之间包含的全部月份数,已经按时间顺序排好,直接可以作为 SWAT-CUP 的输入文件。
3.两种填充径流方式(由 USE_MONITOR 控制):
当 USE_MONITOR = True 时为监测模式:
你在配置区指定年列、月列、径流列(YEAR_COL_INDEX / MONTH_COL_INDEX / FLOW_COL_INDEX),
程序从 Excel 读取“年、月、径流”,用 (年, 月) 精确匹配每一行的标签,把对应月份的径流填进去;
同时对年、月的解析比较鲁棒,支持纯数字、字符串、带“年”“月”的形式、日期格式等,
并在最后列出哪些年月在 Excel 中没找到径流值(这些月份在 txt 中留空)。
当 USE_MONITOR = False 时为顺序模式:
程序只按照你指定的 FLOW_COL_INDEX 这一列,从上到下顺序读取径流,依次填入每一行,
最后对比 txt 行数和 Excel 径流条数是否一致,帮助你检查时间序列有没有对齐。
4.可控的数据范围与工作表:你可以通过 SHEET_INDEX 指定要使用 Excel 的第几个工作表,
从而在同一个文件中自由切换不同表格的数据。同时通过 DATA_START_ROW 和 DATA_END_ROW 控制从第几行开始读、读到第几行,
既可以轻松跳过表头,也可以只截取某一部分年份或数据段参与生成 txt,避免手动删改原始 Excel。
5.路径和文件名完全可配置:EXCEL_FILE 用来指定输入 Excel 的完整路径和文件名,OUTPUT_TXT
用来指定输出 txt 的完整路径和文件名。你只要在配置区改这两个变量,就可以把同样的转换逻辑应用到不同的数据文件上,
或者生成不同名称的 SWAT-CUP 径流输入文件(例如你现在使用的“江桥 SWAT-CUP 径流输入格式 1994–2016”)
"""
import pandas as pd
from pathlib import Path
# =====================【用户可配置区:只改这里就行】=====================
# 1. Excel 文件路径
EXCEL_FILE = r"F:\你的径流excel位置.xlsx"
# 2. Excel 中的数据所在工作表序号(0 = 第 1 个工作表,1 = 第 2 个,以此类推)
SHEET_INDEX = 1
# 3. 从第几行开始读取数据(按 Excel 的“行号”来数)
# 比如:第 1 行是表头“年 月 径流...”,第 2 行开始是 1994 1 22.7
# 那就设为 DATA_START_ROW = 1
DATA_START_ROW = 1 # 第一条有效数据所在“行号”;若没有表头,第 1 行就是数据,则设为 0
DATA_END_ROW = None # 一般用 None 表示读到最后一行
# 4. 监测开关:
# - True:使用“年+月”匹配(Excel 中必须有 年列 和 月列)
# - False:不匹配,径流列按顺序直接填充
USE_MONITOR = True
# 5. 当 USE_MONITOR=True 时,需要告诉程序“年/月/径流”的列号
# 列号:0=A列,1=B列,2=C列 ...
YEAR_COL_INDEX = 0 # 年份所在列号(例如年份在 A 列 → 0)
MONTH_COL_INDEX = 1 # 月份所在列号(例如月份在 B 列 → 1)
FLOW_COL_INDEX = 2 # 径流量所在列号(例如径流在 C 列 → 2)
# 6. 当 USE_MONITOR=False 时,也会用 FLOW_COL_INDEX 这列按顺序填充
# 7. 起始年份、起始月份(对应“序列里的第一个年月”)
START_YEAR = 1994
START_MONTH = 1
# 8. 结束年份、结束月份(对应“序列里的最后一个年月”)
END_YEAR = 2024
END_MONTH = 12
# 9. 输出 txt 文件保存路径(包含文件名)
OUTPUT_TXT = r"F:\输出txt位置和命名.txt"
# =====================【配置区结束,下面一般不用改】=====================
def parse_int_like(x):
"""
尽量把 Excel 里看起来是“年份/月份”的东西转成整数:
- 支持 1994, 1994.0
- 支持 '1994', ' 1994 ', '1994年'
- 支持 '1', '01', '1月'
- 支持日期型,如 1994-01-01(会提取里面的数字)
解析失败会抛出异常,由上层决定是否跳过该行。
"""
if pd.isna(x):
raise ValueError("值是 NaN")
s = str(x).strip()
# 只保留数字和负号,例如 '1994年'、'1994-01-01'
digits = "".join(ch for ch in s if (ch.isdigit() or ch == "-"))
if digits == "":
raise ValueError(f"找不到数字: {x!r}")
return int(digits)
def build_month_list(start_year, start_month, end_year, end_month):
"""
根据起止年月生成一个 [(year, month), ...] 的列表,包含起止两端。
"""
if (end_year, end_month) < (start_year, start_month):
raise ValueError("结束年月早于起始年月,请检查 START/END 设置。")
months = []
y, m = start_year, start_month
while True:
months.append((y, m))
if (y, m) == (end_year, end_month):
break
m += 1
if m > 12:
m = 1
y += 1
return months
def read_excel_monitor_mode():
"""
监测模式:
从 Excel 中读取 年、月、径流 列,生成 {(year, month): flow} 的字典。
"""
df = pd.read_excel(EXCEL_FILE, sheet_name=SHEET_INDEX)
start_idx = DATA_START_ROW - 1 if DATA_START_ROW is not None else 0
if DATA_END_ROW is None:
df_sub = df.iloc[start_idx:, :]
else:
df_sub = df.iloc[start_idx:DATA_END_ROW, :]
year_series = df_sub.iloc[:, YEAR_COL_INDEX]
month_series = df_sub.iloc[:, MONTH_COL_INDEX]
flow_series = df_sub.iloc[:, FLOW_COL_INDEX]
mapping = {}
for y, m, f in zip(year_series, month_series, flow_series):
try:
yy = parse_int_like(y)
mm = parse_int_like(m)
except Exception:
# 这一行年/月解析失败,直接跳过
continue
mapping[(yy, mm)] = f # 若同一 (年,月) 多次出现,以最后一次为准
return mapping
def read_excel_sequential_mode():
"""
非监测模式:
从 Excel 中读取某一列径流量,按顺序返回 list。
"""
df = pd.read_excel(EXCEL_FILE, sheet_name=SHEET_INDEX)
start_idx = DATA_START_ROW - 1 if DATA_START_ROW is not None else 0
if DATA_END_ROW is None:
flow_series = df.iloc[start_idx:, FLOW_COL_INDEX]
else:
flow_series = df.iloc[start_idx:DATA_END_ROW, FLOW_COL_INDEX]
return list(flow_series)
def generate_txt():
"""
主函数:
先生成完整年月行,再根据监测开关选择填充方式,最后写 txt。
"""
# 1. 构建所有 (year, month) 序列
ym_list = build_month_list(START_YEAR, START_MONTH, END_YEAR, END_MONTH)
total_months = len(ym_list)
# 2. 根据 USE_MONITOR 选择读取 Excel 的方式
if USE_MONITOR:
ym_to_flow = read_excel_monitor_mode()
print(f"监测模式:共从 Excel 中读取到 {len(ym_to_flow)} 个“年-月-径流”记录。")
else:
flow_seq = read_excel_sequential_mode()
excel_flow_count = len(flow_seq)
print(f"顺序模式:从 Excel 中读取到 {excel_flow_count} 条径流数据。")
# 3. 输出 txt
out_path = Path(OUTPUT_TXT)
out_path.parent.mkdir(parents=True, exist_ok=True)
missing_months = [] # 只在 USE_MONITOR=True 时用
with out_path.open("w", encoding="utf-8") as f:
for idx, (y, m) in enumerate(ym_list, start=1):
label = f"FLOW_OUT_{m}_{y}"
if USE_MONITOR:
# 按 (年, 月) 匹配
if (y, m) in ym_to_flow:
flow_val = ym_to_flow[(y, m)]
else:
flow_val = ""
missing_months.append((y, m))
else:
# 按顺序填充
if idx - 1 < len(flow_seq):
flow_val = flow_seq[idx - 1]
else:
flow_val = "" # Excel 不够长时后面的行留空
line = f"{idx}\t{label}\t{flow_val}\n"
f.write(line)
print(f"已生成 txt 文件:{out_path}")
print(f"总行数(月份数):{total_months}")
# 4. 额外信息输出
if USE_MONITOR:
if missing_months:
print("监测结果:在下列年月中未在 Excel 中找到径流值(已在 txt 中留空):")
# 按年份排序输出
missing_months_sorted = sorted(missing_months)
for y, m in missing_months_sorted:
print(f" {y}-{m}")
else:
print("监测结果:所有月份在 Excel 中都找到了对应的径流值,没有缺失。")
else:
# 对比 txt 行数和 Excel 径流条数
same_len = (total_months == excel_flow_count)
print(f"对比:txt 行数 = {total_months},Excel 径流条数 = {excel_flow_count},是否一致:{same_len}")
if __name__ == "__main__":
generate_txt()
文章结束,祝各位身体健康 心情愉快 科研顺利 工作有得!


















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









