







 超级会员免费看
超级会员免费看
背景
云原生flink流计算平台解决方案验证
该架设方案全部基于云原生k8s,通俗讲就是 flink任务跑在k8s上
环境要求
k8s部署的话可以看看 k8s-1.25.4部署笔记(containerd)
Flink Native Kubernetes集群部署
- 前提条件
- Kubernetes 版本 >= 1.9
➜ ~ kubectl version --short
Client ➜ ~ Version: v1.24.4
Kustomize Version: v4.5.4
Server Version: v1.24.4
- 确保您的 ~/.kube/config 文件已正确配置以访问 Kubernetes 集群
➜ ~ export KUBECONFIG=~/.kube/config
➜ ~ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master2 Ready control-plane 9d v1.24.4
k8s-node1 Ready <none> 9d v1.24.4
k8s-node2 Ready <none> 9d v1.24.4
k8s-node3 Ready <none> 25h v1.24.4
- 是否启用 Kubernetes DNS正常
➜ ~ kubectl cluster-info
Kubernetes control plane is running at https://192.168.103.201:6443
CoreDNS is running at https://192.168.103.201:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
- 账户具有 RBAC 权限,确保您的命名空间中的 服务账户具有创建和删除 Pod 的必要 RBAC 权限。我创建新的命名空间为flink-native
kubectl create namespace flink-native
kubectl create serviceaccount flink-sa -n flink-native
kubectl create clusterrolebinding flinknative-role-binding-flinknative -n flink-native --clusterrole=edit --serviceaccount=flink-native:flink-sa
- 在k8s中启动flink集群
- flink1.20
./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=flink-cluster1 \
-Dtaskmanager.memory.process.size=4096m \
-Dkubernetes.taskmanager.cpu=2 \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dkubernetes.namespace=flink-native \
-Dkubernetes.service-account=flink-sa \
-Dresourcemanager.taskmanager-timeout=3600000
- 关闭集群
kubectl delete deployment/flink-cluster1
Dinky 流计算平台部署(helm)
- 创建pvc
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dinky-config-volume
namespace: data-center
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dinky-lib-volume
namespace: data-center
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
- dinky-config-volume 用于放置配置文件(helm 包内的conf目录文件)
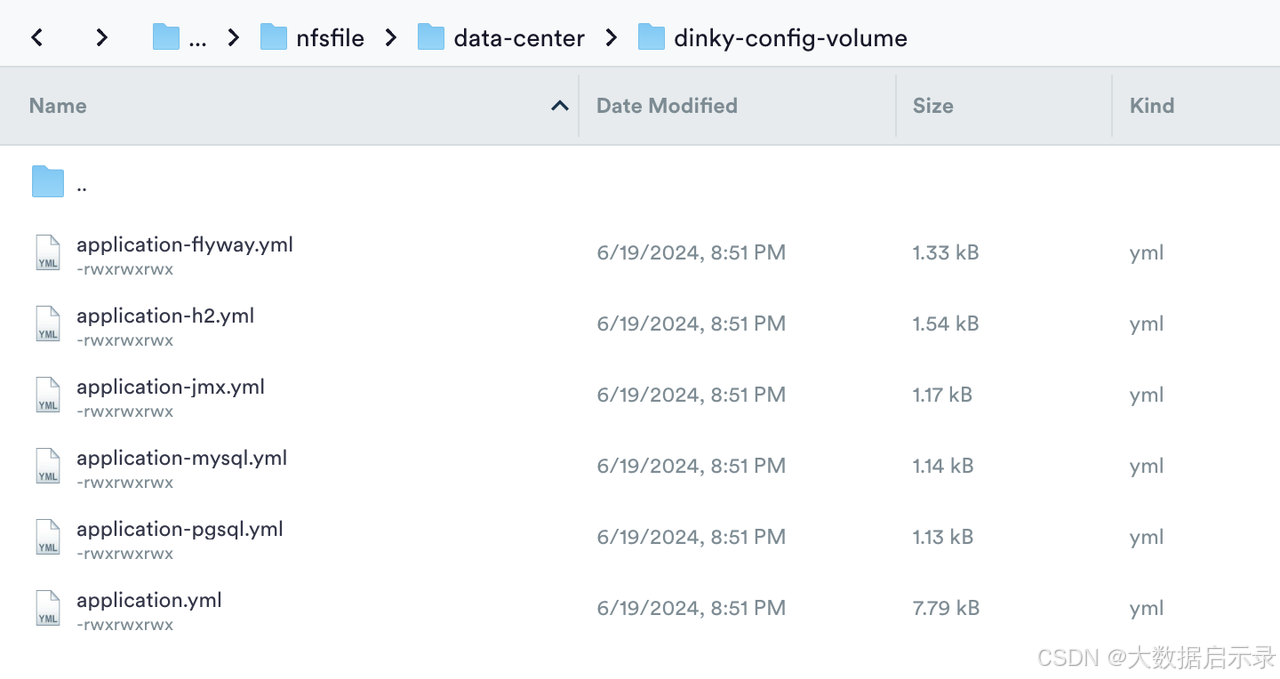
- dinky-lib-volume 用于放置自定义jar包,映射的/opt/dinky/customJar/
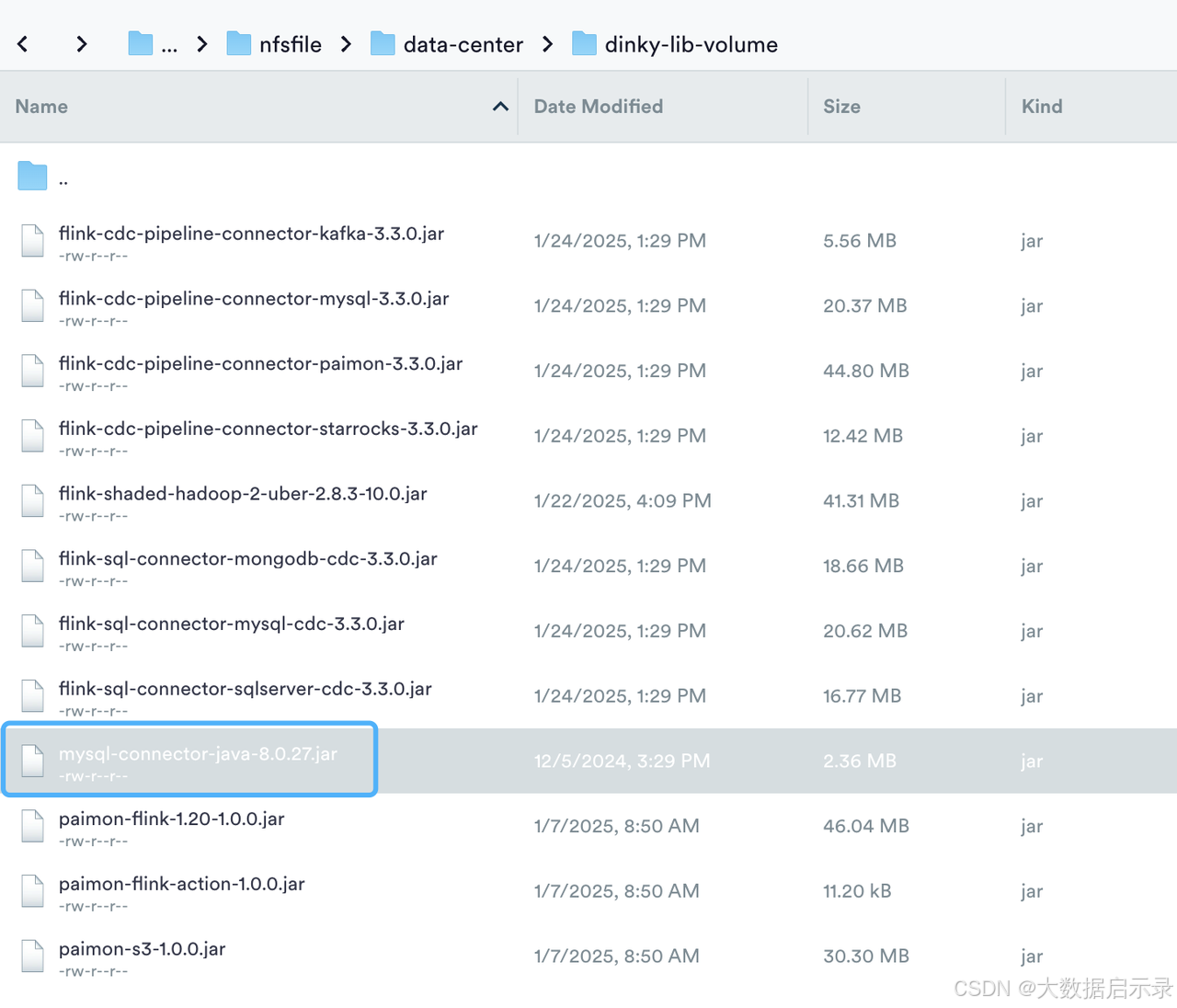
- 调整helm包
- 部署文件
- helm包经久未维护,我改了下
- dinky.yaml 增加volumes:
volumes:
- name: dinky-lib-volume
persistentVolumeClaim:
claimName: dinky-lib-volume
- dinky.yaml 增加volumeMounts:
volumeMounts:
- mountPath: /opt/dinky/customJar
name: dinky-lib-volume
- dinky.yaml 修正auto.sh目录位置错误,原来是/opt/dinky/auto.sh
command:
- /bin/bash
- '-c'
- >-
/opt/dinky/bin/auto.sh startOnPending {{ .Values.spec.extraEnv.flinkVersion}}
- values.yaml 配置mysql
mysql:
enabled: true
url: "192.168.103.113:3306"
auth:
username: "root"
password: "XXX"
database: "dinky"
- 部署
helm install dinky . -f values.yaml -n data-center
helm uninstall dinky -n data-center
- 在dinky内增加刚刚创建的Flink Native Kubernetes集群
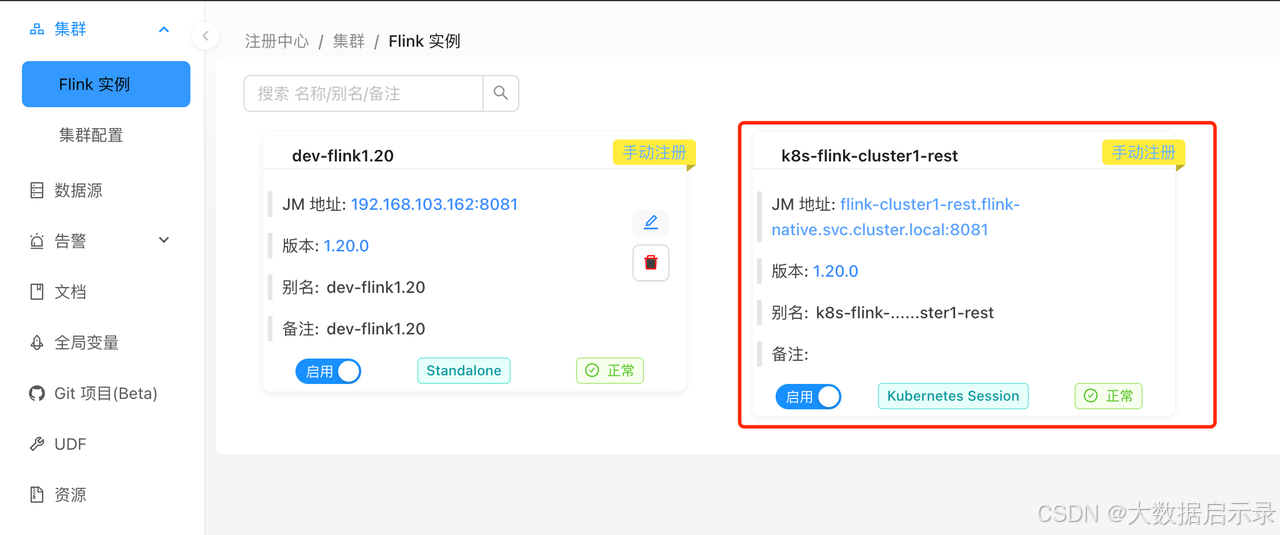
流计算实践
实践1: mysql cdc connector 写入 paimon
dinky基于flink sql的作业类型
打开dinky页面,新建Flink Sql任务
EXECUTE CDCSOURCE demo WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'test\..*',
'sink.connector' = 'sql-catalog',
'sink.catalog.name' = 'fts',
'sink.catalog.type' = 'table-store',
'sink.catalog.warehouse'='file:/tmp/table_store',
'sink.auto-create' = 'true', -- 可自动paimon建表
);
实践2: paimon cdc 写入 paimon
dinky基于flink jar的作业类型 (paimon-flink-action-1.0.0.jar)
打开dinky页面,新建Flink jar任务
- 原始提交命令:
./bin/flink run \
./lib/paimon-flink-action-0.9.0.jar \
mysql_sync_database \
--warehouse s3://lakehouse-1253767413/paimon \
--database app_db \
--mysql_conf hostname=192.168.103.113 \
--mysql_conf username=root \
--mysql_conf password=XXX \
--mysql_conf database-name=app_db \
--catalog_conf s3.endpoint=cos.ap-guangzhou.myqcloud.com \
--catalog_conf s3.access-key=XXX \
--catalog_conf s3.secret-key=XXX \
--table-conf bucket=1
- dinky作业
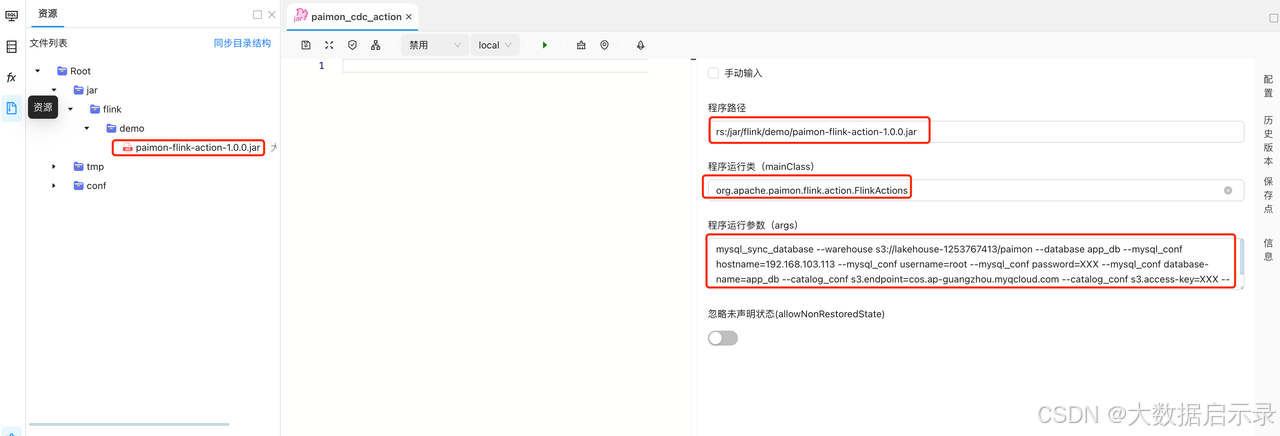
实践3: flink cdc pipline 写入 paimon
dinky基于flink sql的作业类型
打开dinky页面,新建Flink Sql任务
示例:
SET 'execution.checkpointing.interval' = '10s';
EXECUTE PIPELINE WITHYAML (
source:
type: mysql
name: MySQL Source
hostname: 127.0.0.1
port: 3306
username: admin
password: pass
tables: adb.\.*, bdb.user_table_[0-9]+, [app|web].order_\.*
server-id: 5401-5404
sink:
type: paimon
name: Paimon Sink
catalog.properties.metastore: filesystem
catalog.properties.warehouse: /path/warehouse
pipeline:
name: MySQL to Paimon Pipeline
parallelism: 1
)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









