




Week 20: 深度学习补遗:Transformer Decoder架构
摘要
本周跟随李宏毅老师的课程学习了Transformer Decoder方面的内容,针对其设计理念以及运作方式进行了一定的了解。
Abstract
This week, through Professor Hung-yi Lee’s course, I studied the Transformer Decoder, gaining a solid understanding of its design philosophy and operational mechanisms.
1. Transformer Decoder - Autoregressive 自回归
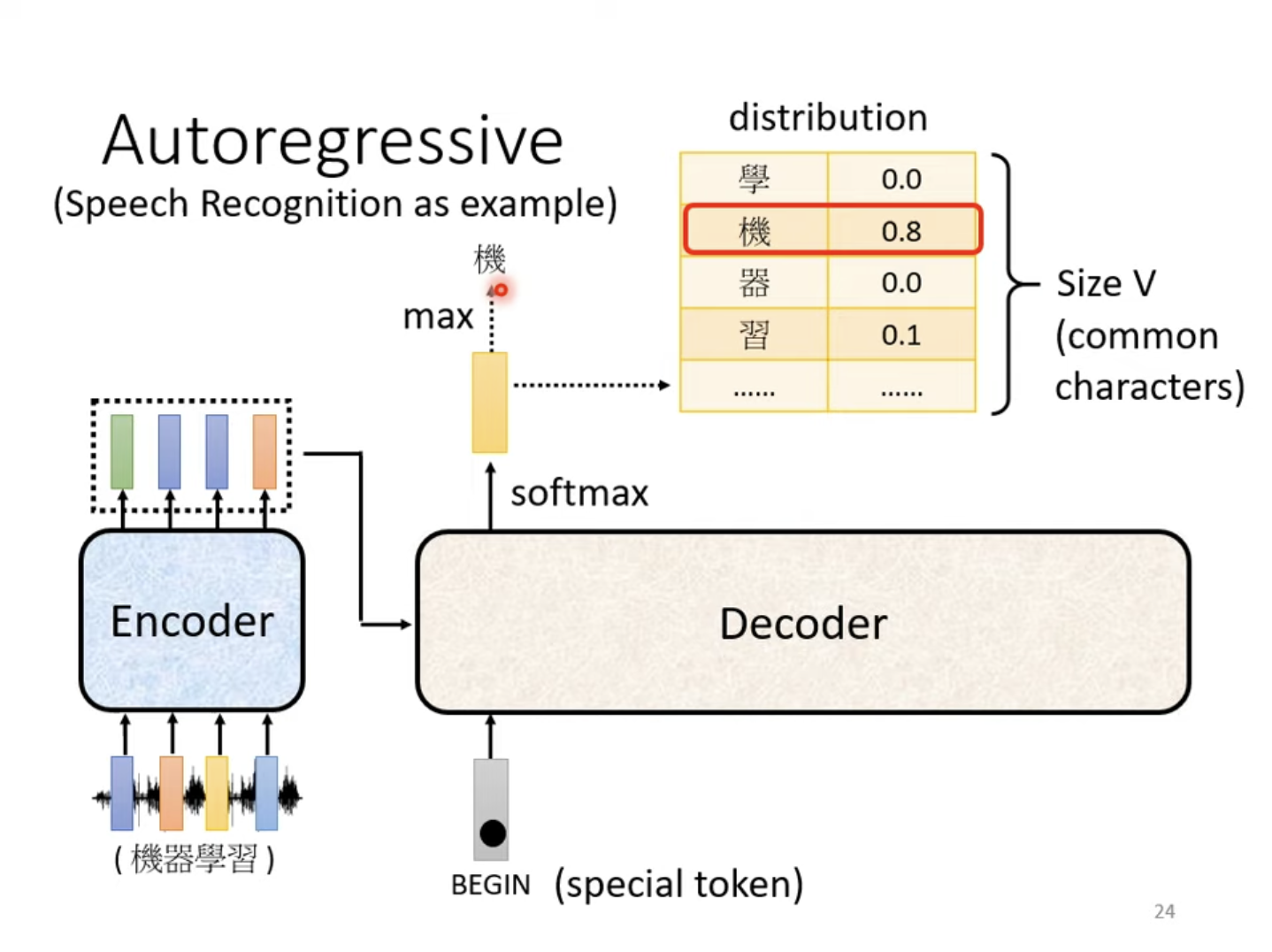
由Encoder导出一个向量输入Decoder后,先对Decoder输入一个Special Token “BEGIN”(或“BOS”,Begin of Sentence),Decoder会输出一个概率分布向量,其尺寸VVV是常用词的大小,比如中文方块字的数量,代表下一个输出的概率,概率最大的那个即为模型的下一个输出。
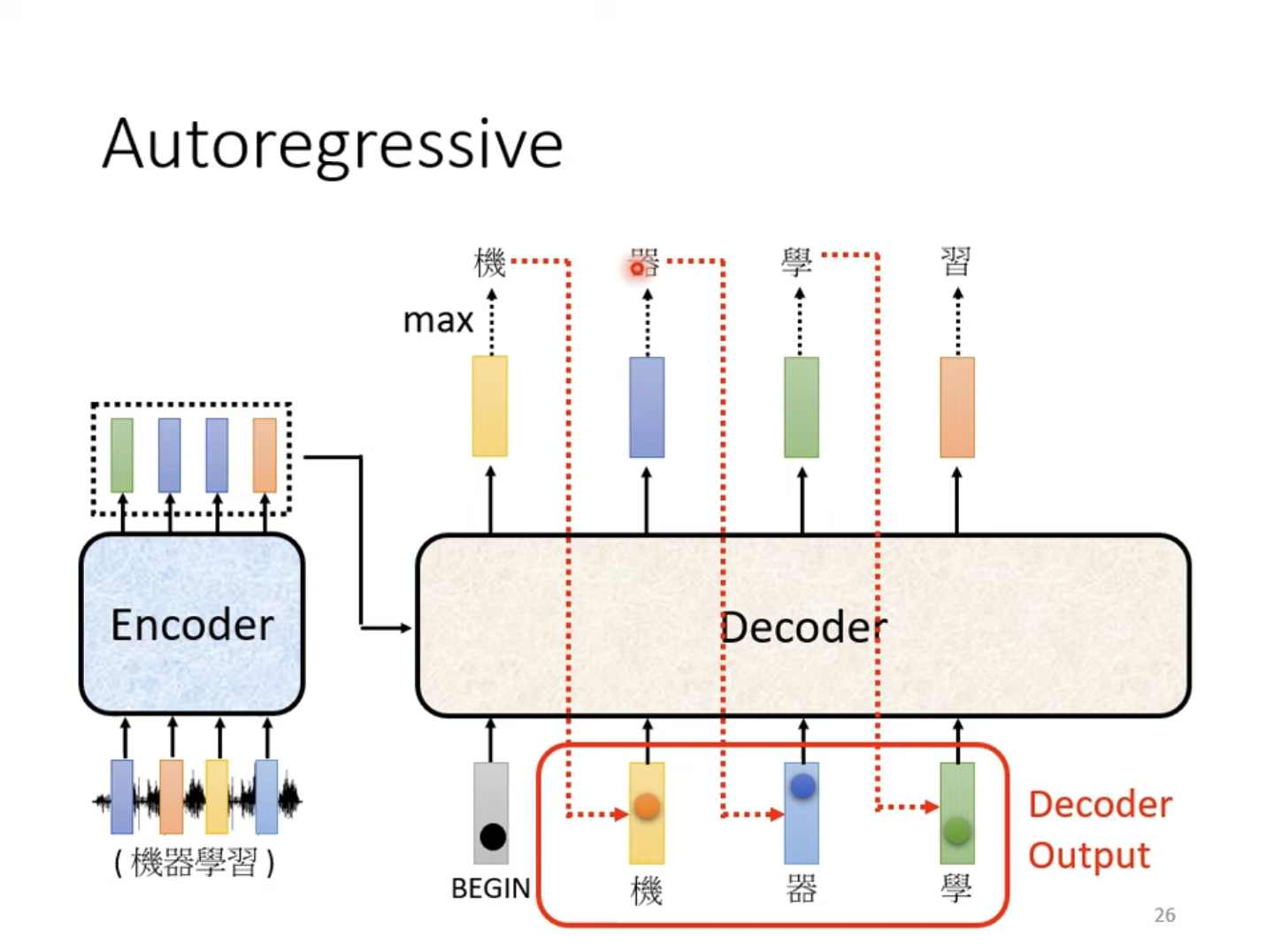
自回归描述的是,在产生“机”的输出后,将其作为Decoder的下一个输入输入Decoder,使其得出下一个输出,如此往复。代表着Decoder可能会产生错误的输出,但其会尝试在错误输出的基础上得出最终正确的结果。
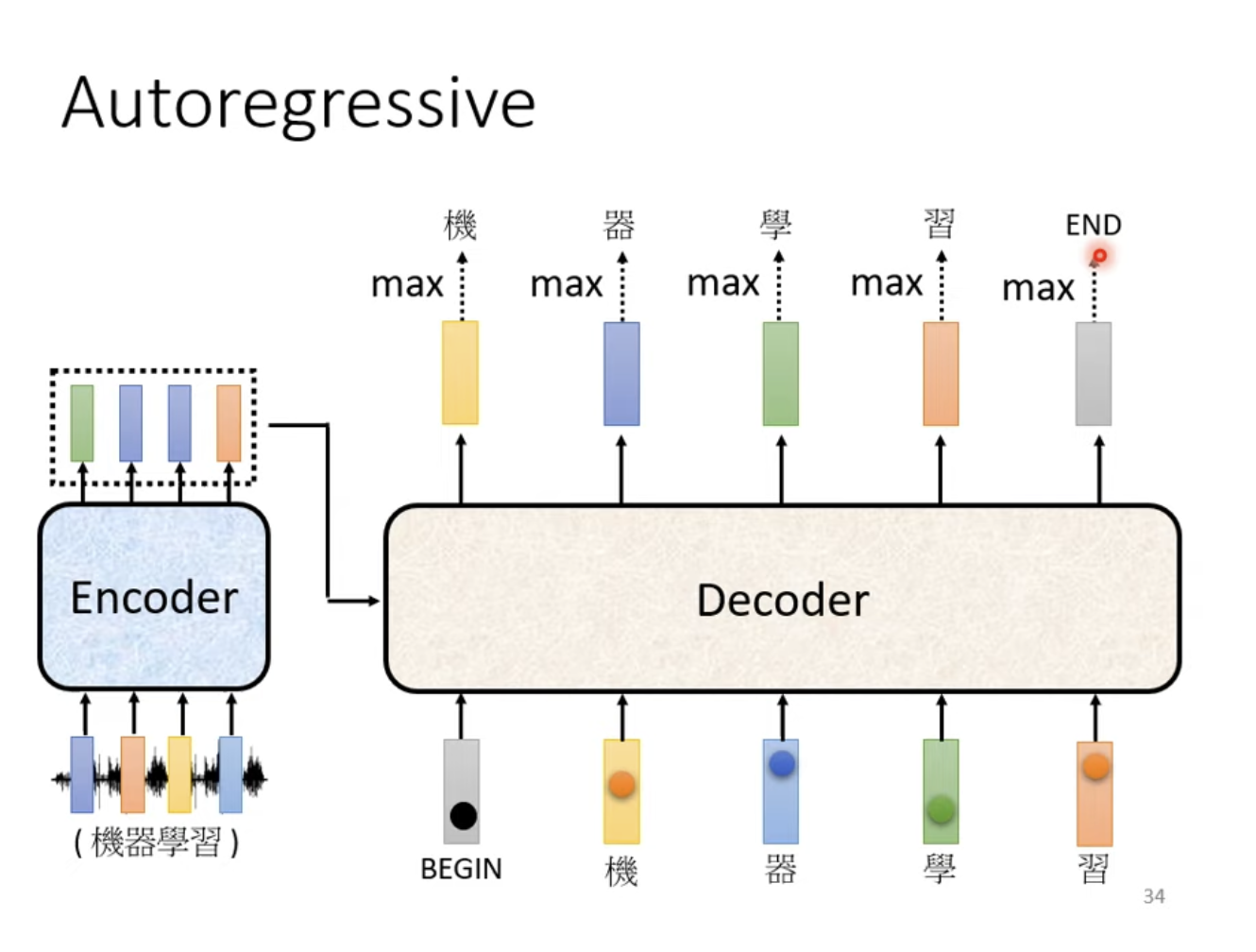
当输出产生特殊Token END时,输出结束。
2. Transformer Decoder - Masked Self-Attention
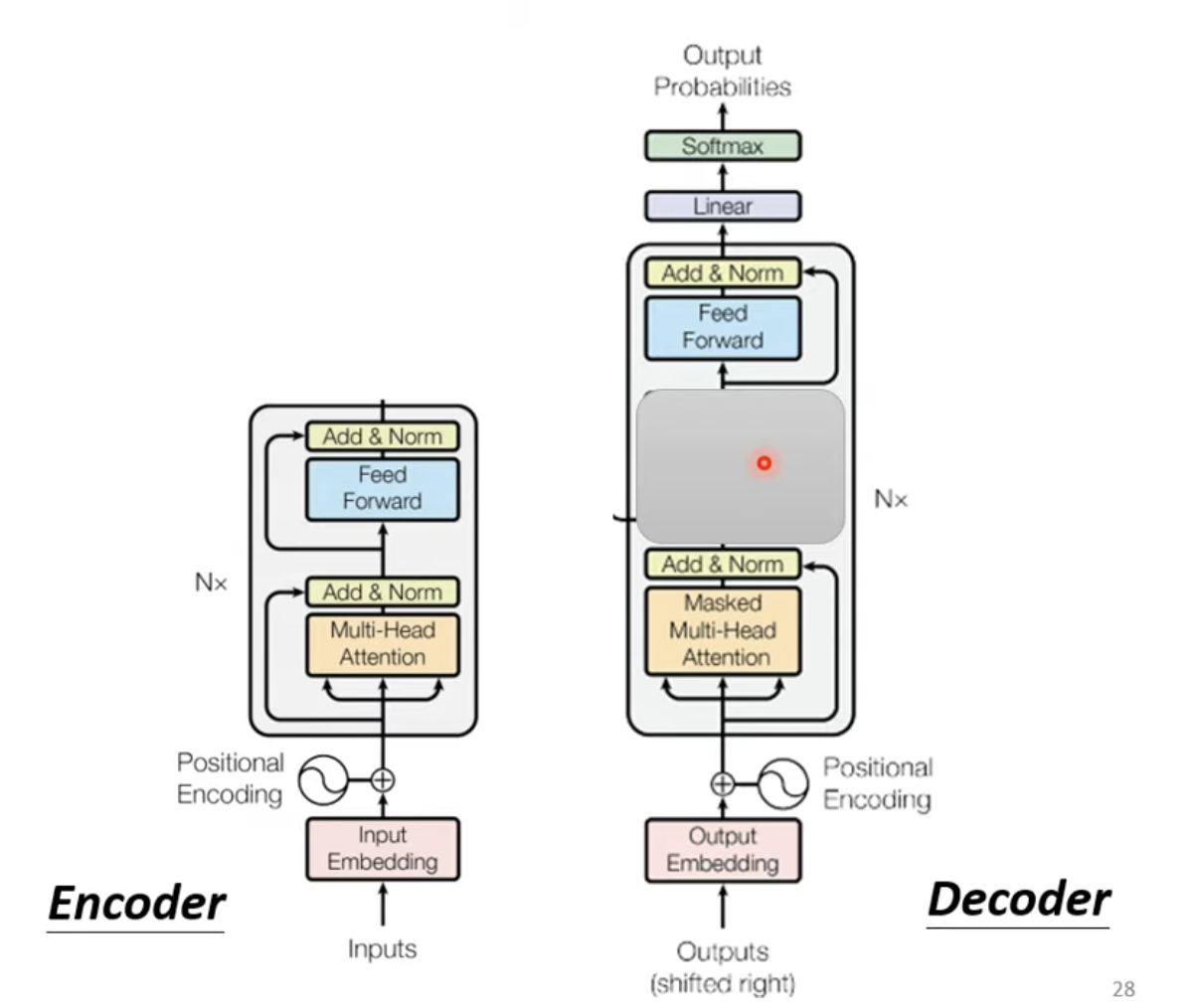
实际上,Transformer的Encoder和Decoder结构非常相似,遮掉中间的部分,区别主要就是Multi-Head Attenti
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2413
2413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









