






在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C++运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC++运行库或者安装的版本不完整,就可能会导致这些软件启动时报错,提示缺少库文件。
如果我们遇到关于文件在系统使用过程中提示缺少找不到的情况,如果文件是属于运行库文件的可以单独下载文件解决,但还是建议安装完整的运行库,可以尝试采用手动下载替换的方法解决问题!
方法1:使用软件工具免费下载 需要的文件,想要修复丢失文件,那就要下载一个好的文件,并放在指定的文件夹中(程序安装目录或系统目录),就可以解决问题了!
下面我们通过使用一款DLL修复工具免费下载需要的文件
下载地址1 我们可以通过优快云下载https://download.youkuaiyun.com/download/2508_90661607/90392235
下载地址2 直接下载https://download.youkuaiyun.com/download/2508_90661607/90392235
下载安装完成后,打开软件,然后点击界面左侧的“文件下载”,接着在软件界面右侧文本框中输入我们要下载的文件名,然后点击右边的下载按钮。
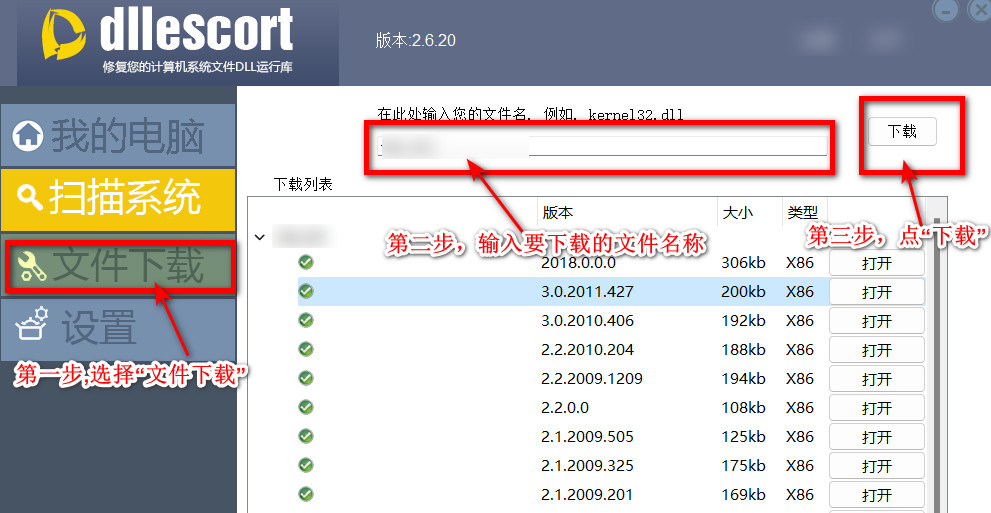
文件下载完成后,下方列表会有很多个不同版本的文件,这里所有文件都是免费可下载的,我们根据自己所需要的版本文件,点击右边的“打开”,这样就找到了下载的文件
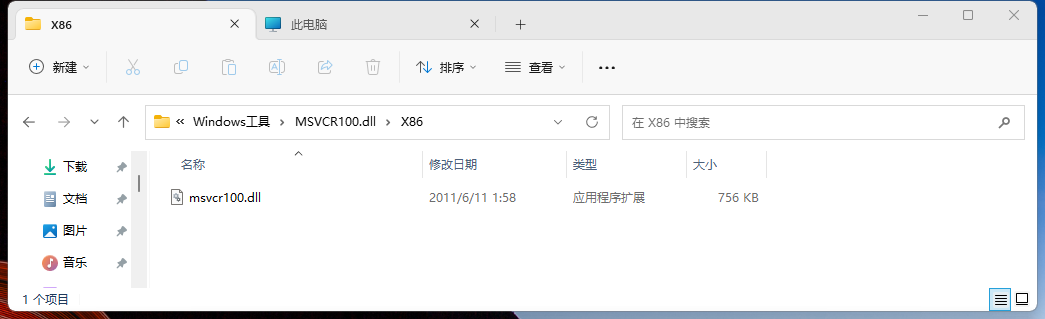
x86 表示32位文件:
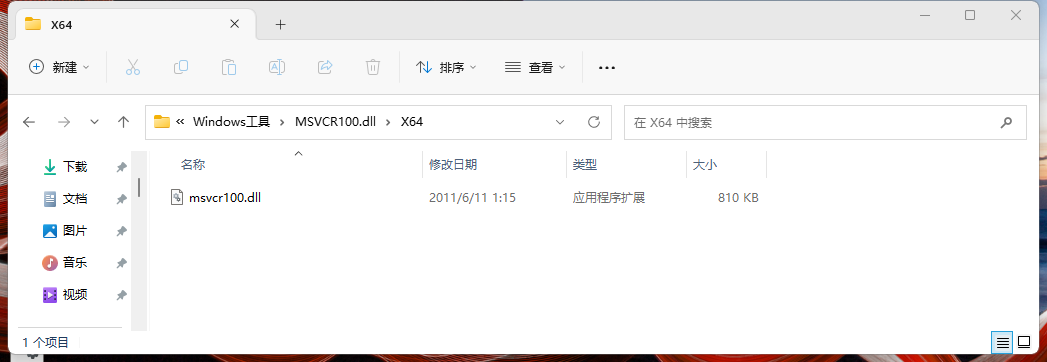
X64 表示64位文件:
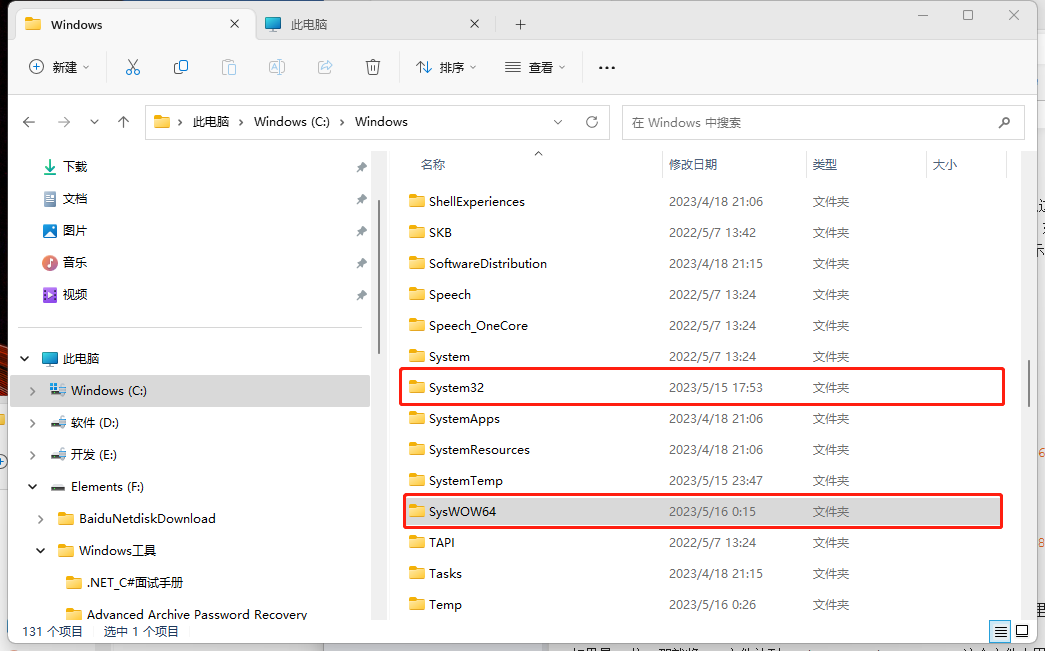
现在电脑基本上都是64位系统,那就将32位dll文件放到“C:\Windows\SysWOW64”这个文件夹里面
将64位文件,放到“C:\Windows\System32”这个文件夹里面
,如图所示:
另外还有一种情况需要注意!
另外还有一种情况需要注意!
另外还有一种情况需要注意!
“C:\Windows\SysWOW64” 有这个dll,但是“C:\Windows\System32” 没有
这个时候也需要把64位dll复制到“C:\Windows\System32”
确实有人遇到这种情况:
以上只是通用的运行库dll处理方式,如果你遇到缺失文件是第三方的软件文件,那么就需要下载到属于这个程序所匹配的版本的文件,然后将这个文件复制到这个程序的安装目录下才能解决问题。

















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









