



LangGraph代码实现(部分)
1. 条件入口点
条件⼊⼝点允许根据⾃定义逻辑从不同的节点开始。可以从虚拟的START节点使⽤add_conditional_edges来实现这⼀点。
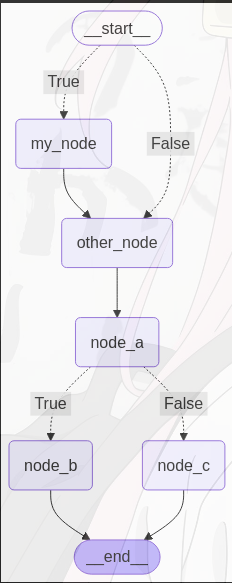
以下图为例,根据不同条件进入不同节点,参考代码如下:
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, START, END
# 初始化StateGrap,状态类型为字典
graph = StateGraph(dict)
# 定义节点
def my_node(state: dict, config: RunnableConfig):
print("In node: ", config["configurable"]["user_id"])
return {"results": f"你好, {state['input']}!"}
def other_node(state: dict):
return state
def node_a(state: dict):
return {"result": "这是node a"}
def node_b(state: dict):
return {"result": "这是node b"}
def node_c(state: dict):
return {"result": "这是node c"}
# 将节点添加到图中
graph.add_node("my_node", my_node)
graph.add_node("other_node", other_node)
graph.add_node("node_a", node_a)
graph.add_node("node_b", node_b)
graph.add_node("node_c", node_c)
# 普通边
graph.add_edge("my_node", "other_node")
graph.add_edge("other_node", "node_a")
# 条件边
graph.add_edge("my_node", "other_node")
graph.add_edge("other_node", "node_a")
# 条件边和条件路由函数
def routing_function(state: dict):
# 假设我们根据 state 中的某个键值来决定路由
# 如果 state 中有 'route_to_b' 且其值为 True,则路由到 node_b,否则路由到 node_c
return state.get('route_to_b', False)
graph.add_edge("node_b", END)
graph.add_edge("node_c", END)
# 条件边
graph.add_conditional_edges("node_a", routing_function, {True: "node_b", False: "node_c"})
# 条件入口点
def routing_my(state: dict):
return state.get("route_to_my", False)
# 条件入口点
graph.add_conditional_edges(START, routing_my, {True: "my_node", False: "other_node"})
# 编译图
app = graph.compile()
app.get_graph().draw_mermaid_png(output_file_path="./output/edges_case.png")
2. 分发
在 langgraph 里,“分发”(dispatching)指的是把消息或者任务分配到图中的不同节点去处理的过程。它是构建复杂工作流的关键机制,能够实现不同处理步骤之间的协调与交互。
分发一般分为两种,一种是静态分发,即在图构建阶段就明确规定了消息的流转路径。另一种是动态分发,动态分发允许根据消息的内容或者状态在运行时决定消息的流转路径。可以通过定义条件函数来实现动态分发,使用 add_conditional_edges 方法添加条件边。
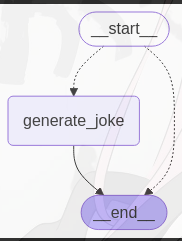
参考代码如下:
# 导入operator模块,用于后续操作
import operator
from typing import Annotated
from typing import TypedDict
from langgraph.graph import START, END, StateGraph
from langgraph.constants import Send
# 定义一个名为OverallState的TypedDict类
class OverallState(TypedDict):
# 创建一个名为subject的字符串列表
subject: list[str]
# 创建一个名为jokes的带有operator.add注解的字符串列表
jokes: Annotated[list[str], operator.add]
# 定义一个函数continue_to_jokes,接受一个OverallState类型的参数state
def continue_to_jokes(state: OverallState):
# 返回一个Send对象的列表,每个对象包含一个"generate_joke"的命令和对应主题的字典
return [Send("generate_joke", {"subject": s}) for s in state["subject"]]
# 创建一个StateGraph对象builder,传入OverallState类型
builder = StateGraph(OverallState)
# 添加一个名为"generate_joke"的节点,节点执行一个lambda函数,生成一个关于主题的笑话
builder.add_node("generate_joke", lambda state: {"jokes": [f"这是关于{state['subject']}的笑话"]})
# 添加一个条件边,从START节点到continue_to_jokes函数返回的节点
builder.add_conditional_edges(START, continue_to_jokes)
# 添加一条边,从"generate_joke"节点到END节点
builder.add_edge("generate_joke", END)
# 编译graph,生成最终的graph对象
graph = builder.compile()
# 调用graph对象,并传入包含两个主题的初始状态,结果是为每个主题生成一个笑话
res = graph.invoke({"subject": ["python", "java"]})
print(res)
graph_png = graph.get_graph().draw_mermaid_png()
with open("./output/send_case.png", "wb") as f:
f.write(graph_png)输出结果为:
{'subject': ['python', 'java'], 'jokes': ['这是关于python的笑话', '这是关于java的笑话']}3. checkpointer(检查点)
LangGraph 具有⼀个内置的持久化层,通过检查点实现。当将检查点与图形⼀起使⽤时,可以与该图形的状态进⾏交互。它允许在交互之间进⾏“记忆”。可以使⽤检查点创建线程并在图形执⾏后保存线程的状态。在重复的⼈类交互(例如对话)的情况下,任何后续消息都可以发送到该检查点,该检查点将保留对其以前消息的记忆。
许多 AI 应⽤程序需要内存来跨多个交互共享上下⽂。在 LangGraph 中,通过 检查点 为任何StateGraph 提供内存。
在创建任何 LangGraph ⼯作流时,可以通过以下⽅式设置它们以持久保存其状态:
- ⼀个 检查点,例如 MemorySaver,AsyncSqliteSaver
- 在编译图时调⽤ compile(checkpointer=my_checkpointer) 。
参考代码如下:
from langchain_community.chat_models import ChatTongyi
from langchain.schema.messages import HumanMessage, SystemMessage
llm = ChatTongyi(model='qwen-long',
top_p=0.8,
temperature=0.1,
api_key='自己申请的api'
)
llm.invoke("你好")注意,其中大模型以通义千问为例,api_key 需要自己前往阿里云百炼申请,过程在此不赘述。
输出结果如下:
AIMessage(content='你好!今天过得怎么样?', additional_kwargs={}, response_metadata={'model_name': 'qwen-long', 'finish_reason': 'stop', 'request_id': 'e00dbf09-bd2e-9075-9aac-2d8caf082871', 'token_usage': {'input_tokens': 1, 'output_tokens': 6, 'total_tokens': 7}}, id='run-04598d72-25b2-4c5e-8d53-524bea53533c-0')告诉大模型我的名字:
llm.invoke([HumanMessage(content="你好,我是李黑帅")])大模型回复:
AIMessage(content='你好,李黑帅!很高兴认识你。如果你有任何问题或需要帮助的地方,请随时告诉我!', additional_kwargs={}, response_metadata={'model_name': 'qwen-long', 'finish_reason': 'stop', 'request_id': '569bff35-550f-97b2-b4d6-a19209d2fe89', 'token_usage': {'input_tokens': 6, 'output_tokens': 21, 'total_tokens': 27}}, id='run-c543a323-d0bb-4b43-8c2a-23e677428d53-0')此时大模型知道了我的名字,测试一下大模型此时是否有记忆:
llm.invoke([HumanMessage(content="我的名字是什么?")])大模型回复如下,看得出来此时的大模型不具备记忆能力:
AIMessage(content='您还没有告诉我您的名字呢。如果您愿意,可以告诉我,我会记住它!', additional_kwargs={}, response_metadata={'model_name': 'qwen-long', 'finish_reason': 'stop', 'request_id': '3b735b88-6f4c-9c32-9c6a-a247f38ba5ae', 'token_usage': {'input_tokens': 4, 'output_tokens': 17, 'total_tokens': 21}}, id='run-4952eb3c-07e2-427e-8faa-62c8a4581de5-0')为了能让大模型有记忆,使用LangGraph的MemorySaver模块:
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import MessagesState, StateGraph
# 创建一个graph
workflow = StateGraph(state_schema=MessagesState)
# 定义一个函数,用于调用聊天模型
def call_chat_model(state: MessagesState):
response = llm.invoke(state["messages"])
return {"messages": response}
# 添加聊天模型节点
workflow.add_node("chat_model", call_chat_model)
workflow.add_edge(START, "chat_model")
workflow.add_edge("chat_model", END)
# 创建一个记忆模块
memory_saver = MemorySaver()
# 编译创建具有记忆模块的工作流
app = workflow.compile(checkpointer=memory_saver)
再定义一段工作流用于测试(注:“工作流”(workflow)指的是一个定义好的、有顺序的一系列步骤或操作,用于实现特定的目标或任务),
具体到下面这段代码中,工作流大致包含以下几个关键部分:
- 配置:通过
config字典来设置一些可配置的参数,比如这里设置了thread_id(线程 ID),这可能是用于标识特定的对话线程或会话,以便在后续处理中跟踪和管理相关信息。 - 输入:定义了
query变量(内容为 “你好,我是黑大帅”),并将其封装成一个HumanMessage对象,添加到input_messages列表中,作为工作流的输入信息,即用户的输入消息。 - 调用应用:使用
app.invoke方法来调用某个应用(app应该是一个预先定义好的对象,可能是一个对话系统或类似的应用),将输入消息input_messages和配置信息config传递给该应用进行处理。这里提到使用了MemorySaver,意味着对话内容会被保留下来,以便后续使用(比如记录对话历史等)。 - 输出处理:获取应用处理后的输出
output,其中output["messages"]包含了所有的历史信息,通过output["messages"][-1].pretty_print()来打印最后一条消息(即模型返回的消息),这是对输出结果的展示和处理步骤。
config = {"configurable": {"thread_id": "abc123"}} # 配置线程ID
query = "你好,我是李黑帅"
input_messages = [HumanMessage(content=query)]
# 由于使用了MemorySaver,对话内容会被保留
output = app.invoke(
{"messages": input_messages},
config=config
)
# output["messages"]包含所有的历史信息,打印最后一条消息(模型返回的消息)
output["messages"][-1].pretty_print()
大模型回复:
==================================[1m Ai Message [0m==================================
你好,李黑帅!很高兴认识你。如果你有任何问题或需要帮助的地方,请随时告诉我!再验证工作流的记忆功能:
query = "我叫什么?"
input_messages = [HumanMessage(content=query)]
output = app.invoke(
{"messages": input_messages},
config=config
)
output["messages"][-1].pretty_print()大模型回复:
==================================[1m Ai Message [0m==================================
你叫李黑帅呀!有什么特别的原因给你起这个名字吗?或者你想让我帮你记住别的名字?😊此时的大模型才算拥有了记忆功能。
值得注意的是,在不同线程下,工作流的记忆功能将不存在
LangGraph 中的不同线程问题
例如将线程id从123切换为234再次进行询问:
query = "我叫什么"
config = {
"configurable": {"thread_id": "abc234"}
}
input_messages = [HumanMessage(content=query)]
output = app.invoke(
{"messages": input_messages},
config=config
)
output["messages"][-1].pretty_print()此时大模型就没有线程123的记忆了:
==================================[1m Ai Message [0m==================================
您好,您没有告诉我您的名字,所以我无法知道您叫什么。您可以告诉我您的名字哦。查询资料可知,在 LangGraph 中,不同线程下工作流的记忆功能不存在,主要有以下原因:
1. 线程的独立性
- 线程是程序执行的独立单元,具有自己独立的栈空间和执行路径。在多线程环境下,每个线程都独立运行,它们之间的内存空间是相互隔离的。工作流的记忆功能通常依赖于特定的内存区域来存储对话历史、中间结果等信息。当工作流在不同线程中执行时,这些线程无法直接访问其他线程的内存空间,因此无法共享记忆信息,导致记忆功能在不同线程下失效。
2. 资源管理和隔离
- 为了保证系统的稳定性和可靠性,不同线程之间需要进行资源隔离。如果工作流的记忆功能在不同线程中共享,可能会导致资源竞争和数据不一致的问题。例如,多个线程同时访问和修改相同的记忆数据,可能会导致数据混乱,影响工作流的正常执行。通过将记忆功能限制在单个线程内,可以更好地管理资源,避免资源冲突和数据不一致性。
设置不同线程的原因如下:
1. 提高并发处理能力
- LangGraph 可能需要同时处理多个任务或请求,例如同时处理多个用户的对话。通过使用多线程,可以让不同的任务在不同的线程中并行执行,从而提高系统的并发处理能力,能够同时响应多个用户的请求,提高系统的整体性能和响应速度。
2. 实现异步操作
- 某些操作可能是耗时的,如网络请求、文件读取等。将这些操作放在单独的线程中执行,可以避免阻塞主线程,使其他操作能够继续进行。例如,在处理对话时,如果需要从外部数据源获取信息,可以在一个线程中进行网络请求,而主线程可以继续处理其他用户输入或进行其他逻辑处理,提高系统的响应性和用户体验。
3. 资源分配和管理
- 不同的任务可能对资源的需求不同,通过设置不同线程,可以根据任务的特点合理分配资源。例如,对于计算密集型任务,可以分配更多的 CPU 资源给相应的线程;对于 I/O 密集型任务,可以优化线程的 I/O 调度,提高资源的利用效率。这样可以更好地管理系统资源,确保各个任务都能得到适当的资源支持,从而提高整个系统的性能和稳定性。
知道了langgraph中的线程问题后,接下来尝试利用异步操作将上下文存储到数据库中。
注,以使用vscode和sqlite为例,要想显示数据库需要下载此插件:
实现代码如下:
# 导入 asyncio 模块,用于处理异步编程
import asyncio
# 从 langgraph.checkpoint.sqlite.aio 模块中导入 AsyncSqliteSaver 类,它用于异步保存检查点到 SQLite 数据库
# pip install langgraph.checkpoint.sqlite
from langgraph.checkpoint.sqlite.aio import AsyncSqliteSaver
# 从 langgraph.graph 模块中导入 StateGraph 类,它用于构建状态图
from langgraph.graph import StateGraph
async def main():
# 创建一个 StateGraph 对象,节点的值类型为 int
builder = StateGraph(int)
# 添加一个名为 "add_one" 的节点,该节点的功能是将输入值加 1
builder.add_node("add_one", lambda state: state + 1)
# 设置 "add_one" 节点为状态图的入口点
builder.set_entry_point("add_one")
# 设置 "add_one" 节点为状态图的结束点
builder.set_finish_point("add_one")
# 使用异步上下文管理器创建一个 AsyncSqliteSaver 对象,并连接到名为 "checkpoints.db" 的 SQLite 数据库
async with AsyncSqliteSaver.from_conn_string("checkpoints.db") as memory:
# 编译状态图,并使用 memory 作为检查点保存器
graph = builder.compile(checkpointer=memory)
# 创建一个异步调用状态图的协程,输入值为 1,并传入额外的配置参数
res = await graph.ainvoke(1, {"configurable": {"thread_id": "thread-1"}})
print(res)
# 使用 asyncio.run 运行 main() 协程
asyncio.create_task(main())打开checkpoints.db,可以看到已经成功存入:

4. 消息图
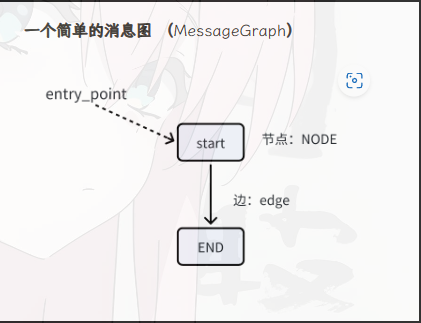
MessageGraph是Graph的一个特例,Graph的State类是一个消息列表,主要用于聊天型Agent。
还是以通义千问作为示例模型:
from langchain_community.chat_models import ChatTongyi
model = ChatTongyi(model='qwen-long',
top_p=0.8,
temperature=0.1,
api_key='自己的api')构建一个简单的消息处理图,定义消息处理流程,然后使用这个图来处理用户输入的消息,并打印处理结果。
from langgraph.graph import MessageGraph, END
from langchain.schema import HumanMessage
# 定义一个消息图
graph = MessageGraph()
# 定义一个节点
graph.add_node("start", model)
# 定义一个从 start 到 END 的边
graph.add_edge("start", END)
# 定义逻辑入口
graph.set_entry_point("start")
# 由图生成一个 runnable
runnable = graph.compile()
res = runnable.invoke(HumanMessage("1加1等于几?"))
print(res)打印结果为:
[HumanMessage(content='1加1等于几?', additional_kwargs={}, response_metadata={}, id='cee5df71-8040-4144-bb2c-483813455ebe'), AIMessage(content='1加1等于2,答案是:\n\n**boxed{2}**', additional_kwargs={}, response_metadata={'model_name': 'qwen-long', 'finish_reason': 'stop', 'request_id': '1d044ac3-0ec8-999b-9280-b5e141a8c0f5', 'token_usage': {'input_tokens': 6, 'output_tokens': 15, 'total_tokens': 21}}, id='run-17d2a0c2-21cc-4458-ac0d-5124dae7ba65-0')]再创建一个简单的消息图,这次除了HumanMessage之外再加入AIMessage和ToolMessage,参考代码如下:
# 导⼊ AIMessage、HumanMessage 和 ToolMessage 类,⽤于表示不同类型的消息
from langchain_core.messages import AIMessage, HumanMessage, ToolMessage
from langgraph.graph.message import MessageGraph
# 创建⼀个新的 MessageGraph 实例
builder = MessageGraph()
# 向消息图中添加⼀个节点,节点名称为 "chatbot",该节点执⾏的函数接收状态并返回⼀个包含 AI 消息的列表
# AI 消息内容为 "Hello!",并包含⼀个⼯具调⽤,⼯具名称为 "search",ID 为 "123",参数为 {"query": "X"}
builder.add_node(
"chatbot",
lambda state: [
AIMessage(
content="Hello!",
tool_calls=[{"name": "search", "id": "123", "args": {"query": "X"}}]
)
]
)
# 向消息图中添加另⼀个节点,节点名称为 "search",该节点执⾏的函数接收状态并返回⼀个包含⼯具消息的列表
# ⼯具消息内容为 "Searching...",⼯具调⽤ ID 为 "123"
builder.add_node(
"search",
lambda statte: [
ToolMessage(
content="Searching...",
tool_call_id="123"
)
]
)
# 设置消息图的⼊⼝点为 "chatbot" 节点
builder.set_entry_point("chatbot")
# 添加⼀条边,从 "chatbot" 节点到 "search" 节点
builder.add_edge("chatbot", "search")
# 设置消息图的结束点为 "search" 节点
builder.set_finish_point("search")
# 编译消息图并调⽤其 invoke ⽅法,传⼊⼀个包含⽤户消息的列表,返回包含所有消息的字典
result = builder.compile().invoke([HumanMessage(content="Hi there. Can you search for X?")])
print(result)输出结果为:
[HumanMessage(content='Hi there. Can you search for X?', additional_kwargs={}, response_metadata={}, id='d493005c-8bad-4223-9fd9-016ec60fdd9b'), AIMessage(content='Hello!', additional_kwargs={}, response_metadata={}, id='24050dd8-6507-42d3-89d3-761eba8db917', tool_calls=[{'name': 'search', 'args': {'query': 'X'}, 'id': '123', 'type': 'tool_call'}]), ToolMessage(content='Searching...', id='c8cbb4f0-fc61-40b8-afa8-f79ca85e5a6e', tool_call_id='123')]创建自定义工具
本文使用 @tool 装饰器的方法来实现自定义工具,在 langchain 里,@tool 装饰器一般用于定义可以被语言模型调用的工具函数。
其余使用方式可参考同站另一位博主的文章:LangChain自定义工具调用实战指南
以实现乘法为例,大致流程如下图所示:
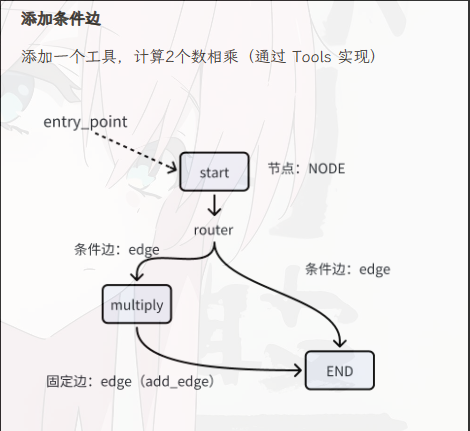
代码实现:
import json
from typing import List
from langchain_core.messages import HumanMessage, BaseMessage, ToolMessage
from langgraph.graph import END, MessageGraph
from langchain_core.tools import tool
from langchain_core.utils.function_calling import convert_to_openai_tool
from langchain_community.llms import Tongyi
from langchain_community.chat_models import ChatTongyi
if __name__ == '__main__':
# 裁判
model = ChatTongyi(
model='qwen-long',
top_p=0.8,
temperature=0.1,
api_key='我的api'
)
# 定义一个乘法工具
@tool
def multiply(frist_number: int, second_number: int):
"""将两个数相乘"""
return frist_number * second_number
#将工具和模型绑定
model_with_tools = model.bind(tools=[convert_to_openai_tool(multiply)])
# 定义一个消息图
graph = MessageGraph()
#定义图的入口
def invoke_model(state: List[BaseMessage]):
# 调用模型并返回结果
return model_with_tools.invoke(state)
# 定义一个节点
graph.add_node("start", invoke_model)
#定义调用工具节点
def invoke_tool(state: List[BaseMessage]):
tool_calls = state[-1].additional_kwargs.get("tool_calls", [])
multiply_call = None
# 获得调用参数
for tool_call in tool_calls:
if tool_call.get("function").get("name") == "multiply":
multiply_call = tool_call
if multiply_call is None:
return Exception("No adder input found.")
# 调用工具:2个数相乘
res = multiply.invoke(
json.loads(multiply_call.get("function").get("arguments"))
)
# 返回 工具消息
return ToolMessage(
tool_call_id=multiply_call.get("id"),
content="结果等于:"+str(res)
)
graph.add_node("multiply", invoke_tool)
graph.add_edge("multiply", END)
# 定义逻辑入口
graph.set_entry_point("start")
# 定义分支选择函数 router
def router(state: List[BaseMessage]):
tool_calls = state[-1].additional_kwargs.get("tool_calls", [])
if len(tool_calls):
return "multiply"
else:
return "end"
# 增加条件边
graph.add_conditional_edges("start", router, {
"multiply": "multiply",
"end": END
})
# 由图生成一个 runnable
runnable = graph.compile()
res = runnable.invoke(
HumanMessage("65乘以25等于多少?")
)
print(res)
res_02 = runnable.invoke(
HumanMessage("美国总统是谁?")
)
print(res_02)生成结果为:
[HumanMessage(content='65乘以25等于多少?', additional_kwargs={}, response_metadata={}, id='e3f5ded4-9545-4ab5-be34-0cbd16e57a22'), AIMessage(content='', additional_kwargs={'tool_calls': [{'function': {'name': 'multiply', 'arguments': '{"frist_number": 65, "second_number": 25}'}, 'index': 0, 'id': 'call_fb4d44dfa2b34df09074c5', 'type': 'function'}]}, response_metadata={'model_name': 'qwen-long', 'finish_reason': 'tool_calls', 'request_id': 'a0a5eba1-202e-9742-b5fe-1c644bd50faa', 'token_usage': {'input_tokens': 9, 'output_tokens': 27, 'total_tokens': 36}}, id='run-12b5d89c-050b-4cff-a119-c393828a2778-0', tool_calls=[{'name': 'multiply', 'args': {'frist_number': 65, 'second_number': 25}, 'id': 'call_fb4d44dfa2b34df09074c5', 'type': 'tool_call'}]), ToolMessage(content='结果等于:1625', id='0cbc75df-1adb-4ca2-802b-9ef71e3e2de8', tool_call_id='call_fb4d44dfa2b34df09074c5')]
[HumanMessage(content='美国总统是谁?', additional_kwargs={}, response_metadata={}, id='18e8a194-13a3-494c-9082-e4457c456ce2'), AIMessage(content='我是一个数学助手,无法提供关于美国总统的信息。您可以查询最新的资料,当前的美国总统是乔·拜登。', additional_kwargs={}, response_metadata={'model_name': 'qwen-long', 'finish_reason': 'stop', 'request_id': '0d138ad3-b9f8-9ea3-aadc-23f587094513', 'token_usage': {'input_tokens': 3, 'output_tokens': 24, 'total_tokens': 27}}, id='run-f63f3d3c-466b-4f0c-b6cc-f3f549ad8343-0')]可以看到前一个问题调用了乘法工具,ToolMessage输出了结果为1625,后一个则没有调用该工具。

















 3482
3482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









