







源码
对PairRDD中相同的Key值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。和aggregate函数类似,aggregateByKey返回值的类型不需要和RDD中value的类型一致。因为aggregateByKey是对相同Key中的值进行聚合操作,所以aggregateByKey’函数最终返回的类型还是PairRDD,对应的结果是Key和聚合后的值,而aggregate函数直接返回的是非RDD的结果
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(
seqOp: (U, V) => U,//用于合并分区内的值
combOp: (U, U) => U //用于合并分区间的值
): RDD[(K, U)] = self.withScope {
// 将zeroValue序列化为字节数组,以便我们可以在每个键上获得它的新克隆
val zeroBuffer = SparkEnv.get.serializer.newInstance().serialize(zeroValue)
val zeroArray = new Array[Byte](zeroBuffer.limit)
zeroBuffer.get(zeroArray)
lazy val cachedSerializer = SparkEnv.get.serializer.newInstance()
val createZero = () => cachedSerializer.deserialize[U](ByteBuffer.wrap(zeroArray))
// We will clean the combiner closure later in `combineByKey`
val cleanedSeqOp = self.context.clean(seqOp)
combineByKeyWithClassTag[U](
(v: V) => cleanedSeqOp(createZero(), v),
cleanedSeqOp,
combOp,
partitioner)
}
主要代码:
combineByKeyWithClassTag方法,传入的cleanedSeqOp方法(其实是用户传入的seqOp方法)作用是处理分区内的数据,发生在mapside,去处理zeroValue和value。而combOp作用是处理分区间的数据,发生在reduce阶段
关于
zeroValue:
根据代码可以看到将传入的zeroValue传入到cleanedSeqOp方法内,因此zeroValue仅作用于分区内,分区间是不起作用的
combineByKeyWithClassTag底层调用的是Aggregator方法,用法的话可以参考GroupByKey的实现,
链接:http://t.csdn.cn/OcAzT
示例
val rdd1: RDD[(String, Int)] = sc.parallelize(List(
"spark", "hadoop", "hive", "spark",
"spark", "flink", "hive", "spark",
"kafka", "kafka", "kafka", "kafka",
"hadoop", "flink", "hive", "flink"
),4).map((_, 1))
rdd1.aggregateByKey(10)(math.max,_+_)
.mapPartitionsWithIndex((index,iter)=>{
iter.map((index,_))
}).foreach(println)
(2,(kafka,10))
(1,(spark,20))
(1,(hadoop,20))
(0,(hive,30))
(0,(flink,20))
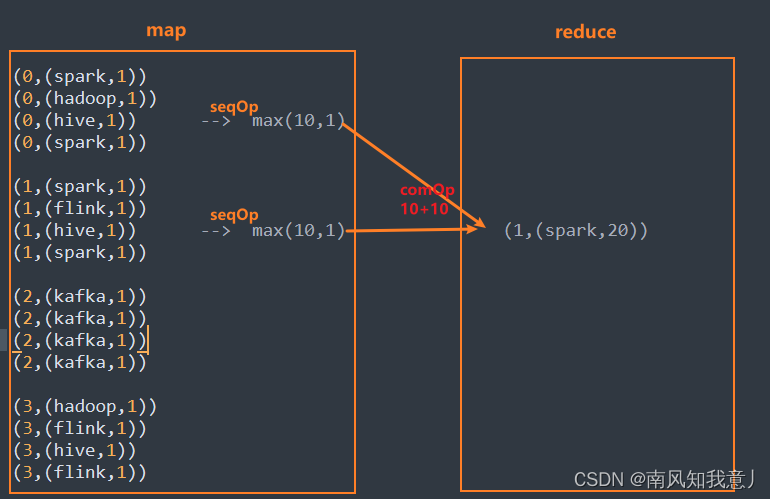
- 依“Spark”为例,解析下算子的运行轨迹

















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









