




1 核心理念演进:从“分工协作”到“一体统一”
在大数据技术发展的历程中,数据处理范式经历了从离线批处理到实时流处理,再到追求两者统一的演进。Lambda架构和Kappa架构正是这一演进过程中的两个标志性设计思想。
Lambda架构由Nathan Marz提出,其核心设计哲学是“分工与冗余”。它承认当时(2010年代初期)的单一技术栈无法同时完美解决海量历史数据的高准确性处理和实时数据的低延迟处理这两个矛盾的需求。因此,它选择用两套系统并行:一套强大的批处理系统(如Hadoop MapReduce, Spark)保证准确性,一套快速的流处理系统(如Storm, Flink)保证实时性,最后合并结果。这是一种务实但复杂的“组合拳”。
Kappa架构则由Jay Kreps提出,作为对Lambda架构的反思与简化。其核心理念是“统一与简化”。它质疑维护两套逻辑一致的系统的必要性,主张利用现代流处理系统能力的增强(如高吞吐、精确一次语义、状态管理),让一个流处理框架承担所有数据处理工作,无论是实时数据还是历史重算。这代表了技术成熟后,对系统架构简洁性和维护性的追求。
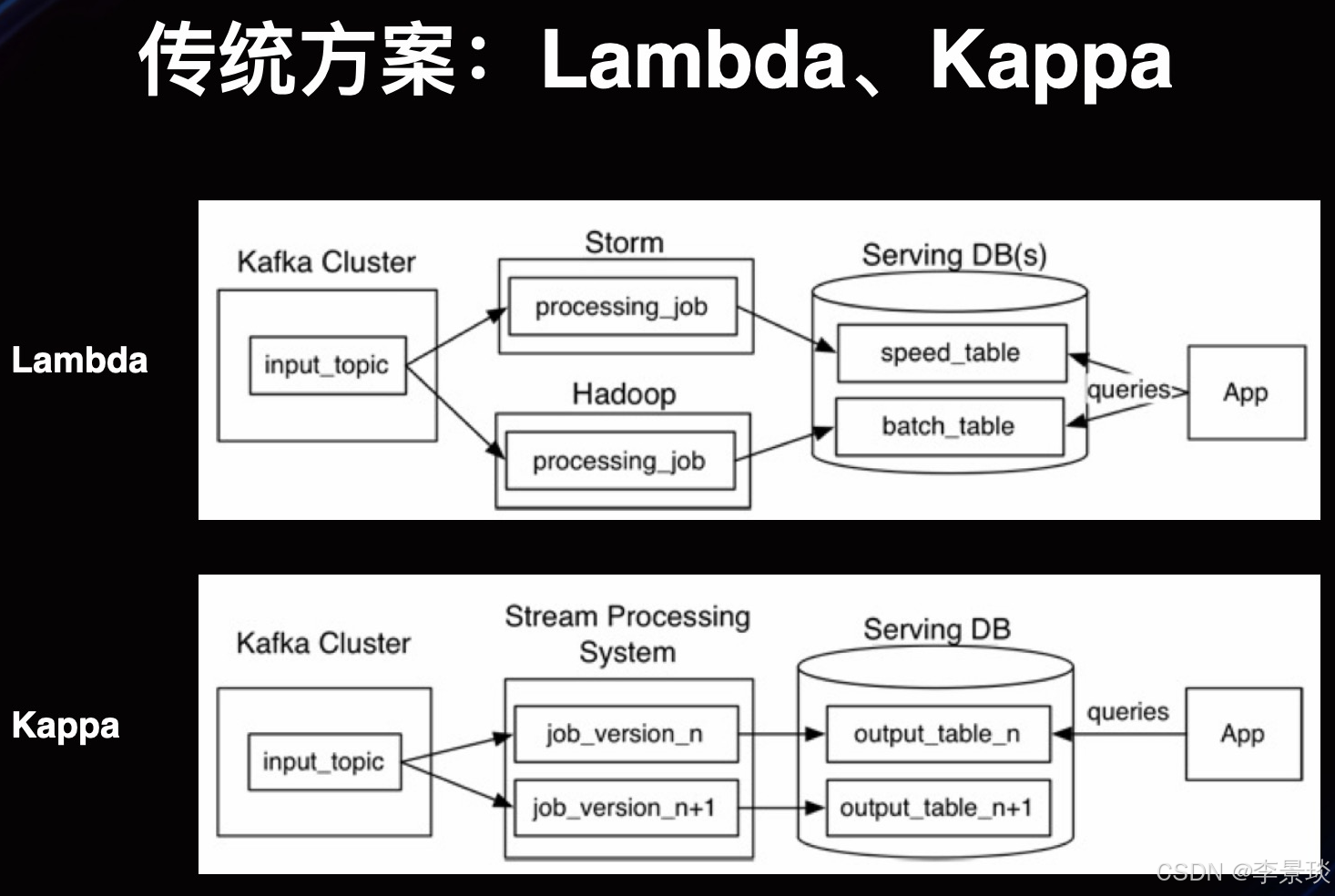
两种架构的关键差异总结如下:
| 维度 | Lambda架构 | Kappa架构 | 对比解析与启示 |
|---|---|---|---|
| 核心思想 | 批流分离,合并查询:通过独立的速度层和批处理层分别处理实时与历史数据,在服务层合并。 | 流处理统一:所有数据(实时与历史)均通过流处理管道处理,历史数据通过流重放处理。 | Lambda是空间换时间的冗余设计;Kappa是追求逻辑统一的简约设计。 |
| 架构复杂度 | 高。需维护两套系统(批处理、流处理)和两套业务逻辑代码,开发、测试、运维成本高。 | 低。只需维护一套流处理系统和一套代码,架构简洁。 | 复杂性是Lambda的主要痛点,而简化是Kappa的主要驱动力。 |
| 数据一致性 | 最终一致。速度层的实时结果与批处理层的精准结果可能存在短期不一致,最终被批处理结果覆盖。 | 强一致。同一套逻辑处理所有数据,天然避免了结果不一致问题。 | Lambda需要容忍短暂的数据口径差异;Kappa在逻辑层面保证一致性。 |
| 资源开销 | 存储开销小,计算开销大。只需保存一份查询结果,但批处理和流处理两套计算集群需持续运行。 | 存储开销大,计算开销弹性。需存储用于重放的原始日志(如Kafka多日数据),但计算资源仅在需要时进行全量重算。 | Lambda长期占用大量计算资源;Kappa将成本转移至存储,计算可按需启动。 |
| 主要挑战 | 1. 两套系统结果不一致 2. 系统复杂性高 3. 批量计算时间窗口压力大 | 1. 历史数据重处理吞吐压力 2. 长时间状态管理的复杂度 3. 对消息队列存储周期和吞吐要求极高 | Lambda的挑战在于“人”(维护复杂),Kappa的挑战在于“技术”(重算能力)。 |
| 典型技术栈 | 批处理层:Hadoop (HDFS, MapReduce)、Spark 速度层:Storm, Flink, Spark Streaming 服务层:HBase, Cassandra, RDBMS | 流存储:Kafka (核心), Pulsar 流计算:Flink (主流), Samza, Storm 存储/服务:Kafka自身、HBase、Druid、ClickHouse | Lambda栈是异构的;Kappa栈以高性能流式组件为核心。 |
| 适用场景 | 1. 对历史数据准确性要求极高的场景(如财报、合规审计)。 2. 批处理逻辑过于复杂或沉重,难以用流式模型实现。 3. 技术栈已固化,流处理引擎能力不足的遗留系统。 | 1. 实时性要求为首要的场景(如实时风控、监控告警)。 2. 业务逻辑以实时事件驱动为主,且可流式表达。 3. 团队希望简化技术栈,降低维护成本。 | 选择常是业务需求与技术债务的权衡,而非单纯的技术优劣。 |
2 Lambda架构:经典三层架构深度拆解
2.1 架构组成与数据流
Lambda架构如同一个分工明确的工厂流水线,其数据流动清晰而严格:
-
所有数据首先被持久化写入不可变的主数据集(如HDFS),这是数据的“黄金副本”和批处理层的基础。
-
批处理层 使用MapReduce、Spark等引擎,周期性(如每天)对主数据集进行全量计算,生成精准的批处理视图,送入服务层。
-
速度层 同时处理实时数据流,使用Storm、Flink等引擎生成近似的实时视图,也送入服务层。
-
服务层 接受查询请求,合并批处理视图(高准确、高延迟)和实时视图(低延迟、近似),返回最终结果。当新的批处理视图就绪后,会覆盖旧的实时视图。
2.2 关键组件原理与Java技术栈实现
以下代码示例展示了如何使用Java生态典型组件构建一个简化的Lambda架构核心链路,实现用户行为计数。
a) 数据入口与主数据集 (HDFS)
所有原始用户行为日志被写入HDFS,形成不可变的数据基础。
java
// 简化的日志写入HDFS示例 (使用Hadoop Java API)
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path("/lambda/master_data/user_events/date=2025-12-01/log.json");
// 假设event是JSON格式的用户行为日志
FSDataOutputStream out = fs.create(path);
out.writeUTF(event.toString());
out.close();
b) 批处理层 (Apache Spark)
Spark作业夜间启动,读取HDFS上全天数据,进行全量精准计算。
java
// Spark Batch Job: 计算每日各页面浏览量(PV)
public class DailyPvBatchJob {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("DailyPVBatch").getOrCreate();
// 从HDFS读取当日主数据集
Dataset<Row> masterData = spark.read().json("hdfs:///lambda/master_data/user_events/date=2025-12-01/*.json");
// 精确的批处理计算
Dataset<Row> dailyPv = masterData
.filter("eventType = 'page_view'")
.groupBy("pageId")
.agg(count("*").as("daily_pv")); // 全量精确统计
// 将批处理视图写入服务层数据库(HBase)
dailyPv.write().mode(SaveMode.Overwrite)
.format("org.apache.phoenix.spark")
.option("table", "PAGE_PV_VIEW")
.option("zkUrl", "zk-server:2181")
.save();
}
}
c) 速度层 (Apache Flink)
Flink作业实时消费Kafka中的用户行为流,生成实时计数。
java
// Flink Streaming Job: 实时计算页面浏览量
public class RealtimePvSpeedJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从Kafka消费实时事件流
DataStream<UserEvent> eventStream = env
.addSource(new FlinkKafkaConsumer<>("user-events", new UserEventSchema(), properties))
.assignTimestampsAndWatermarks(...);
// 实时流处理计算 (这里使用滚动窗口,每10秒输出一次近似结果)
DataStream<Tuple2<String, Long>> realtimePv = eventStream
.filter(e -> e.getEventType().equals("page_view"))
.keyBy(UserEvent::getPageId)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction<UserEvent, Tuple2<String, Long>, String, TimeWindow>() {
@Override
public void process(String pageId, Context ctx, Iterable<UserEvent> events, Collector<Tuple2<String, Long>> out) {
long count = 0L;
for (UserEvent e : events) { count++; }
out.collect(new Tuple2<>(pageId, count));
}
});
// 实时视图写入HBase (可通过Phoenix SQL或HBase API)
realtimePv.addSink(new HBaseSinkFunction());
env.execute("Realtime PV Speed Layer");
}
}
d) 服务层合并查询 (Apache Phoenix on HBase)
服务层通过Phoenix查询HBase,它存储了两张表:PAGE_PV_VIEW(批处理视图)和PAGE_PV_REALTIME(实时视图)。应用查询时,Phoenix通过SQL视图或自定义函数合并两者。
java
// 通过Phoenix JDBC进行合并查询
public class ServingLayerQuery {
public static void main(String[] args) throws SQLException {
Connection conn = DriverManager.getConnection("jdbc:phoenix:zk-server:2181");
// 创建一个视图或直接执行合并查询SQL
// 假设批处理视图表为 BATCH_PV, 实时增量表为 REALTIME_PV_DELTA
String mergeSql =
"SELECT page_id, " +
" batch_pv + COALESCE(realtime_delta, 0) AS total_pv " + // 合并逻辑
"FROM BATCH_PV b " +
"LEFT JOIN REALTIME_PV_DELTA r ON b.page_id = r.page_id";
PreparedStatement stmt = conn.prepareStatement(mergeSql);
ResultSet rs = stmt.executeQuery();
// 返回最终结果给应用
while (rs.next()) {
System.out.println("Page: " + rs.getString("page_id") + ", Total PV: " + rs.getLong("total_pv"));
}
}
}
2.3 底层框架应用
Lambda架构是早期大数据组件的自然组合。Hadoop(HDFS+YARN) 和 Spark 是批处理层的绝对主力,负责海量、高吞吐的离线计算。HBase 作为高并发随机读写的NoSQL数据库,是服务层存储视图的理想选择。而 Apache Phoenix 通过提供标准的SQL查询层,极大简化了对HBase中数据的访问,是服务层对外提供查询能力的关键组件。
3 Kappa架构:流处理统一架构深度解析
3.1 架构组成与核心机制
Kappa架构可以看作一个高效且自洽的“流处理流水线”:
-
数据采集与存储:所有数据,无论是实时的还是用于重算的历史数据,都被作为事件流摄入一个支持高持久化、可重播的日志系统(通常是Apache Kafka)。Kafka需要配置足够长的数据保留时间(例如7天、30天),以满足重算需求。
-
流处理计算:Apache Flink 作为核心计算引擎,持续消费Kafka中的事件流进行计算,并输出结果到下游的存储或直接服务。
-
历史数据重算:这是Kappa架构区别于Lambda的关键。当业务逻辑变更或需要全量重算时,启动一个新的Flink作业实例,将其消费位点重置到Kafka日志的起始点(或某个历史时间点),然后像处理实时流一样全速重放历史数据。新作业输出到新的结果表。当新作业的处理进度追上实时流后,将查询流量切换到新表,并停止旧作业。
3.2 关键组件原理与Java技术栈实现
以下展示一个完整的、基于Java的Kappa架构实现,用于实时用户会话分析。
a) 数据入口与持久化日志 (Apache Kafka)
所有用户事件被发送到Kafka主题,并保留7天。
java
// Kafka Producer: 发送用户事件
public class UserEventProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-server:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 设置数据保留时间为7天,以供重算
// 此配置通常在Kafka Broker的server.properties中设置:log.retention.hours=168
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
UserEvent event = new UserEvent(userId, "click", System.currentTimeMillis(), "{...}");
ProducerRecord<String, String> record = new ProducerRecord<>("user_events", event.getUserId(), event.toJson());
producer.send(record);
producer.close();
}
}
b) 核心流处理 (Apache Flink)
Flink作业实时处理Kafka流,维护用户会话状态,并输出实时会话摘要。
java
// Flink Streaming Job: 实时用户会话分析
public class UserSessionAnalysisJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(60000); // 启用检查点,保证精确一次语义
// 1. 从Kafka消费数据流
DataStream<UserEvent> eventStream = env
.addSource(new FlinkKafkaConsumer<>(
"user_events",
new JSONKeyValueDeserializationSchema(),
properties))
.assignTimestampsAndWatermarks(WatermarkStrategy
.<UserEvent>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event, ts) -> event.getTimestamp()));
// 2. 定义会话窗口(基于事件时间,会话间隔超时30分钟)
DataStream<UserSession> sessionStream = eventStream
.keyBy(UserEvent::getUserId)
.window(EventTimeSessionWindows.withGap(Time.minutes(30)))
.aggregate(new SessionAggregator(), new SessionWindowFunction());
// 3. 将会话结果输出到外部存储(如Kafka另一个主题、或HBase)
sessionStream.addSink(new KafkaProducerSink<>("user_sessions_output", new SessionSchema()));
env.execute("Real-time User Session Analysis");
}
// 自定义聚合器,计算会话内的指标
static class SessionAggregator implements AggregateFunction<UserEvent, SessionAccumulator, SessionSummary> {
@Override
public SessionAccumulator createAccumulator() { return new SessionAccumulator(); }
@Override
public SessionAccumulator add(UserEvent value, SessionAccumulator accumulator) {
accumulator.addEvent(value);
return accumulator;
}
@Override
public SessionSummary getResult(SessionAccumulator accumulator) {
return accumulator.getSummary();
}
@Override
public SessionAccumulator merge(SessionAccumulator a, SessionAccumulator b) {
return a.merge(b);
}
}
}
c) 历史数据全量重算
当需要修改会话超时时间(如从30分钟改为15分钟)时,Kappa架构的重算流程启动。
-
部署新版本作业:将上述
UserSessionAnalysisJob代码中的withGap(Time.minutes(30))改为Time.minutes(15),打包为新版本JAR。 -
启动重算作业:启动一个新的Flink作业,该作业的
FlinkKafkaConsumer配置从最早偏移量(setStartFromEarliest())开始消费。java
FlinkKafkaConsumer<UserEvent> consumer = new FlinkKafkaConsumer<>("user_events", ..., properties); consumer.setStartFromEarliest(); // 关键:从Kafka中最早的数据开始重放 -
输出到新表:让新作业将结果输出到一个新的Kafka主题(如
user_sessions_output_v2)或新的HBase表中,避免与线上实时作业冲突。 -
切换与清理:监控新作业的处理进度。当它追赶到实时数据的尾部时:
-
将下游所有消费
user_sessions_output的应用,切换到消费user_sessions_output_v2。 -
停止旧版本的
UserSessionAnalysisJob。 -
可择机删除旧的输出表(此步可选)。
-
3.3 底层框架应用
Kappa架构的流行与Apache Kafka和Apache Flink的成熟密不可分。Kafka 不再仅仅是消息队列,更是 “持久化日志” 和 “流式数据存储” 的核心,其高吞吐、可持久化和分区顺序性为数据重放提供了基础。Flink 凭借其精确一次(Exactly-Once)状态一致性保证、强大的状态管理能力和高吞吐低延迟的流处理性能,成为实现Kappa架构中“统一处理层”的理想选择。Flink的Savepoint功能也为作业逻辑升级和重算提供了可靠的技术支撑。
4 架构选型指南与未来趋势
4.1 如何选择:业务场景与技术考量
没有最好的架构,只有最合适的架构。选择应基于你的核心业务需求和技术现状:
-
选择Lambda架构,当:
-
业务对历史数据的计算准确性有极端要求,且计算逻辑复杂(如复杂的机器学习模型训练),难以在流式计算中高效实现。
-
历史批处理任务已非常稳定,而实时需求是新增长的,推倒重来成本过高。
-
实时性要求为分钟级或更长,准实时(如小时级)批处理已能满足需求。
-
-
选择Kappa架构,当:
-
实时性是首要驱动力,业务需要秒级甚至毫秒级的洞察与响应(如实时反欺诈、物联网监控)。
-
业务逻辑天然适合用事件流来表达(如用户点击流分析、交易订单处理)。
-
团队希望简化技术栈,降低长期维护两套系统带来的开发、运维和一致性保障的成本。
-
技术团队有能力驾驭Flink等现代流处理引擎的复杂状态管理和运维。
-
4.2 未来趋势:流批一体的融合
近年来,随着以Apache Flink和Apache Spark Structured Streaming为代表的流批一体计算引擎的成熟,纯粹的Lambda或Kappa架构的边界正在模糊。Flink的核心设计哲学就是“万物皆流”,批处理被视作有界流(Bounded Stream)的特殊情况。很多情况下,需要Lambda架构和Kappa架构混合使用。
这种流批一体架构允许开发者使用同一套API(DataStream API或Table/SQL API)来编写业务逻辑,由框架根据数据源是有界还是无界,自动选择最优的执行模式(批处理或流处理)。这既吸收了Kappa架构“逻辑统一”的优点,又从引擎底层优化了批处理的执行效率,正在成为新一代大数据架构的主流方向。
例如,在Flink中,你可以用同一个StreamExecutionEnvironment编写作业,当从Kafka消费无界数据时,它作为流作业运行;当从HDFS读取一个历史文件时,它可以作为一个批作业高效运行,但代码逻辑无需更改。
4.3 总结
Lambda架构是特定技术发展阶段的智慧结晶,它通过“冗余”换取了“可靠”和“能力”。Kappa架构则是技术成熟后对“简洁”和“统一”的理性回归。如今,随着流批一体技术的普及,我们不再需要非此即彼地选择。理解这两种架构的深刻内涵,能帮助我们在面对复杂的大数据需求时,设计出更优雅、更健壮、也更易于维护的系统。无论是选择经典的Lambda,拥抱简洁的Kappa,还是采用先进的流批一体,其最终目标都是一致的:高效、准确、及时地从数据中挖掘价值。



















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











