






 本文介绍了在Windows环境中使用ShardingSphere-Proxy进行数据库分库分表的配置与操作,包括下载安装、配置server.yaml和config-sharding.yaml,以及通过命令行和SpringBoot应用进行数据操作的体验。详细展示了如何创建分片规则,以及在实际操作中遇到的问题和解决方案。
本文介绍了在Windows环境中使用ShardingSphere-Proxy进行数据库分库分表的配置与操作,包括下载安装、配置server.yaml和config-sharding.yaml,以及通过命令行和SpringBoot应用进行数据操作的体验。详细展示了如何创建分片规则,以及在实际操作中遇到的问题和解决方案。
windows环境下使用ShardingSphere-Proxy 设置分库分表初体验
前言:最近在学习数据库的分库分表的相关知识,当系统的数据库规模极其庞大时,单体库的性能、高可用性、容量都面临绝境难以扩展适应需求,为了解决这类问题,于是了有主从集群,读写分离,分库分表等相关技术支持。数据库的组从集群读写分离,解决了高可用性的问题和分摊读与写的压力,但是没有解决数据容量扩展的问题。分库分表的技术出现就很好的解决了容量的问题。
ShardingSphere是apache的开源分布式数据库生态项目,对上述的读写分离,分库分表提供了支持,这里记录下第一次学习使用ShardingSphere-Proxy的记录,为了方便就仅在windows下体验。
文章目录
一、下载

- 打开cmd 解压包:
tar -zxvf apache-shardingsphere-5.0.0-alpha-shardingsphere-proxy-bin.tar.gz
二、前置准备
解压缩后修改
conf/server.yaml和以config-前缀开头的文件,如:conf/config-xxx.yaml文件,进行分片规则、读写分离规则配置 。配置方式请参考配置手册。下面有给出我的配置示例本示例预设将表t_order的数据分库 2个库
demo_ds_0,demo_ds_1,每个库分16个表t_order_0~t_order15存放
- 先创建好真实的库
demo_ds_0,demo_ds_1
- 进入conf目录配置好
server.yaml,config-sharding.yaml - 启动 shardingsphere-proxy :
start.bat 3316

(一)server.yml
# governance:
# name: governance_ds
# registryCenter:
# type: ZooKeeper
# serverLists: localhost:2181
# props:
# retryIntervalMilliseconds: 500
# timeToLiveSeconds: 60
# maxRetries: 3
# operationTimeoutMilliseconds: 500
# overwrite: true
authentication:
users:
root:
password: 123456
# sharding:
# password: sharding
# authorizedSchemas: sharding_db
props:
max-connections-size-per-query: 1
acceptor-size: 16 # The default value is available processors count * 2.
executor-size: 16 # Infinite by default.
proxy-frontend-flush-threshold: 128 # The default value is 128.
# LOCAL: Proxy will run with LOCAL transaction.
# XA: Proxy will run with XA transaction.
# BASE: Proxy will run with B.A.S.E transaction.
proxy-transaction-type: LOCAL
proxy-opentracing-enabled: false
proxy-hint-enabled: false
query-with-cipher-column: false
sql-show: true
check-table-metadata-enabled: false
(二)config-sharding.yml
# 虚拟库名称
schemaName: sharding_db
dataSourceCommon:
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 5
minPoolSize: 1
maintenanceIntervalMilliseconds: 30000
# 映射真实数据源
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:33061/demo_ds_0?serverTimezone=UTC&useSSL=false
ds_1:
url: jdbc:mysql://127.0.0.1:33061/demo_ds_1?serverTimezone=UTC&useSSL=false
#配置规则 库是 ds_0 ~ ds_1 表是 t_order_0 ~ t_order_15
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..15}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
# t_order_item:
# actualDataNodes: ds_${0..1}.t_order_item_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_item_inline
# keyGenerateStrategy:
# column: order_item_id
# keyGeneratorName: snowflake
# bindingTables:
# - t_order,t_order_item
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
# 数据库的路由规则策略是user_id % 2 意思是 user_id % 2=0 的到ds_0,user_id % 2= 1的到ds_1
# 表的路由策略是 order_id % 16 意思是 order_id % 16=0 的到t_order_0 ... order_id % 16= 15的到的到t_order_15
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 16}
# t_order_item_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_item_${order_id % 2}
# 启用雪花算法
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
三、演示
(一)命令行体验
- 另起一个cmd 连接ShardingSphere-Proxy:
mysql -h 127.0.0.1 -P 3316 -uroot -p123456 -A
D:\mysql\mysql-8-master\bin>mysql -h 127.0.0.1 -P 3316 -uroot -p123456
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 7
Server version: 8.0.28-ShardingSphere-Proxy 5.0.0-RC1
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+-------------+
| Database |
+-------------+
| sharding_db |
+-------------+
1 row in set (0.00 sec)
mysql> CREATE TABLE IF NOT EXISTS t_order (order_id BIGINT NOT NULL AUTO_INCREMENT, user_id INT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id));
Query OK, 0 rows affected (1.26 sec)
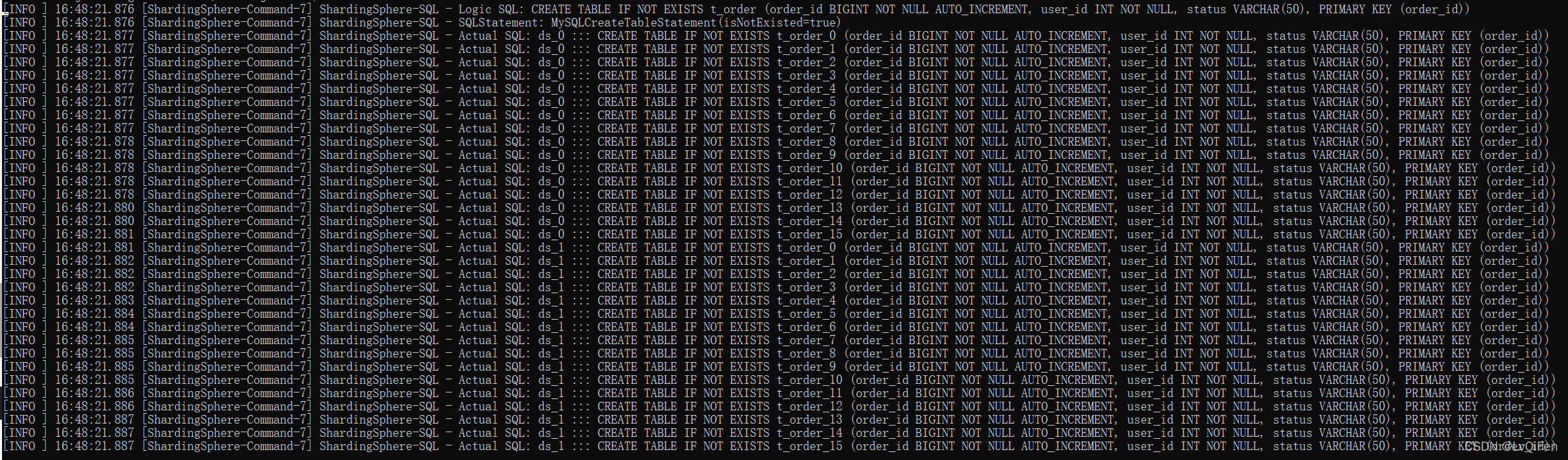
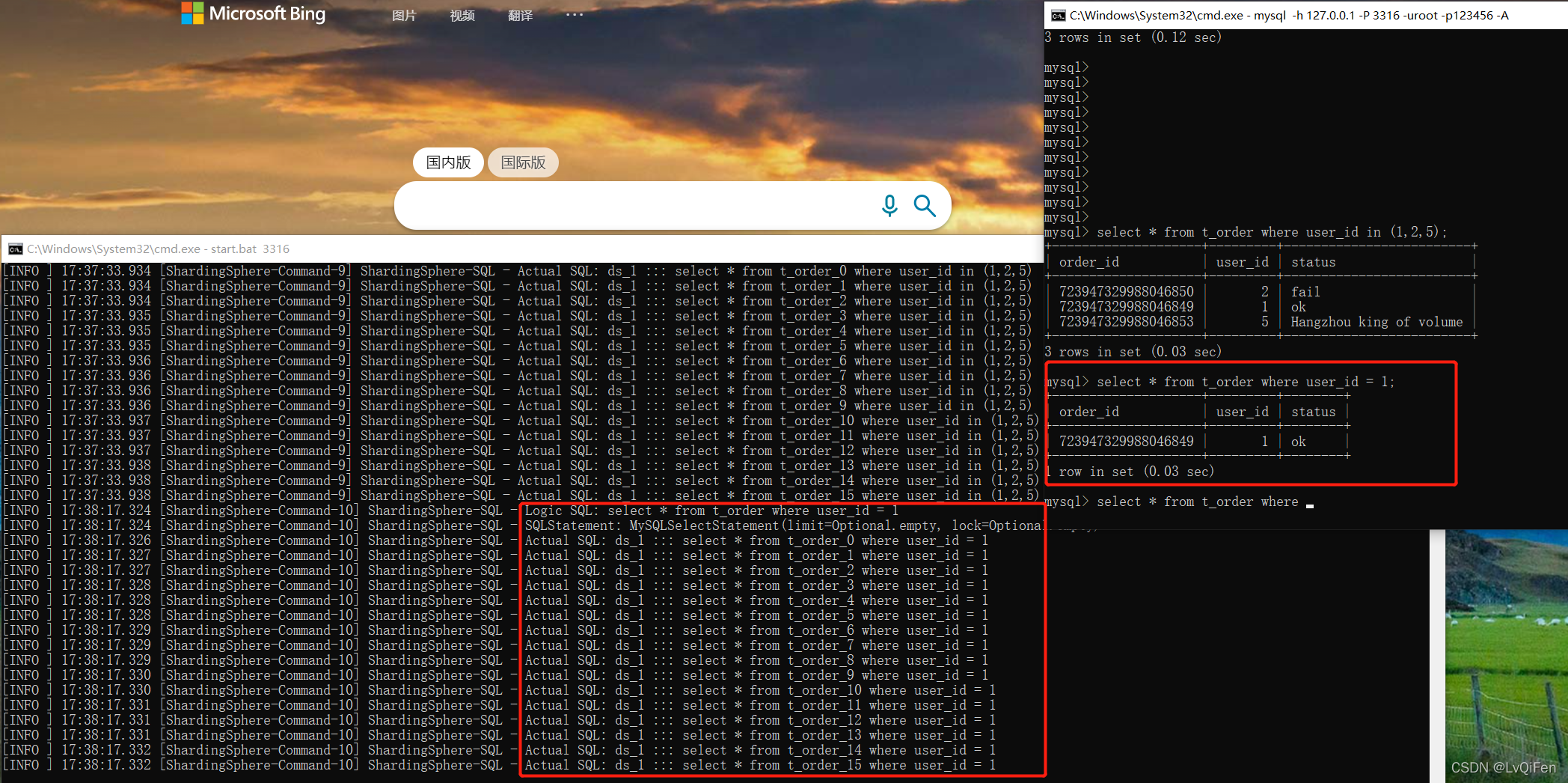
- 神奇的体验来了 执行
CREATE TABLE IF NOT EXISTS t_order (order_id BIGINT NOT NULL AUTO_INCREMENT, user_id INT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id));时,会在demo_ds_0 和demo_ds_1同时创建16张表. 下图是ShardingSphere-Proxy 服务端的日志打印情况
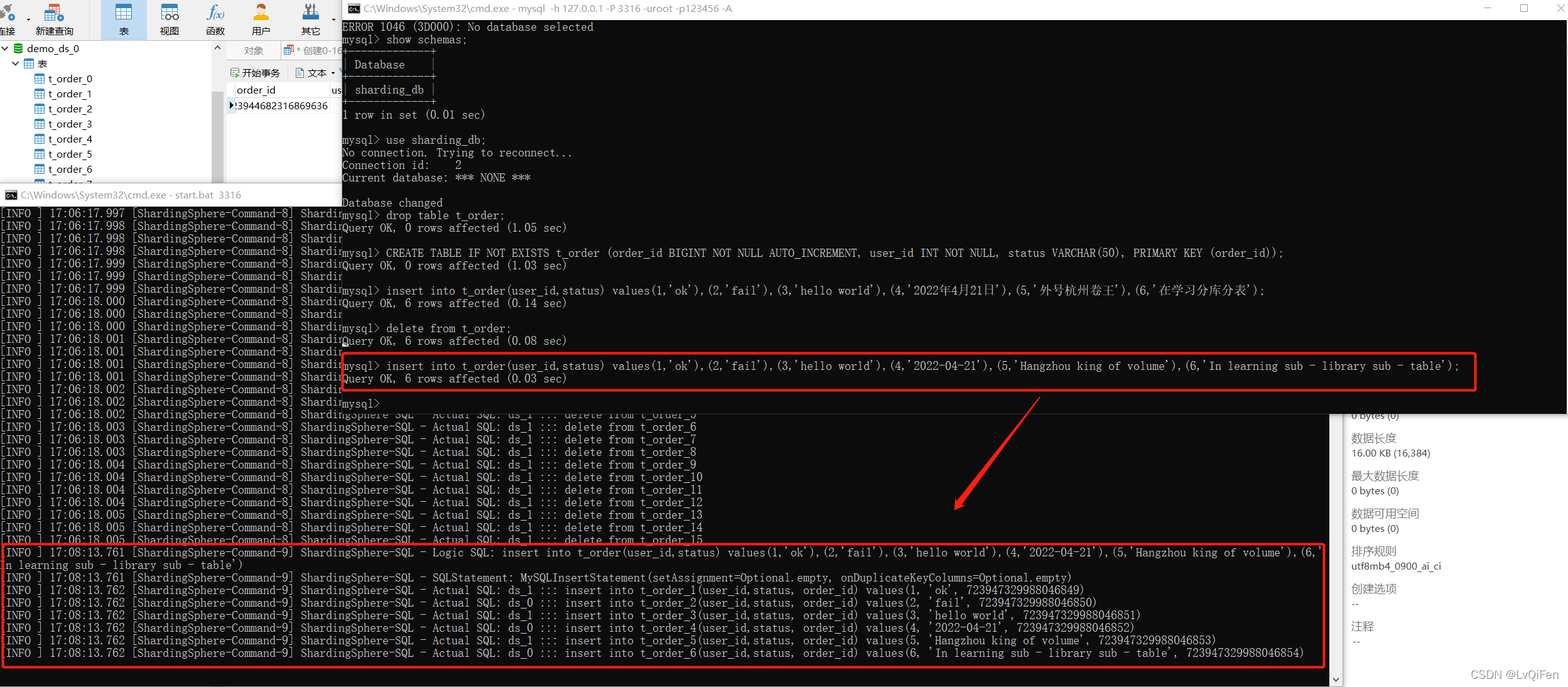
- 插入数据:
insert into t_order(user_id,status) values(1,'ok'),(2,'fail'),(3,'hello world'),(4,'2022-04-21'),(5,'Hangzhou king of volume'),(6,'In learning sub - library sub - table');此时会根据user_id为奇数时路由使用ds_1, user_id 为偶数时使用ds_0,插入数据时的 order_id是更具配置的雪花算法自动生成的值对16取模,放到对应的t_orderX表里插入数据。
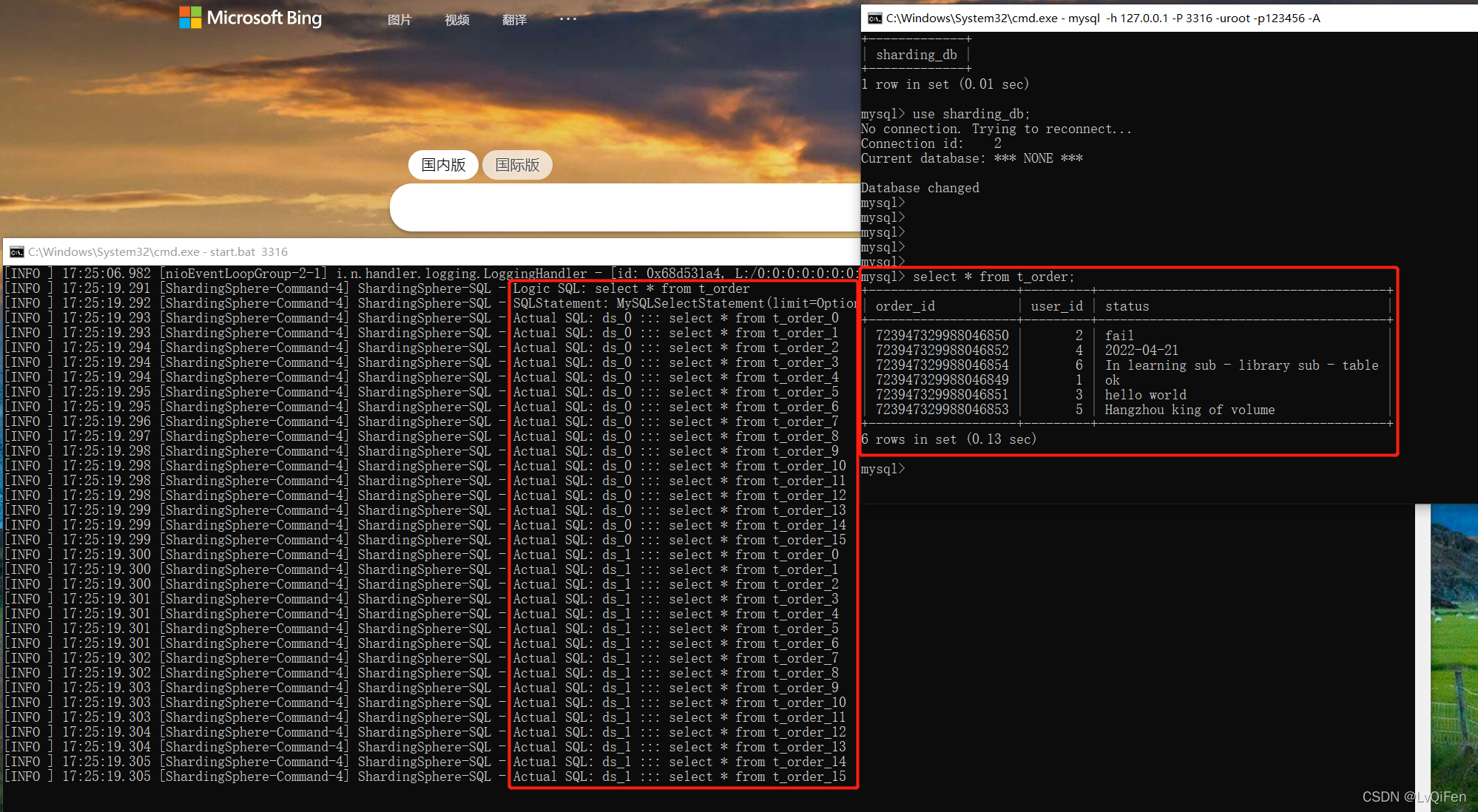
- 查询数据:
select * from t_order;执行该sql 未带条件,会从2个数据库里捞出所有数据合并返回。如果带的条件包含user_id,order_id则会根据配置的情况进行路由捞取数据。
(二)spring boot 内体验
四、踩坑
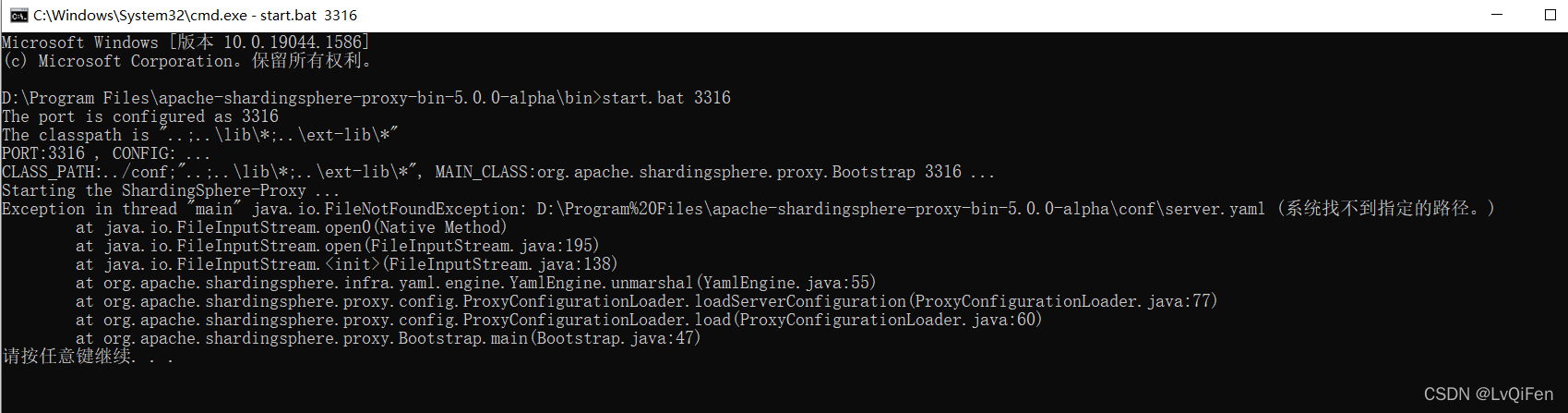
- 启动
shardingSphere-proxy服务失败,报找不到server.xml根据输出的异常日志就是 所在目录下有空格转成 %27导致,该问题解决方式有2种: 1. 把服务放在不带空格的目录下启动。 2.用5.1版本的shardingSphere-proxy
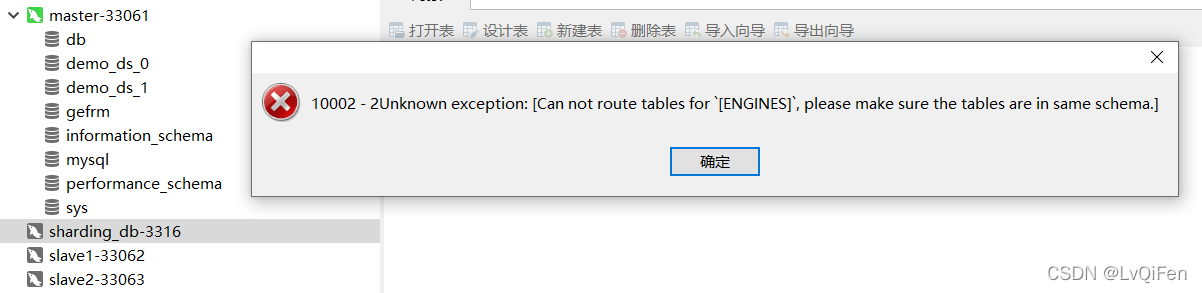
- 用navicat 连接服务报错 10002:该问题是工具本身问题,通过命令行连接是正常的,不用在意。

















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









