



2024年12月31日,JBoltAI正式推出V3.5.0版本,其核心突破在于深度整合Milvus 2.5向量数据库,并创新性地实现BM25算法与向量检索的混合搜索。此次升级不仅支持多模态数据处理(如Text2Json、Text2Sql),还通过全新思维链架构优化了复杂业务逻辑的拆解能力。该版本发布后,已助力医疗、金融、零售等多个行业客户实现AI应用效率提升,成为企业智能化转型的“技术引擎”。
Milvus:AI时代的“数据中枢”
1. Milvus的本质与技术特性
Milvus是由Zilliz开源的云原生向量数据库,专为海量非结构化数据(如图像、文本、音频)的向量化存储与检索设计。其核心优势包括:
- 高维向量处理:支持百亿级向量数据的毫秒级相似度搜索,适用于大规模AI模型训练与推理。
- 混合检索能力:结合BM25(基于关键词的文本检索)与向量相似度计算(如余弦距离),实现“语义+关键词”的双重匹配,提升搜索精度。
- 分布式架构:支持水平扩展至PB级数据,通过分片(Sharding)和负载均衡保障高并发场景下的稳定性。
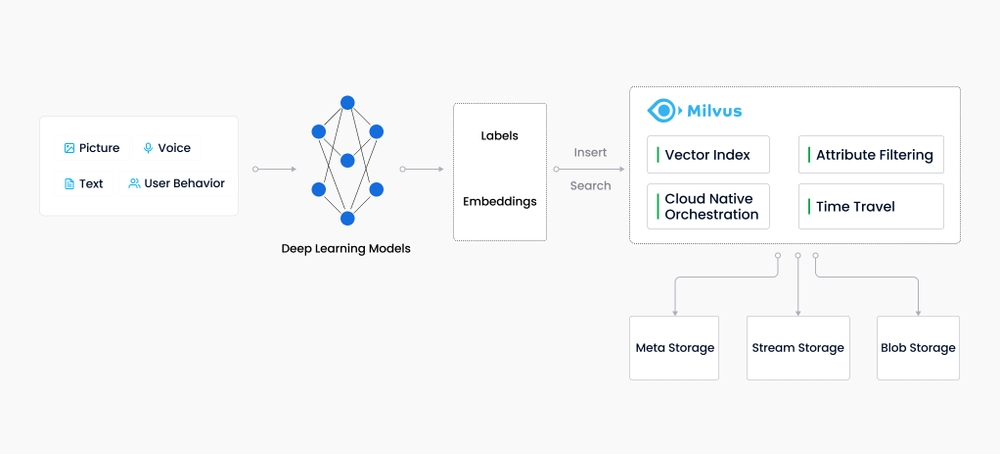
2. Milvus与传统数据库的对比
| 维度 | 传统数据库 | Milvus向量数据库 |
|---|---|---|
| 数据模型 | 结构化数据(表格) | 非结构化数据的向量表示 |
| 查询方式 | SQL精确匹配 | 向量相似度计算(模糊匹配) |
| 适用场景 | 金融交易、订单管理等 | 语义搜索、图像识别、推荐系统 |
Milvus的三大应用价值
1. 智能搜索:从“关键词匹配”到“理解意图”
- 场景案例:在电商领域,Milvus支持将商品描述、用户评论转化为向量,结合BM25算法实现“以图搜商品”和“文本语义搜索”的混合检索。某头部平台接入后,搜索转化率提升,用户停留时长增加。
- 技术支撑:Milvus的HNSW(分层导航小世界)索引算法,在保证检索速度的同时,支持动态调整相似度阈值,适应不同业务需求。
2. 推荐系统:打破“信息茧房”的个性化推荐
- 用户画像构建:通过Milvus将用户行为(点击、购买记录)转化为兴趣向量,与商品特征向量匹配。某短视频平台应用后,推荐点击率提升。
- 冷启动优化:新用户或商品可通过Milvus的聚类功能快速融入推荐池,降低冷启动成本。
3. 多模态与RAG技术:跨模态数据协同
- 医疗影像分析:Milvus支持CT影像与病历文本的联合编码,辅助诊断准确率提升。
- RAG增强:在金融领域,Milvus将财报、新闻等非结构化数据向量化,与大语言模型结合,解决生成内容的事实性错误问题。
JBoltAI × Milvus:技术协同的三大突破
1. 混合检索架构:BM25+向量搜索双引擎
JBoltAI V3.5.0通过Milvus 2.5实现BM25算法与向量检索的混合搜索。例如,在法律文书检索中,系统可同时匹配关键词(如“合同纠纷”)和语义相似度(如“违约责任条款”),召回结果更精准。
2. 思维链架构优化:复杂业务逻辑的自动化拆解
结合Milvus的向量检索能力,JBoltAI的思维链(Chain of Thought)架构支持多节点编排。例如,用户提问“生成2024年Q4销售报告”时,系统自动拆解为“数据提取→趋势分析→可视化生成”三步,并调用对应工具链执行。
3. 企业级部署支持:安全与性能的平衡
Milvus的分布式架构与JBoltAI的私有化部署方案深度整合,支持金融、政务等敏感行业的数据隔离与灾备。某银行客户通过混合云部署,实现核心业务系统AI改造的同时满足等保要求。
无论是开发智能客服、构建行业知识库,还是设计跨模态应用,JBoltAI与Milvus的协同方案都将成为你的技术基石。加入AITCA(人工智能应用开发技术公司联盟),即可与JBoltAI团队进行深度握手,让我们合作共赢!


















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









