







 本文深入探讨了机器学习的基础概念,包括其定义、学科定位及学习原理。覆盖了监督学习、非监督学习和半监督学习的基本原理,介绍了决策树、神经网络、支持向量机等经典算法,以及深度学习的起源和发展。
本文深入探讨了机器学习的基础概念,包括其定义、学科定位及学习原理。覆盖了监督学习、非监督学习和半监督学习的基本原理,介绍了决策树、神经网络、支持向量机等经典算法,以及深度学习的起源和发展。
目录
2.1 机器学习 (Machine Learning, ML)
3.1 监督学习(Suprivised Learning)、分类(Classification)
3.1.3 支持向量机(Surpport Vector Machine)
3.2 监督学习(Suprivised Learning)、回归(Regression)
3.2.1 非线性回归(Non-linear Regression)
3.3 非监督学习(Unsuprivised Learning)
一 机器/深度学习简介
2.1 机器学习 (Machine Learning, ML)
2.1.1概念
多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
2.1.2 学科定位
人工智能(Artificial Intelligence, AI)的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
2.1.3 定义
探究和开发一系列算法来如何使计算机不需要通过外部明显的指示,而可以自己通过数据来学习,建模,并且利用建好的模型和新的输入来进行预测的学科。
Arthur Samuel(1959): 一门不需要通过外部程序指示而让计算机有能力自我学习的学科
Langley(1996) : “机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”
Tom Michell(1997): “机器学习是对能通过经验自动改进的计算机算法的研究”
2.1.4: 学习
针对经验E(experience) 和一系列的任务 T(tasks) 和一定表现的衡量 P,如果随之经验E的积累,针对定义好的任务T可以提高表现P,就说计算机具有学习能力 例子: 下棋,语音识别,自动驾驶汽车等
2.2 深度学习
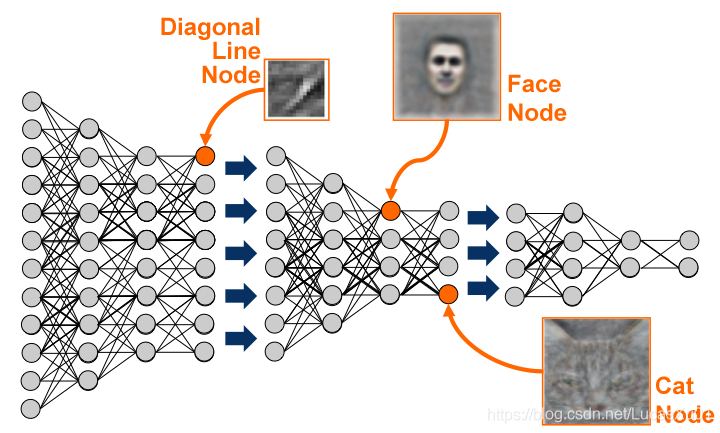
是基于机器学习延伸出来的一个新的领域,由以人大脑结构为启发的神经网络算法为起源加之模型结构深度的增加发展,并伴随大数据和计算能力的提高而产生的一系列新的算法。
概念由著名科学家Geoffrey Hinton等人在2006年和2007年在《Sciences》等上发表的文章被提出和兴起。
二 基本概念
2.1 基本概念
训练集,测试集,特征值,监督学习,非监督学习,半监督学习,分类,回归
| 训练集(training set/data)/训练样例(training examples): | 用来进行训练,也就是产生模型或者算法的数据集 |
| 测试集(testing set/data)/测试样例 (testing examples): | 用来专门进行测试已经学习好的模型或者算法的数据集 |
| 特征向量(features/feature vector): | 属性的集合,通常用一个向量来表示,附属于一个实例 |
| 标记(label): | c(x), 实例类别的标记 |
| 正例(positive example) | |
| 反例(negative example) |
人类学习概念:鸟,车,计算机
概念学习定义:概念学习是指从有关某个布尔函数的输入输出训练样例中推断出该布尔函数
2.2 有/无/半监督学习
- 有监督学习(supervised learning): 训练集有类别标记(class label)
- 无监督学习(unsupervised learning): 无类别标记(class label)
- 半监督学习(semi-supervised learning):有类别标记的训练集 + 无标记的训练集
2.3 机器学习步骤框架
- 把数据拆分为训练集和测试集
- 用训练集和训练集的特征向量来训练算法
- 用学习来的算法运用在测试集上来评估算法 (可能要设计到调整参数(parameter tuning), 用验证集(validation set)
三 机器学习
3.1 监督学习(Suprivised Learning)、分类(Classification)
3.1.1 决策树(Decision Tree)
决策树是一种机器学习的方法。决策树的生成算法有ID3, C4.5和C5.0等。
决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。决策树是一种十分常用的分类方法,需要监管学习(有教师的Supervised Learning),通过学习这些样本得到一个决策树,这个决策树能够对新的数据给出正确的分类。判定树是一个类似于流程图的树结构。具体见:决策树
3.1.2 临近取样(Nearest Neighbor)
3.1.3 支持向量机(Surpport Vector Machine)
3.1.4 神经网络算法(Neural Network)
3.2 监督学习(Suprivised Learning)、回归(Regression)
3.2.1 线性回归(Linear Regression)
3.2.1 非线性回归(Non-linear Regression)
3.3 非监督学习(Unsuprivised Learning)
3.3.1 K-means算法聚类(Clustering)
3.3.2 Hierarchical算法聚类


















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











