






📝 前提条件
- CPU >= 4 核
- RAM >= 16 GB
- Disk >= 50 GB
- python==3.11.7(大于3.8即可,本机环境为3.11.7)
- openKylin 1.0.2
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
如果你并没有在本机安装 Docker(Windows、Mac,或者 Linux), 可以参考文档 Install Docker Engine 自行安装。
🔨 以源代码启动服务
源神!启动!!!
1、安装 Poetry。如已经安装,可跳过本步骤:
pipx install poetry # 如果未安装pipx,需要先使用pip install pipx安装 pipx inject poetry poetry-plugin-pypi-mirror #插件安装 #设置环境变量以及国内镜像源 export POETRY_VIRTUALENVS_CREATE=true POETRY_VIRTUALENVS_IN_PROJECT=true export POETRY_PYPI_MIRROR_URL=https://pypi.tuna.tsinghua.edu.cn/simple/
2、下载源代码并安装 Python 依赖:
使用git下载也可,本机没有安装配置git,下载源码包,解压到指定目录
cd ragflow/ # 进入项目根目录
~/.local/bin/poetry install --sync --no-root # install RAGFlow dependent python modules执行依赖安装报错:于缺少 C++ 编译器(g++)
Installing pyicu (2.14): Failed
ChefBuildError
Backend subprocess exited when trying to invoke build_wheel
<string>:42: DeprecationWarning: Use shutil.which instead of find_executable
<string>:42: DeprecationWarning: Use shutil.which instead of find_executable
/tmp/tmpn73_dt82/.venv/lib/python3.11/site-packages/setuptools/_distutils/dist.py:261: UserWarning: Unknown distribution option: 'test_suite'
warnings.warn(msg)
/tmp/tmpn73_dt82/.venv/lib/python3.11/site-packages/setuptools/_distutils/dist.py:261: UserWarning: Unknown distribution option: 'tests_require'
warnings.warn(msg)
(running 'icu-config --version')
Building PyICU 2.14 for ICU 73.1 (max ICU major version supported: 76)
(running 'icu-config --cxxflags --cppflags')
Adding CFLAGS="-I/home/dgis/anaconda3/include" from /home/dgis/anaconda3/bin/icu-config
(running 'icu-config --ldflags')
Adding LFLAGS="-L/home/dgis/anaconda3/lib -licui18n -licuuc -licudata" from /home/dgis/anaconda3/bin/icu-config
running bdist_wheel
running build
running build_py
creating build/lib.linux-x86_64-cpython-311/icu
copying py/icu/init.py -> build/lib.linux-x86_64-cpython-311/icu
running build_ext
building 'icu.icu' extension
creating build/temp.linux-x86_64-cpython-311
g++ -pthread -B /home/dgis/anaconda3/compiler_compat -DNDEBUG -fwrapv -O2 -Wall -fPIC -O2 -isystem /home/dgis/anaconda3/include -fPIC -O2 -isystem /home/dgis/anaconda3/include -fPIC -I/tmp/tmpn73_dt82/.venv/include -I/home/dgis/anaconda3/include/python3.11 -c icu.cpp -o build/temp.linux-x86_64-cpython-311/icu.o -std=c++17 -I/home/dgis/anaconda3/include -DPYICU_VER="2.14" -DPYICU_ICU_MAX_VER="76"
error: command 'g++' failed: No such file or directory
at ~/.local/share/pipx/venvs/poetry/lib/python3.11/site-packages/poetry/installation/chef.py:164 in _prepare
160│
161│ error = ChefBuildError("\n\n".join(message_parts))
162│
163│ if error is not None:
→ 164│ raise error from None
165│
166│ return path
167│
168│ def _prepare_sdist(self, archive: Path, destination: Path | None = None) -> Path:
Note: This error originates from the build backend, and is likely not a problem with poetry but with pyicu (2.14) not supporting PEP 517 builds. You can verify this by running 'pip wheel --no-cache-dir --use-pep517 "pyicu (==2.14)"'.解决方案:打开终端并运行以下命令,确保安装完成后重新执行
sudo apt update
sudo apt install build-essential
~/.local/bin/poetry install --sync --no-root3、通过 Docker Compose 启动依赖的服务(MinIO, Elasticsearch, Redis, and MySQL):
#官方命令
docker compose -f docker/docker-compose-base.yml up -d
#这里本机装的docker-compose的执行命令是要带‘-’的,所以跟github上可能不一样,具体根据实际情况使用
docker-compose -f docker/docker-compose-base.yml up -d如果未安装docker:可自行安装,本机使用麒麟系统,安装docker遇到很多问题,下面主要介绍麒麟安装docker的正确步骤(其他系统类同):
1. 查看系统版本
[root@localhost opt]# cat /etc/os-release #输出 NAME="Kylin" VERSION="银河麒麟桌面操作系统V10 (SP1)" VERSION_US="Kylin Linux Desktop V10 (SP1)" ID=kylin ID_LIKE=debian PRETTY_NAME="Kylin V10 SP1" VERSION_ID="v10" HOME_URL="http://www.kylinos.cn/" SUPPORT_URL="http://www.kylinos.cn/support/technology.html" BUG_REPORT_URL="http://www.kylinos.cn/" PRIVACY_POLICY_URL="http://www.kylinos.cn" VERSION_CODENAME=kylin UBUNTU_CODENAME=kylin PROJECT_CODENAME=V10SP1 KYLIN_RELEASE_ID="2303" [root@localhost opt]# cat /etc/kylin-build #输出结果 Kylin-Desktop V10-SP1 Build 20230427 buildid: 41998 [root@localhost opt]# nkvers这个命令会显示麒麟系统的构建版本信息:使用的是麒麟(Kylin)桌面版系统,具体版本为Kylin-Desktop V10-SP1-hwe,构建日期为2021年8月20日。
2、查看 Linux 内核版本(3.10以上)
[root@localhost opt]# uname -r 5.4.18-85-generic [root@localhost opt]# uname -a Linux it0-pc 5.4.18-85-generic #74-KYLINOS SMP Fri Mar 24 11:20:42 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux3. 查看 iptabls 版本(1.4以上)
[root@localhost opt]# iptables --version iptables v1.8.4 (legacy)4. 判断处理器架构
[root@localhost opt]# uname -p x86_64 # 也可能 是 aarch64系统处理器架构为 [ARM 架构](https://so.youkuaiyun.com/so/search?q=ARM 架构&spm=1001.2101.3001.7020);如果为 x86 架构的,则会显示
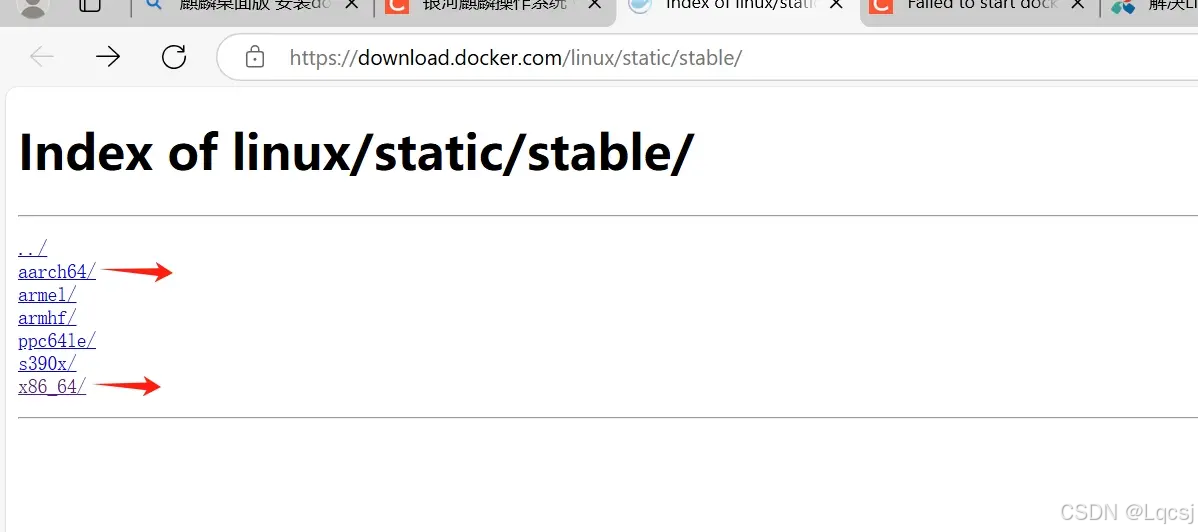
x86_64;5. 离线下载 Docker 安装包
https://download.docker.com/linux/static/stable/
点进去,选择想要安装的版本, 下载了版本:
docker-27.3.1.tgz下载完成后,上传至服务器
/opt目录下,然后解压:tar -zxvf docker-27.3.1.tgz6. 移动解压出来的二进制文件到 /usr/bin 目录中
sudo mv docker/* /usr/bin/然后就可以测试下Docker
[root@localhost opt]# sudo docker -v #输出 Docker version 27.3.1, build ce12230 [root@localhost opt]# sudo docker version #输出 Client: Version: 27.3.1 API version: 1.41 (downgraded from 1.47) Go version: go1.22.7 Git commit: ce12230 Built: Fri Sep 20 11:39:44 2024 OS/Arch: linux/amd64 Context: default Server: Engine: Version: 20.10.7 API version: 1.41 (minimum version 1.12) Go version: go1.13.8 Git commit: 20.10.7-0kylin5~20.04.2 Built: Tue Nov 9 01:25:31 2021 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.5.9-0kylin1~20.04.6 GitCommit: runc: Version: 1.1.4-0kylin1~20.04.3 GitCommit:此时Docker 还没启动,只是可以看到Docker 的版本信息了。
测试 Docker 启动:
[root@localhost opt]# dockerd可以看到 docker 可以正常启动,不过当前是在窗口中手动启动的,Ctrl + C,杀掉就好。
7. 配置 Docker 服务
7.1 编辑 docker 的系统服务文件
vi /usr/lib/systemd/system/docker.service为docker.service添加可读写权限
sudo chmod 777 /usr/lib/systemd/system/docker.service7.2 将下面的内容复制到刚创建的docker.service文件中
[Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify ExecStart=/usr/bin/dockerd ExecReload=/bin/kill -s HUP $MAINPID LimitNOFILE=infinity LimitNPROC=infinity TimeoutStartSec=0 Delegate=yes KillMode=process Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target7.3 为docker.service添加执行权限
sudo chmod +x /usr/lib/systemd/system/docker.service7.4 编辑daemon.json
vi /etc/docker/daemon.json #并添加以下内容: { "registry-mirrors": ["https://registry.docker-cn.com"], "exec-opts": ["native.cgroupdriver=systemd"] }保存后,执行:
sudo systemctl daemon-reload7.5 启动 Docker
[root@localhost opt]# sudo systemctl start docker7.6 添加开机自动启动
[root@localhost opt]# sudo systemctl enable dockerDocker 安装 参考: https://blog.youkuaiyun.com/qq_30665009/article/details/125938033
8.安装 docker-compose
直接 GitHub 下载:docker/compose 选择自己喜欢的版本,这里直接拉满,下载当前最新的版本:v2.24.0
这里根据自己的架构,选择对应的包,下载就好了。
cp docker-compose-linux-aarch64 /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose查看版本
[root@localhost opt]# docker-compose -v Docker Compose version v2.24.0
作者:zhanglb12
链接:https://www.jianshu.com/p/fd7210b3c8e4
来源:简书
著作权归作者所有。
拉取镜像发现es拉取很慢。
解决方案:手动拉取镜像后,重新执行命令
sudo docker pull elasticsearch:8.11.34、在 /etc/hosts 中添加以下代码,将 conf/service_conf.yaml 文件中的所有 host 地址都解析为 127.0.0.1:
127.0.0.1 es01 infinity mysql minio redis
在文件 docker/service_conf.yaml 中,对照 docker/.env 的配置将 mysql 端口更新为 5455,es 端口更新为 1200。
5、如果无法访问 HuggingFace,可以把环境变量 HF_ENDPOINT 设成相应的镜像站点:
#注:临时方案,当终端关闭,这条环境变量消失,需要重新设置
export HF_ENDPOINT=https://hf-mirror.com6、启动后端服务:
source .venv/bin/activate
export PYTHONPATH=$(pwd)
bash docker/launch_backend_service.sh执行bash docker/launch_backend_service.sh报错:导入
api模块时未能找到该模块Starting task_executor.py for task 0 (Attempt 1) Starting ragflow_server.py (Attempt 1) Traceback (most recent call last): File "rag/svr/task_executor.py", line 24, in <module> from api.utils.log_utils import initRootLogger ModuleNotFoundError: No module named 'api' Traceback (most recent call last): File "api/ragflow_server.py", line 23, in <module> from api.utils.log_utils import initRootLogger ModuleNotFoundError: No module named 'api'解决方案:
1、在 Python 环境中测试导入
在你的 Python 虚拟环境中,尝试手动导入
api模块,看看是否能成功:python3然后在 Python 交互式命令行中运行:
import api.ragflow_server报错根本原因是缺少
transformers模块:(ragflow-py3.11) (base) dgis@think:~/project/ragflow$ python3 Python 3.11.7 (main, Dec 15 2023, 18:12:31) [GCC 11.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. import api.ragflow_server Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/home/dgis/project/ragflow/api/ragflow_server.py", line 33, in <module> from api.apps import app File "/home/dgis/project/ragflow/api/apps/init.py", line 136, in <module> client_urls_prefix = [ ^ File "/home/dgis/project/ragflow/api/apps/init.py", line 137, in <listcomp> register_page(path) for dir in pages_dir for path in search_pages_path(dir) ^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/api/apps/init.py", line 120, in register_page spec.loader.exec_module(page) File "/home/dgis/project/ragflow/api/apps/file_app.py", line 24, in <module> from api.db.services.document_service import DocumentService File "/home/dgis/project/ragflow/api/db/services/document_service.py", line 31, in <module> from graphrag.mind_map_extractor import MindMapExtractor File "/home/dgis/project/ragflow/graphrag/mind_map_extractor.py", line 28, in <module> from rag.llm.chat_model import Base as CompletionLLM File "/home/dgis/project/ragflow/rag/llm/init.py", line 85, in <module> from .cv_model import ( File "/home/dgis/project/ragflow/rag/llm/cv_model.py", line 28, in <module> from transformers import GenerationConfig ModuleNotFoundError: No module named 'transformers'解决方案:
手动安装依赖:
尝试手动下载transformers的源代码包并安装。可以在 PyPI 上找到相应的文件,然后使用以下命令安装:pip install /path/to/downloaded/transformers-4.38.1-py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple解决完上一下,继续下一个:环境中没有找到 PyTorch、TensorFlow 或 Flax 这三种深度学习框架中的任何一个。
import api.ragflow_server None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.解决方案:
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple --extra-index-url https://download.pytorch.org/whl/cu113到这,后端服务就已经能正常启动了,但是在前端使用过程中,遇到 Python 无法找到名为
FlagEmbedding的模块。": "naive", "parser_config": {"auto_keywords": 0, "auto_questions": 0, "raptor": {"use_raptor": false}, "chunk_token_num": 128, "delimiter": "\n!?;\u3002\uff1b\uff01\uff1f", "layout_recognize": true, "html4excel": false}, "name": "\u4e00\u6c7d\u5927\u4f17 ID6 CROZZ\u4f7f\u7528\u8bf4\u660e\u4e66.pdf", "type": "pdf", "location": "\u4e00\u6c7d\u5927\u4f17 ID6 CROZZ\u4f7f\u7528\u8bf4\u660e\u4e66.pdf", "size": 5129608, "tenant_id": "82013314b6ce11efb9e5f46b8c8bef44", "language": "Chinese", "embd_id": "BAAI/bge-large-zh-v1.5@BAAI", "pagerank": 0, "img2txt_id": "qwen-vl-max@Tongyi-Qianwen", "asr_id": "paraformer-realtime-8k-v1@Tongyi-Qianwen", "llm_id": "qwen-plus@Tongyi-Qianwen", "update_time": 1733882818905} Traceback (most recent call last): File "/home/dgis/project/ragflow/rag/svr/task_executor.py", line 464, in handle_task do_handle_task(task) File "/home/dgis/project/ragflow/rag/svr/task_executor.py", line 382, in do_handle_task embedding_model = LLMBundle(task_tenant_id, LLMType.EMBEDDING, llm_name=task_embedding_id, lang=task_language) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/api/db/services/llm_service.py", line 226, in init self.mdl = TenantLLMService.model_instance( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/peewee.py", line 3128, in inner return fn(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/api/db/services/llm_service.py", line 129, in model_instance return EmbeddingModel[model_config["llm_factory"]]( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/llm/embedding_model.py", line 65, in init from FlagEmbedding import FlagModel ModuleNotFoundError: No module named 'FlagEmbedding'解决方案:
pip install flagembedding==1.2.10 -i https://pypi.tuna.tsinghua.edu.cn/simple在系统前端页面解析文档,继续报错:
Traceback (most recent call last): File "/home/dgis/project/ragflow/rag/svr/task_executor.py", line 464, in handle_task do_handle_task(task) File "/home/dgis/project/ragflow/rag/svr/task_executor.py", line 405, in do_handle_task chunks = build_chunks(task, progress_callback) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/svr/task_executor.py", line 189, in build_chunks cks = chunker.chunk(task["name"], binary=binary, from_page=task["from_page"], ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/app/naive.py", line 202, in chunk "title_tks": rag_tokenizer.tokenize(re.sub(r".[a-zA-Z]+", "", filename)) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/nlp/rag_tokenizer.py", line 321, in tokenize res = " ".join(self.english_normalize_(res)) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/nlp/rag_tokenizer.py", line 251, in english_normalize_ return [self.stemmer.stem(self.lemmatizer.lemmatize(t)) if re.match(r"[a-zA-Z_-]+", t) else t for t in tks] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/nlp/rag_tokenizer.py", line 251, in <listcomp> return [self.stemmer.stem(self.lemmatizer.lemmatize(t)) if re.match(r"[a-zA-Z_-]+$", t) else t for t in tks] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/stem/wordnet.py", line 85, in lemmatize lemmas = self._morphy(word, pos) ^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/stem/wordnet.py", line 41, in _morphy return wn._morphy(form, pos, check_exceptions) ^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/corpus/util.py", line 120, in getattr self.__load() File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/corpus/util.py", line 86, in __load raise e File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/corpus/util.py", line 81, in __load root = nltk.data.find(f"{self.subdir}/{self.__name}") ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/data.py", line 579, in find raise LookupError(resource_not_found) LookupError: Resource wordnet not found. Please use the NLTK Downloader to obtain the resource: import nltk nltk.download('wordnet') For more information see: https://www.nltk.org/data.html Attempted to load corpora/wordnet Searched in: - '/home/dgis/nltk_data' - '/home/dgis/project/ragflow/.venv/nltk_data' - '/home/dgis/project/ragflow/.venv/share/nltk_data' - '/home/dgis/project/ragflow/.venv/lib/nltk_data' - '/usr/share/nltk_data' - '/usr/local/share/nltk_data' - '/usr/lib/nltk_data' - '/usr/local/lib/nltk_data'解决方案:
打开 Python 解释器:
在终端中输入python或python3进入 Python 解释器。python下载 WordNet:
在 Python 解释器中输入以下代码:import nltk nltk.download('wordnet')这将启动 NLTK 的下载器,并下载
wordnet资源。发现这种做法太慢了,直接手动下载,放到指定位置解压!!!
你可以直接从命令行使用 wget 或 curl 下载 wordnet 数据集。以下是一个示例: wget https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/corpora/wordnet.zip 下载后,解压并将其放入 NLTK 数据目录中: unzip wordnet.zip -d /path/to/your/nltk_data/corpora/解决完上一个,继续解析文档,又又又报错辣:
File "/home/dgis/project/ragflow/rag/app/naive.py", line 229, in chunk sections, tables = pdf_parser(filename if not binary else binary, from_page=from_page, to_page=to_page, callback=callback) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/app/naive.py", line 150, in call tbls = self._extract_table_figure(True, zoomin, True, True) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/deepdoc/parser/pdf_parser.py", line 810, in _extract_table_figure self.tbl_det.construct_table(bxs, html=return_html, is_english=self.is_english))) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/deepdoc/vision/table_structure_recognizer.py", line 148, in construct_table b["btype"] = TableStructureRecognizer.blockType(b) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/deepdoc/vision/table_structure_recognizer.py", line 120, in blockType tks = [t for t in rag_tokenizer.tokenize(b["text"]).split() if len(t) > 1] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/nlp/rag_tokenizer.py", line 258, in tokenize return " ".join([self.stemmer.stem(self.lemmatizer.lemmatize(t)) for t in word_tokenize(line)]) ^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/tokenize/init.py", line 142, in word_tokenize sentences = [text] if preserve_line else sent_tokenize(text, language) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/tokenize/init.py", line 119, in sent_tokenize tokenizer = _get_punkt_tokenizer(language) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/tokenize/init.py", line 105, in _get_punkt_tokenizer return PunktTokenizer(language) ^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/tokenize/punkt.py", line 1744, in init self.load_lang(lang) File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/tokenize/punkt.py", line 1749, in load_lang lang_dir = find(f"tokenizers/punkt_tab/{lang}/") ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/.venv/lib/python3.11/site-packages/nltk/data.py", line 579, in find raise LookupError(resource_not_found) LookupError: Resource punkt_tab not found. Please use the NLTK Downloader to obtain the resource: import nltk nltk.download('punkt_tab') For more information see: https://www.nltk.org/data.html Attempted to load tokenizers/punkt_tab/english/ Searched in: - '/home/dgis/nltk_data' - '/home/dgis/project/ragflow/.venv/nltk_data' - '/home/dgis/project/ragflow/.venv/share/nltk_data' - '/home/dgis/project/ragflow/.venv/lib/nltk_data' - '/usr/share/nltk_data' - '/usr/local/share/nltk_data' - '/usr/lib/nltk_data' - '/usr/local/lib/nltk_data'原因一样的,让我们继续来一遍:
直接手动下载,放到指定位置解压!!!
你可以直接从命令行使用 wget 或 curl 下载 wordnet 数据集。以下是一个示例: wget https://raw.githubusercontent.com/nltk/nltk_data/ghpages/packages/tokenizers/punkt_tab.zip 下载后,解压并将其放入 NLTK 数据目录中: unzip punkt_tab.zip -d /path/to/your/nltk_data/tokenizers/
到这儿,后端已经完成部署了,目前使用上也没出现什么bug,完结撒花!!!
---------------------------------------------2025.02.20追更--------------------------------------------------------
在RAG使用过程中,针对PPT类型的文档解析时,惊现系统崩溃错误!!!
分析原因应该是ICU库没有正确被找到,
Process terminated. Couldn't find a valid ICU package installed on the system. Set the configuration flag System.Globalization.Invariant to true if you want to run with no globalization support. at System.Environment.FailFast(System.String) at System.Globalization.GlobalizationMode.GetGlobalizationInvariantMode() at System.Globalization.GlobalizationMode..cctor() at System.Globalization.CultureData.CreateCultureWithInvariantData() at System.Globalization.CultureData.get_Invariant() at System.Globalization.CultureInfo..cctor() at System.Globalization.CultureInfo.GetCultureInfoHelper(Int32, System.String, System.String) at System.Globalization.CultureInfo.GetCultureInfo(System.String) at System.Reflection.RuntimeAssembly.GetLocale() at System.Reflection.RuntimeAssembly.GetName(Boolean) at System.Reflection.Assembly.GetName() at .(System.Reflection.Assembly) at .(Int32, Boolean) at .(Int32) at ..cctor() at Aspose.Slides.Presentation..cctor() at Aspose.Slides.Presentation..ctor(System.IO.Stream) at WrpNs_Aspose.WrpNs_Slides.WrpCs_Presenta_041D11ED.ctor_002_Presentation(Aspose.WrpGen.Interop.VariantArg*) docker/launch_backend_service.sh:行 69: 2575034 已放弃 $PY api/ragflow_server.py解决方法:
在linux直接运行此命令:注:这是单次设置,重启服务器后会失效。
export DOTNET_SYSTEM_GLOBALIZATION_INVARIANT=1
原以为已经顺利解决,但是祸不单行。重启解析又报错了,但是系统还没有崩溃,请看vcr:
ERROR:root:Chunking 10005ea31e5341f48cb3e40a6d29773c.pptx/xxxxx.pptx got exception Traceback (most recent call last): File "/home/dgis/project/ragflow/rag/svr/task_executor.py", line 189, in build_chunks cks = chunker.chunk(task["name"], binary=binary, from_page=task["from_page"], ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/app/presentation.py", line 107, in chunk for pn, (txt, img) in enumerate(ppt_parser( ^^^^^^^^^^^ File "/home/dgis/project/ragflow/rag/app/presentation.py", line 34, in __call__ with slides.Presentation(BytesIO(fnm)) as presentation: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ RuntimeError: Proxy error(PptxReadException): The type initializer for 'Gdip' threw an exception. ---> TypeInitializationException: The type initializer for 'Gdip' threw an exception. ---> DllNotFoundException: Unable to load shared library 'libgdiplus' or one of its dependencies. In order to help diagnose loading problems, consider setting the LD_DEBUG environment variable: liblibgdiplus: cannot open shared object file: No such file or directory
经了解,原因是在尝试处理 PPTX 文件时,程序无法加载 libgdiplus 共享库。这通常与图形处理或文档处理相关,特别是在使用 Mono 或某些依赖于 libgdiplus 的库时。
那么已知问题原因,直接上大招:
确认安装
libgdiplus:
首先,确保libgdiplus已正确安装。您可以使用以下命令在Linux系统上安装它:sudo apt-get update sudo apt-get install -y libgdiplus在其他 Linux 发行版上,使用相应的包管理器进行安装。
检查依赖项:
libgdiplus可能依赖于其他库,使用以下命令检查其依赖项:ldd /usr/lib/libgdiplus.so确保所有列出的库都已安装,并且没有显示 "not found"。
源神重启!!!嗯.....问题解决啦。开导开导!
7、安装前端依赖:
cd web
npm install --force又又又报错辣:没装npm和node环境。。。
来吧,解决方案:
安装 Node.js 和 npm
如果未安装 Node.js 和 npm,您可以通过以下步骤进行安装:
使用包管理器安装(适用于 Ubuntu/Debian)
sudo apt update
sudo apt install nodejs npm
使用 Node Version Manager (NVM) 安装
NVM 是一个用于管理 Node.js 版本的工具,推荐使用它:
-
安装 NVM:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.4/install.sh | bash安装完成后,您需要重启终端或运行以下命令以使 NVM 生效:
export NVM_DIR="$HOME/.nvm" [ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm -
使用 NVM 安装 Node.js:
nvm install node或者安装特定版本,例如:
nvm install 14 # 安装 Node.js 14.x 版本 -
安装完成后,您可以再次检查版本:
node -v npm -v
8、启动前端服务:
npm run dev 这下真的完结了,撒花!!

















 1655
1655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









