



对象持久化
所有程序运行的过程即使用编写的程序指令来调度运算特定数据,运算过程在内存中,内存并非永久性存储,当我们断电或关机后,内存中数据会丢失,当我们需要将某个状态存储,我们就会用到对象持久化。对象持久化有以下几种方式:扁平文件、pickle、shelve、数据库、DRM
1.扁平文件
使用文件将当前运行状态存储下来,这种方式容易出错,实际开发中不常用
eval( ):python 内置函数,可以将字符串转为python表达式
scores=[88,99,77,55]
def write_scores():
with open('data_list.txt','w',encoding='utf8') as f:
f.write(str(scores))
print('文件写入完成')
def read_scores():
with open('data_list.txt','r',encoding='utf8') as f:
lst=eval(f.read())
2.pickle应用
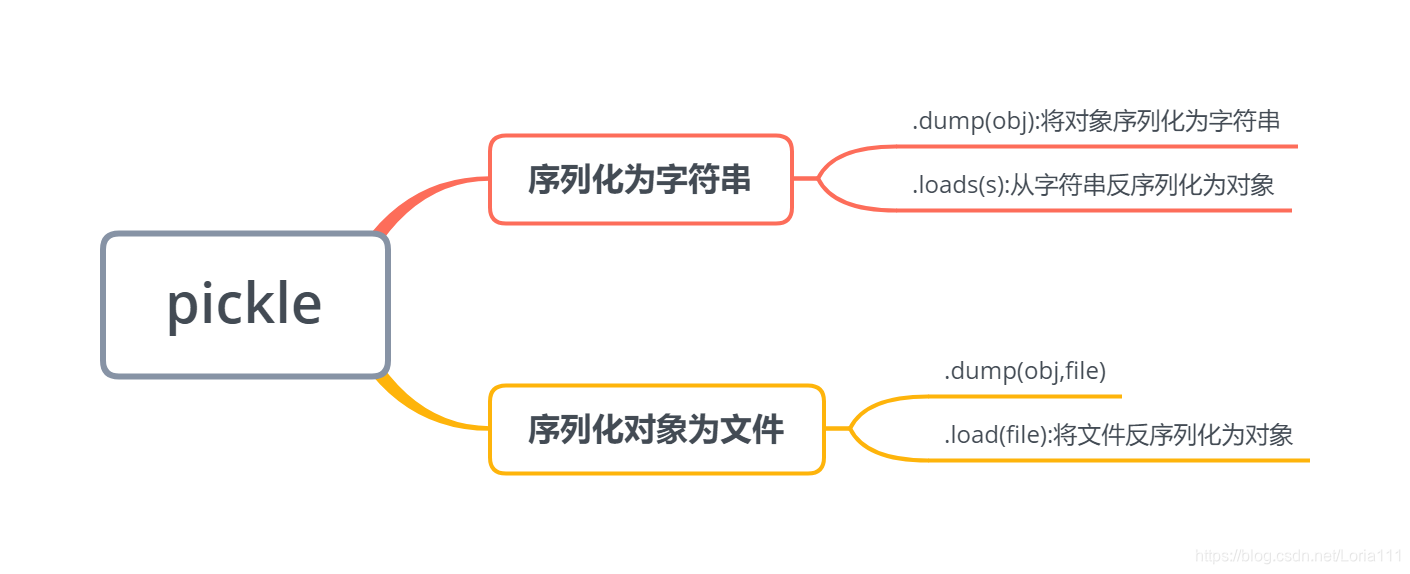
import pickle
s=pickle.dumps(person)
p=pickle(s)
pickle.dump(person.open('pickle_db','wb'))
p=pickle.load(open('pickle_db','rb'))
3.shelve
可以将多个对象存入一个文件,并从文件中将多个对象分离出来
import shelve
scores=[99,88,77]
student={'name':'Mike','age':20}
db=shelve.open('shelve_student') //声明一个数据库
db['s']=student
db['scores']=scores
>>>len(db)
2
>>>temp_student=db['s']
>>>temp_student
{'name':'Mike','age':20}
>>>db['scores']
[99,88,77]
>>>del db['scores'] //删除db中的scores一项
字符串
和字符串相关主要有三类,分别为str字符串、bytes字节、bytearray字节数组
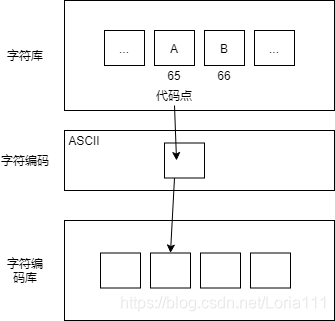
乱码原因:编码和解码所用字符编码不同
字符编码结构:字符集:赋值一个编码到某个字符,以便在内存中表示
编码encoding:转换字符到原始字节形式
节码decoding:依据编码名称转换原始字节到字符的过程
字符串存储:编码值作用于文件存储或中间媒介转换时,内存中总是存储解码以后的文本。
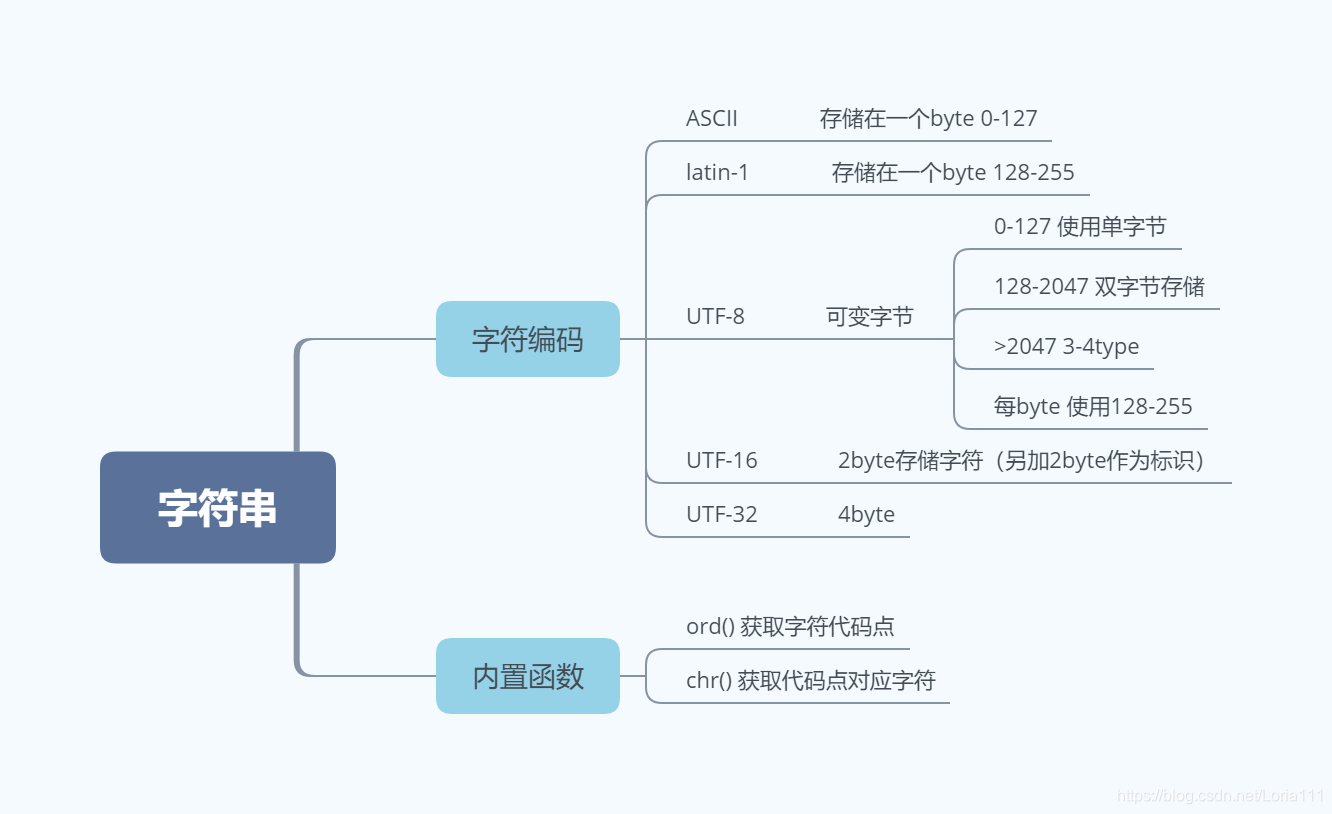
字符串、字节、字节数组之间的转换
1.字符串与字节之间的转换
主要有三种方式:
手动声明:b’’
字符出编码:str.encode()
构造函数:bytes()
open('data.txt','rb').read() //文件以二进制读取
b=b'abc'
s1='abc'
s1.encode('ASCII')
bytes('abc','ascii')
【注】字节不支持原位改变
2.字符串与字节数组之间的转换
bytearray(‘字符’,‘编码’)
bytearray.decode():解码为字符串
>>>s1='abc'
>>>ba=bytearry(s,'utf8')
>>>ba[0]
97
>>>ba[0]=98
>>>ba
bytearray(b'bbc')
>>>ba.decode('utf8')
【注】字节数组支持原位改变
BOM处理
BOM即byte order mark 字节顺序标识
open('data.txt','r',encoding='utf-8-sig').read() //-sig表示文件中若有标记,忽略它
open('data.txt','w',encoding='utf-8-sig').write('abc') //-sig表示写文件是加入字节标记

















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









