






一、背景
需要翻译srt文件内容时发现需要太多的人力消耗,这边提供了简单的三种方式
二、前期准备
1、翻译方法:机翻,人工翻译 API 服务等
2、了解市面上已有的api接口及一些相关报价内容,按需选择
3、确认自己应用场景
4、了解LLM模型,向量模型等内容
三、相关平台
1、独立平台
百度、腾讯、阿里、谷歌、DeepL、微软、Amazon Translate、Yandex、讯飞等翻译,这些都有一些免费额度,具体收费标准可以参考这个链接
2、聚合平台
3、LLM大模型
-
打破语言障碍:LLM 通过提供准确且与上下文相关的翻译来打破语言障碍,能够将一种语言的文本准确地翻译成另一种语言,使不同语言的人们能够更好地交流和理解。
-
提供多语言功能:许多 LLM 经过多语言数据集的训练,具备处理多种语言的能力,为用户提供多语言翻译服务,支持不同语言之间的相互转换。
-
灵活性高:传统的基于规则的翻译方法不灵活,难以处理复杂的语言结构和多义性。而 LLM 基于大规模数据训练,能够学习到丰富的语言模式和语义信息,更灵活地处理各种复杂的语言情况,包括习语、隐喻、模糊语义等。
-
低资源语言处理能力强:统计机器翻译方法对于低资源语言翻译效果不佳,而 LLM 由于其大规模的预训练和泛化能力,在低资源语言翻译任务上也能取得较好的效果,因为它可以利用在其他丰富资源语言上学习到的知识来辅助低资源语言的翻译。
-
翻译中的应用方式:包括参数微调和上下文学习,在使用 LLM 进行翻译时,可以对模型的参数进行微调,使其适应特定的翻译任务和领域。系统会分析输入的源语言内容,尝试找到类似的源语言内容片段及其对应的翻译示例,然后创建一个包含待翻译内容和示例的提示,让 LLM 根据这些示例即时学习并生成高质量的翻译。这种方式对翻译的流畅性、语气和术语一致性有积极影响,且只需少量示例就能发挥作用。
四、实现方式
1、代码调用API
以openai为例,代码内容如下
import openai
# 设置 OpenAI API 密钥
openai.api_key = 'org-aaaaaaaaaaaaaaaaaaaaaaaaaa'
def translate_text(text, from_lang='auto', to_lang='zh'):
prompt = f"将以下 {from_lang} 文本翻译成 {to_lang}: {text}"
try:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个专业的翻译助手。"},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content.strip()
except Exception as e:
print(f"发生错误: {e}")
return None
def translate_srt_file(input_file, output_file, from_lang='auto', to_lang='zh'):
with open(input_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
translated_lines = []
current_text = ''
for line in lines:
if line.strip().isdigit() or '-->' in line or line.strip() == '':
if current_text:
translated_text = translate_text(current_text, from_lang, to_lang)
if translated_text:
translated_lines.append(translated_text + '\n')
current_text = ''
translated_lines.append(line)
else:
current_text += line.strip() + ' '
if current_text:
translated_text = translate_text(current_text, from_lang, to_lang)
if translated_text:
translated_lines.append(translated_text + '\n')
with open(output_file, 'w', encoding='utf-8') as f:
f.writelines(translated_lines)
# 使用示例
input_file = 'Subtitle 1.srt'
output_file = 'output.srt'
translate_srt_file(input_file, output_file)
2、可视化翻译
-
在线翻译软件

-
界面参考
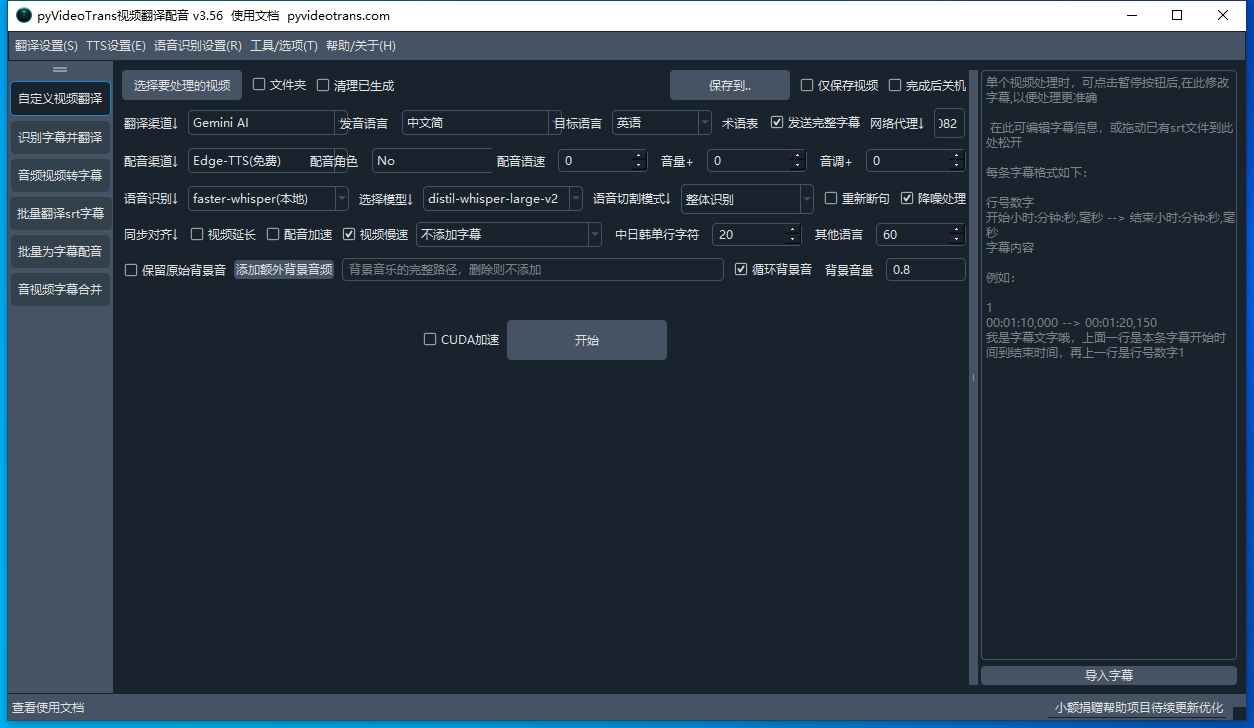
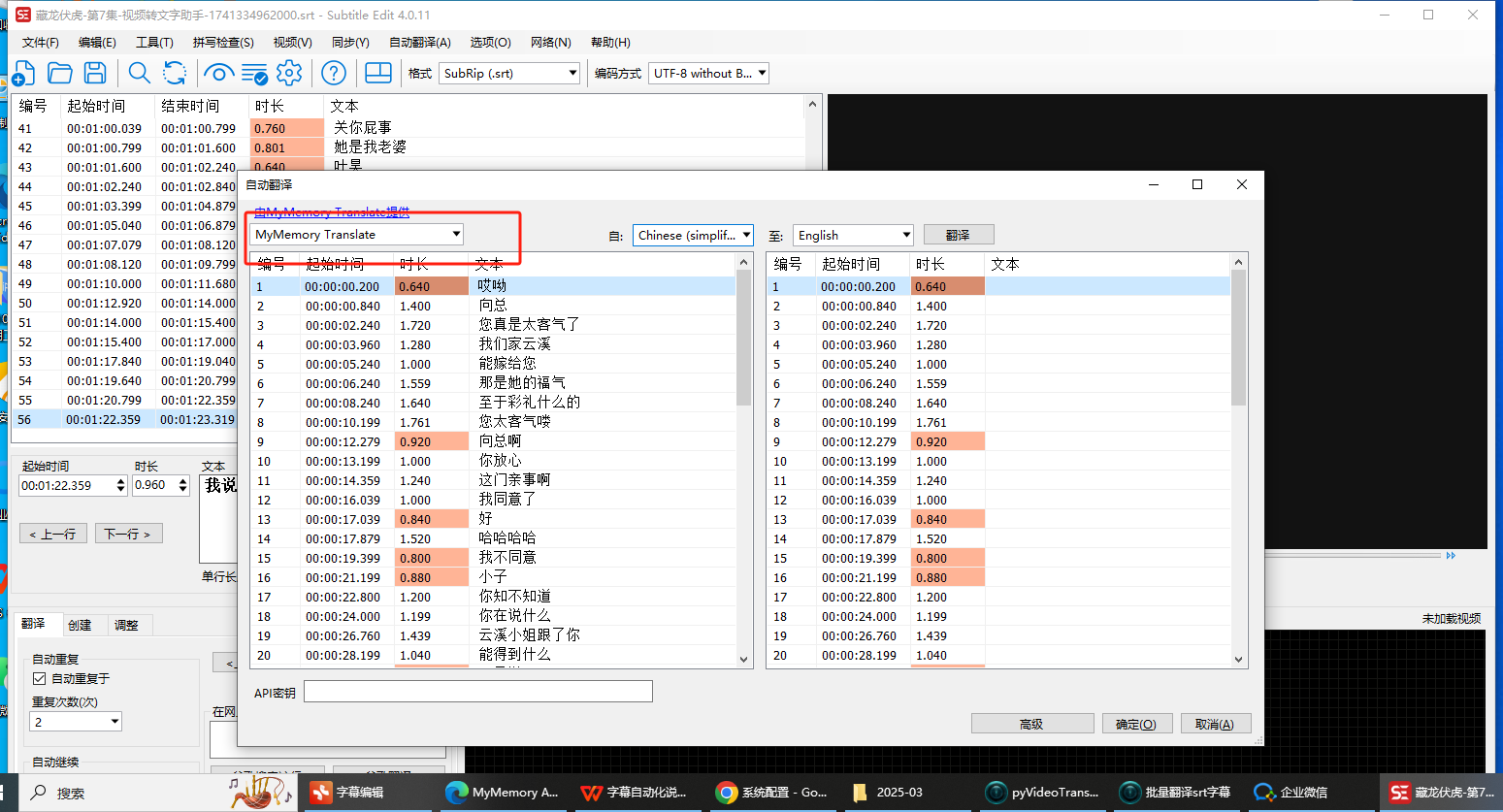
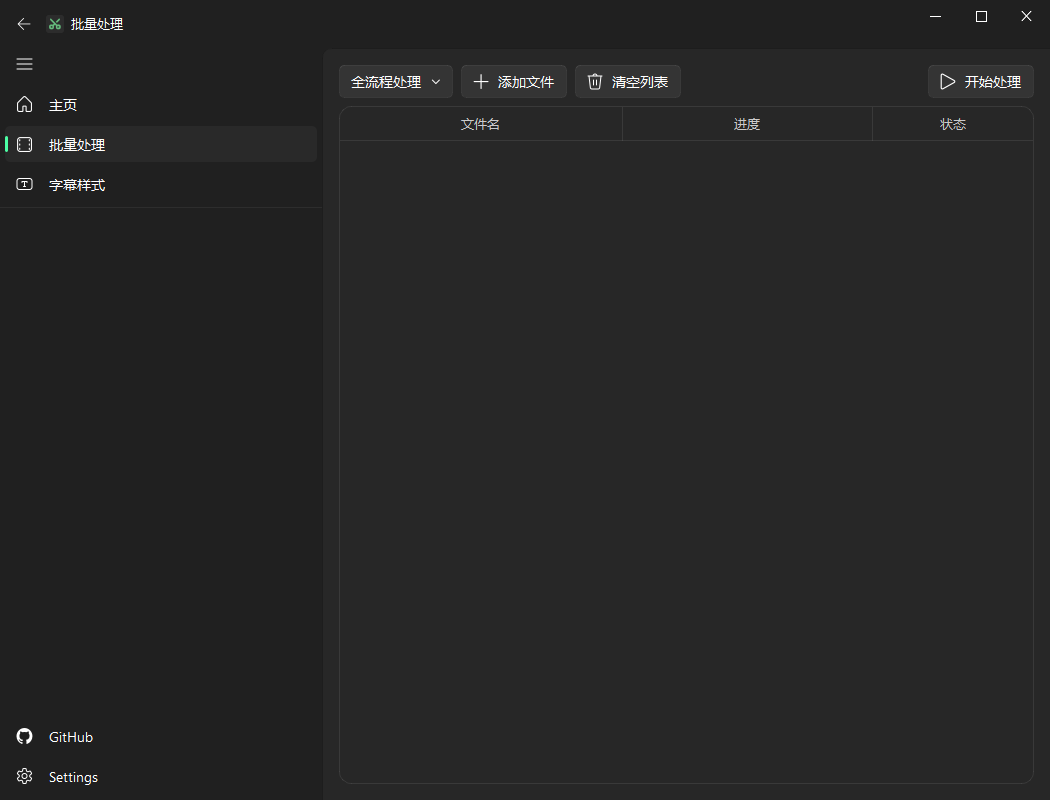
-
翻译案例线路

此处我应用场景是字幕,翻译效果OK的有以下内容的API
3、本地模型
此处为本地模型:ollama为例,参考以下链接,此处就不展开阐述了
https://www.cnblogs.com/xiezhr/p/18712410 <-部署
https://blog.youkuaiyun.com/weixin_42007999/article/details/145455592 <-调用
https://gitcode.com/gh_mirrors/oll/ollama/blob/main/docs/api.md?utm_source=csdn_github_accelerator#generate-embedding<-调用的api方法
五、其他
上面说的三种方法之外还有一些云部署的案例,比如说把去阿里服务器购买对应的服务器后部署所有模型到自己的机子上,实现了私密云部署

















 2627
2627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









