




 本文详细解析了Ribbon负载均衡的工作原理与实现机制,包括负载均衡流程、Ribbon的实现方式及多种负载均衡策略。
本文详细解析了Ribbon负载均衡的工作原理与实现机制,包括负载均衡流程、Ribbon的实现方式及多种负载均衡策略。
1、负载均衡流程
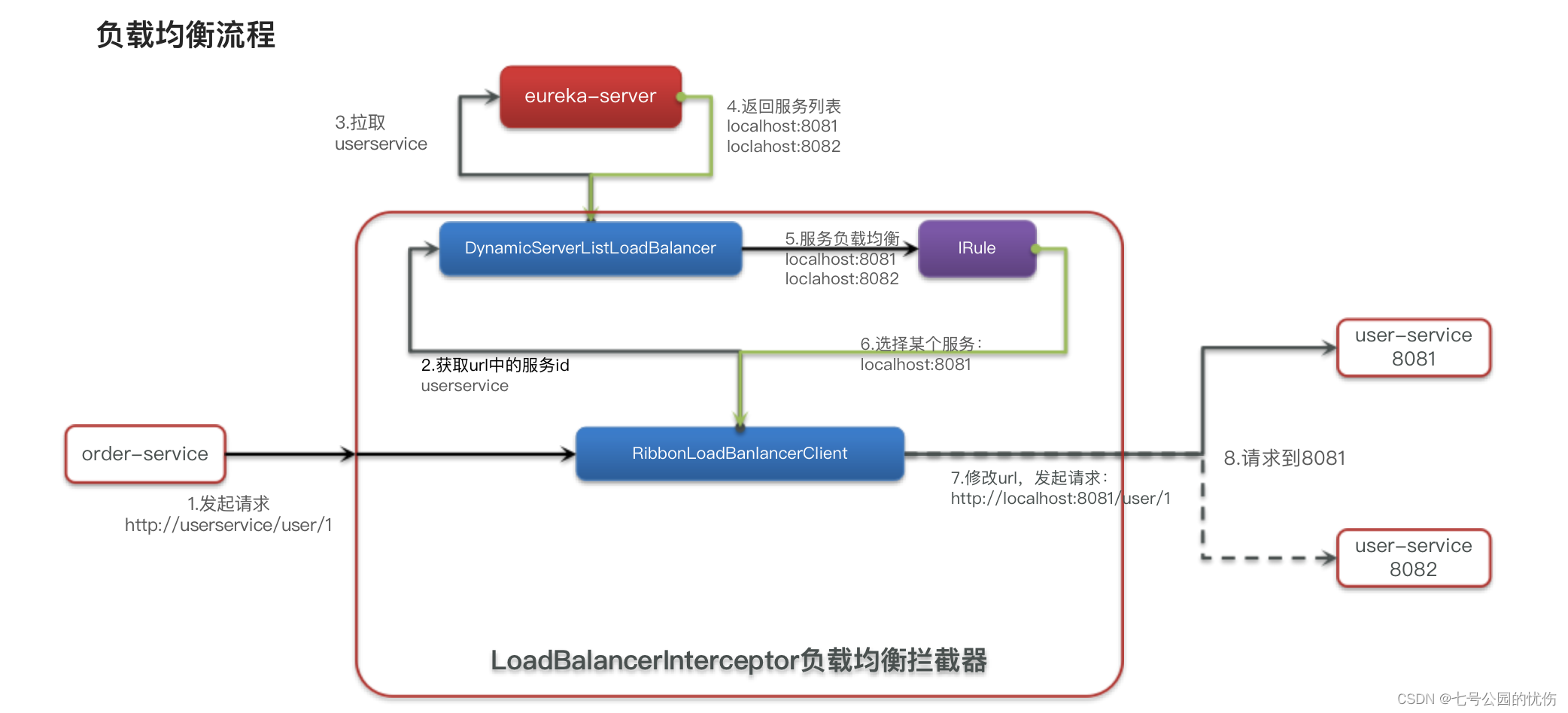
1.orde-service发起请求经过Ribbon
2.Ribbon到eureka-server中拉取服务列表
3.Ribbon负载均衡选择服务
4.然后修改请求url,将服务名替换为真正的url地址发起请求。
2、Ribbon负载均衡实现
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {
@Override
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body,
final ClientHttpRequestExecution execution) throws IOException {
final URI originalUri = request.getURI();
String serviceName = originalUri.getHost();
Assert.state(serviceName != null,
"Request URI does not contain a valid hostname: " + originalUri);
return this.loadBalancer.execute(serviceName,
this.requestFactory.createRequest(request, body, execution));
}
}
LoadBalancerInterceptor实现了ClientHttpRequestInterceptor接口,这个接口会拦截客户端的http请求。
所以客户端请求先会经过intercept方法,从代码看出,获取服务名称,然后调用loadBalancer的execute方法。
这里调用的是RibbonLoadBalancerClient的下面方法:
public <T> T execute(String serviceId, LoadBalancerRequest<T> request, Object hint)
throws IOException {
//获取服务列表
ILoadBalancer loadBalancer = getLoadBalancer(serviceId);
//负载均衡,取出一个
Server server = getServer(loadBalancer, hint);
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonServer ribbonServer = new RibbonServer(serviceId, server,
isSecure(server, serviceId),
serverIntrospector(serviceId).getMetadata(server));
return execute(serviceId, ribbonServer, request);
}
然后经过以下方法,调用rule.choose方法,这里的key是“default”字符串
public Server chooseServer(Object key) {
if (counter == null) {
counter = createCounter();
}
counter.increment();
if (rule == null) {
return null;
} else {
try {
return rule.choose(key);
} catch (Exception e) {
logger.warn("LoadBalancer [{}]: Error choosing server for key {}", name, key, e);
return null;
}
}
}
rule是一个接口,有很多实现类,用来定义选择服务的规则,比如随机、轮询等。
3、Ribbon Rule详解
rule关系图如下:
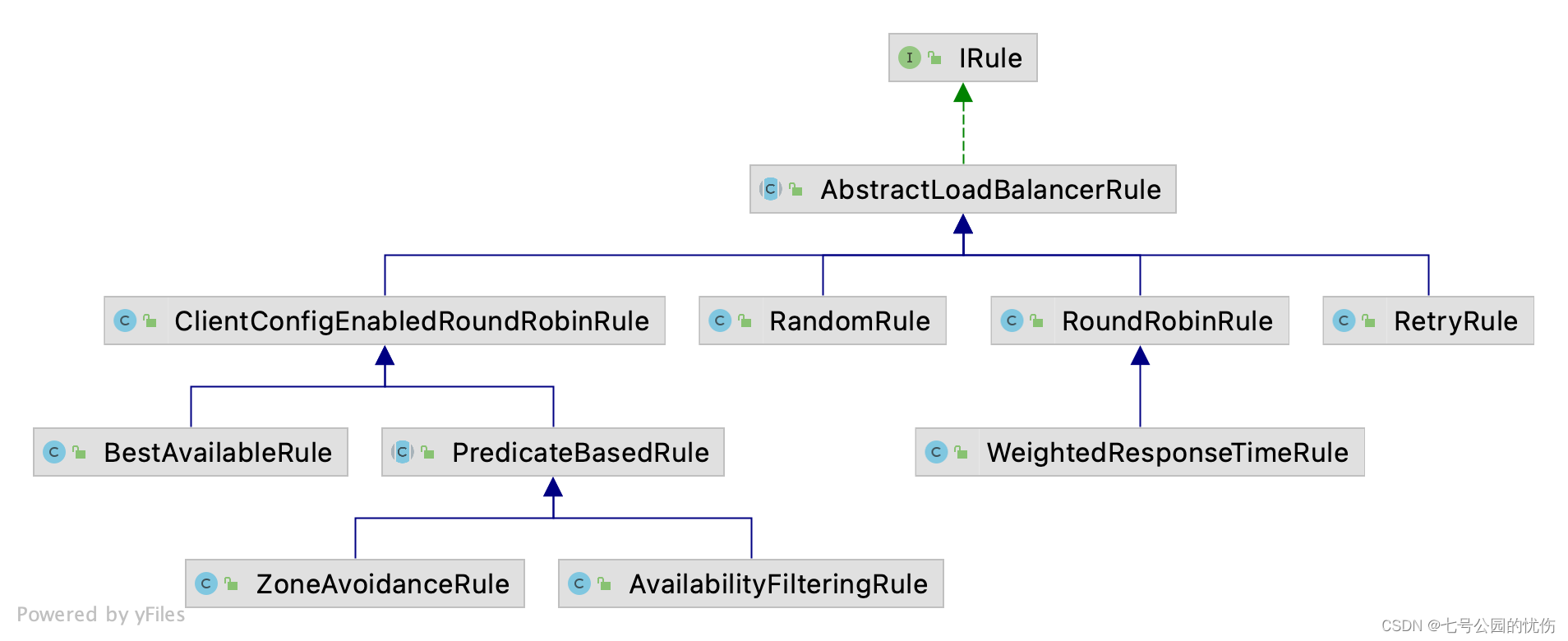
从名字我们就可以推断出这些选择器的作用:
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RetryRule | 重试机制的选择逻辑 |
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| RandomRule | 随机选择一个可用的服务器。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。(2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的..ActiveConnectionsLimit属性进行配置。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
3.1、IRule接口
public interface IRule{
public Server choose(Object key);
public void setLoadBalancer(ILoadBalancer lb);
public ILoadBalancer getLoadBalancer();
}
这个接口只有3个方法,第一个用来拿到服务。剩下两个用来关联LoadBalancer
3.2、RetryRule
public class RetryRule extends AbstractLoadBalancerRule {
IRule subRule = new RoundRobinRule();
long maxRetryMillis = 500;
}
RetryRule值放出了两个属性,一个是子规则,另一个是最大重试时间。
获取服务的方法choose主要做的事就是,一直循环调用子规则获取服务,如果获取到则返回。
如果获取不到,在超时时间之后,返回null。
3.3、RoundRobinRule
轮循RobinRule也很简单。
private AtomicInteger nextServerCyclicCounter;
大概是这样的,每次将AtomicInteger值+1,获取服务列表list,然后和所有的对所有的服务数取余,然后再去list中取出服务返回。
3.4 WeightedResponseTimeRule
别人的设计:
这个的逻辑就是,首先初始化好每个节点的平均响应时间,作为权重,然后响应时间越短,被访问的概率越大。
这个权重的设计很巧妙,这里说明下。
假设某个服务有三个节点,每个节点的相应时间分别是1秒,2秒,3秒,这个类是这样做的:
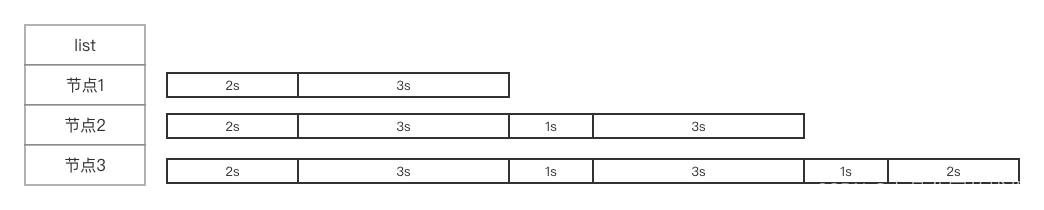
有一个节点列表:节点1、节点2、节点3
然后有一个时间列表:a[0] = 节点1时间+节点2时间,a[1] = a[0]+节点1+节点3,a[2] = a[1] + 节点1+节点2
结果就是上图的样子,以a[2]算随机数rm,a[0] >= rm那么就是节点1,a[1] >= rm那么就是节点2,a[2] >= rm就是节点3.
思路:
这样想比较难。
我们换个思路,我们把时间画出区域,假如时间越短,概率越小,我们只需要下图这样。

图中各个地方访问概率相同,随机落在1、2、3上的概率分别是1/6 2/6 3/6。正好是时间越短,概率越小。
这个类用是逆思路,如果落在了2、3上,那么作为节点1的概率: 5/6
落在13上作为节点2的概率:4/6
落在12上作为节点3的概率:3/6
这个类上算出的三个节点的比率和正常的比率是一样的:
512:412:312=56:46:36
\frac{5}{12} : \frac{4}{12} : \frac{3}{12} = \frac{5}{6} : \frac{4}{6} : \frac{3}{6}
125:124:123=65:64:63
感觉真是巧妙。
3.4 RandomRule
protected int chooseRandomInt(int serverCount) {
return ThreadLocalRandom.current().nextInt(serverCount);
}
主要逻辑就是获取一个随机数,然后从从服务列表List中拿到服务。
3.5 ClientConfigEnabledRoundRobinRule
public class ClientConfigEnabledRoundRobinRule extends AbstractLoadBalancerRule {
RoundRobinRule roundRobinRule = new RoundRobinRule();
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
roundRobinRule = new RoundRobinRule();
}
@Override
public void setLoadBalancer(ILoadBalancer lb) {
super.setLoadBalancer(lb);
roundRobinRule.setLoadBalancer(lb);
}
@Override
public Server choose(Object key) {
if (roundRobinRule != null) {
return roundRobinRule.choose(key);
} else {
throw new IllegalArgumentException(
"This class has not been initialized with the RoundRobinRule class");
}
}
}
从名字可以看出,客户端配置启用轮询。
没有什么特别地方,给定的默认规则是轮训,主要得看子类的实现。
3.6 BestAvailableRule
@Override
public Server choose(Object key) {
if (loadBalancerStats == null) {
return super.choose(key);
}
List<Server> serverList = getLoadBalancer().getAllServers();
int minimalConcurrentConnections = Integer.MAX_VALUE;
long currentTime = System.currentTimeMillis();
Server chosen = null;
for (Server server: serverList) {
ServerStats serverStats = loadBalancerStats.getSingleServerStat(server);
if (!serverStats.isCircuitBreakerTripped(currentTime)) {
int concurrentConnections = serverStats.getActiveRequestsCount(currentTime);
if (concurrentConnections < minimalConcurrentConnections) {
minimalConcurrentConnections = concurrentConnections;
chosen = server;
}
}
}
if (chosen == null) {
return super.choose(key);
} else {
return chosen;
}
}
主要代码逻辑是,第13行到第16行,选择了请求数最小的一个服务返回。
到这我们就能明白ClientConfigEnabledRoundRobinRule是什么意思了:由客户端决定是使用客户端自己的,还是使用轮询。
3.7 PredicateBasedRule
public abstract class PredicateBasedRule extends ClientConfigEnabledRoundRobinRule {
public abstract AbstractServerPredicate getPredicate();
@Override
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
if (server.isPresent()) {
return server.get();
} else {
return null;
}
}
}
这是个抽象类,主要是有个断言,需要子类来实现,然后先用子类的断言规则去过滤,最后通过轮训在剩下的服务中选择。
3.8 AvailabilityFilteringRule
public AvailabilityFilteringRule() {
super();
predicate = CompositePredicate.withPredicate(new AvailabilityPredicate(this, null))
.addFallbackPredicate(AbstractServerPredicate.alwaysTrue())
.build();
}
这个子类的断言规则是如下:
@Override
public boolean apply(@Nullable PredicateKey input) {
LoadBalancerStats stats = getLBStats();
if (stats == null) {
return true;
}
//如果短路或者请求数超出限制,返回false.
return !shouldSkipServer(stats.getSingleServerStat(input.getServer()));
}
//如果短路或者请求数超出限制,返回true.
private boolean shouldSkipServer(ServerStats stats) {
if ((CIRCUIT_BREAKER_FILTERING.get() && stats.isCircuitBreakerTripped())
|| stats.getActiveRequestsCount() >= activeConnectionsLimit.get()) {
return true;
}
return false;
}
1.首先轮训的方式选择服务,如果符合上面的断言,则返回,不符合,继续轮询选择进行断言。
2.超出10次后,调用上面介绍的父类PredicateBasedRule的方法获取。
@Override
public Server choose(Object key) {
int count = 0;
Server server = roundRobinRule.choose(key);
while (count++ <= 10) {
if (predicate.apply(new PredicateKey(server))) {
return server;
}
server = roundRobinRule.choose(key);
}
return super.choose(key);
}
3.9 ZoneAvoidanceRule
private CompositePredicate compositePredicate;
public ZoneAvoidanceRule() {
super();
ZoneAvoidancePredicate zonePredicate = new ZoneAvoidancePredicate(this);
AvailabilityPredicate availabilityPredicate = new AvailabilityPredicate(this);
compositePredicate = createCompositePredicate(zonePredicate, availabilityPredicate);
}
这个类没有choose方法,说明是使用父类的方法,先断言过滤,然后剩下的服务中轮询选择。
这个类添加了2个断言,第一个是地区选择,第二个是3.8所说的断言。
我们看看如何过滤掉不可用的地区:
//snapshot地区为key,value为每个地区下的节点信息list
//triggeringLoad触发选择,默认值为0.2d
//triggeringBlackoutPercentage:短路百分比,默认值为:0.99999d
public static Set<String> getAvailableZones(
Map<String, ZoneSnapshot> snapshot, double triggeringLoad,
double triggeringBlackoutPercentage) {
if (snapshot.isEmpty()) {
return null;
}
//可用地区集合
Set<String> availableZones = new HashSet<String>(snapshot.keySet());
if (availableZones.size() == 1) {
return availableZones;
}
//最差地区集合
Set<String> worstZones = new HashSet<String>();
//循环地区的过程中存放最大的 地区平均节点请求数
double maxLoadPerServer = 0;
//标志,是否有不可用的地区
boolean limitedZoneAvailability = false;
//循环每个地区
for (Map.Entry<String, ZoneSnapshot> zoneEntry : snapshot.entrySet()) {
String zone = zoneEntry.getKey();//地区名
ZoneSnapshot zoneSnapshot = zoneEntry.getValue();//地区下的节点信息
//节点数
int instanceCount = zoneSnapshot.getInstanceCount();
if (instanceCount == 0) {
//当前地区没有节点,从可用地区集合中移除该地区。
availableZones.remove(zone);
limitedZoneAvailability = true;//标志位设为true.
} else {
//未短路节点的平均请求数
double loadPerServer = zoneSnapshot.getLoadPerServer();
//短路的节点数/所有节点数 >= 0.99999d || 未短路节点的平均请求数 < 0
if (((double) zoneSnapshot.getCircuitTrippedCount())
/ instanceCount >= triggeringBlackoutPercentage
|| loadPerServer < 0) {
//当前地区不可用,从可用地区中去除
availableZones.remove(zone);
limitedZoneAvailability = true;
} else {
//当前行到49行,就是根据每个地区的未短路节点的平均请求数,选择请求数最大的放入最差地区集合中。
//如果2个地区很接近,那么都是最差的。
if (Math.abs(loadPerServer - maxLoadPerServer) < 0.000001d) {
worstZones.add(zone);
} else if (loadPerServer > maxLoadPerServer) {
maxLoadPerServer = loadPerServer;
worstZones.clear();
worstZones.add(zone);
}
}
}
}
//地区中最大的平均请求数 < 0.2 && 没有不可用地区
if (maxLoadPerServer < triggeringLoad && !limitedZoneAvailability) {
return availableZones;
}
//从最差地区中随机去除一个,有多个,也只去除一个。
String zoneToAvoid = randomChooseZone(snapshot, worstZones);
if (zoneToAvoid != null) {
availableZones.remove(zoneToAvoid);
}
return availableZones;
}


















 7565
7565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











