







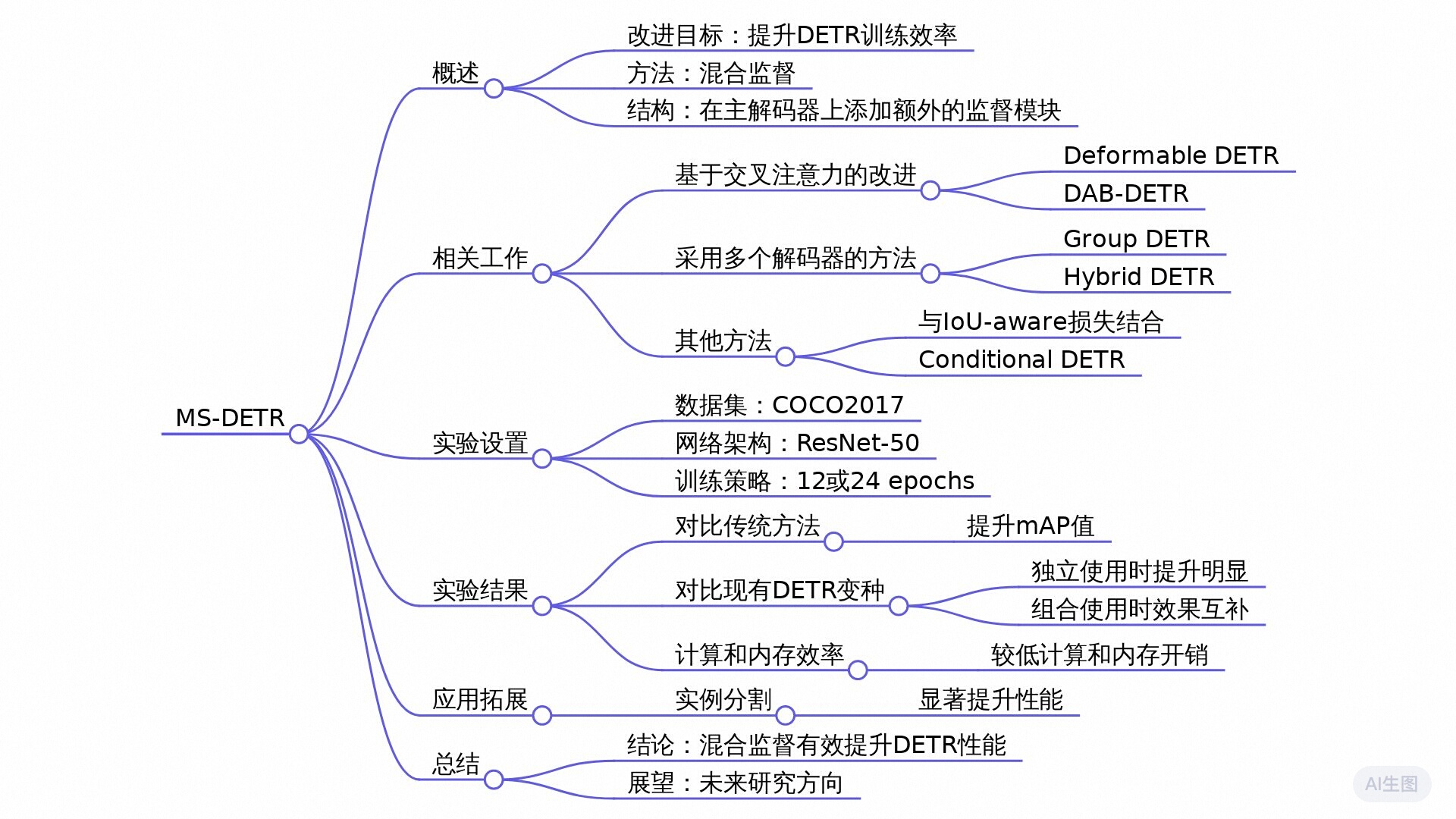
| 论文标题 | MS-DETR: Efficient DETR Training with Mixed Supervision |
|---|---|
| 论文作者 | Chuyang Zhao, Yifan Sun, Wenhao Wang, Qiang Chen, Errui Ding, Yi Yang, Jingdong Wang |
| 发表日期 | 2024年01月01日 |
| GB引用 | > Zhao Chuyang, Sun Yifan, Wang Wenhao, et al. MS-DETR: Efficient DETR Training with Mixed Supervision[J]. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2024: 17027-17036. |
| DOI | 10.1109/CVPR52733.2024.01611 |
论文地址:https://arxiv.org/pdf/2401.03989
摘要
本文提出了一种名为MS-DETR的方法,通过混合一对一和一对多监督来提高DETR模型的训练效率。与传统DETR仅使用一对一监督不同,MS-DETR在主解码器的对象查询中引入了一对多监督。实验结果显示,该方法显著提升了多个DETR变体的性能,包括DAB-DETR、Deformable DETR及其扩展版本Deformable DETR++。此外,MS-DETR在保持计算和内存效率的同时,进一步提高了与其他采用一对多监督的DETR变体结合时的性能。
全文摘要
该论文的标题为《MS-DETR: Efficient DETR Training with Mixed Supervision》。论文主要探讨了如何提升DETR(Detection Transformer)模型的训练效率,通过引入混合监督(mixed supervision)来改进其候选物体生成过程。DETR模型在物体检测中采用了迭代生成多个候选对象的方式,但其传统的训练方式依赖一对一的监督,缺乏对候选物体的直接监督。
论文的创新点在于提出了一种名为MS-DETR的方法,该方法将一对一监督与一对多监督结合,显著提高了候选物体的质量。在MS-DETR中,作者在主解码器的对象查询上直接施加了一对多的监督,而无需增加额外的解码分支或对象查询,从而简化了模型结构。实验结果表明,该方法在物体候选预测上优于其他DETR变种,尤其在与相关变种结合时,进一步提升了性能。
研究问题
如何通过混合监督提高DETR模型在训练过程中的效率和性能?
研究方法
实验研究: 通过混合一对一监督和一对多监督改进了DETR训练效率,并在多个基准上进行了验证,展示了性能提升。
混合方法研究: 该研究结合了一对一监督和一对多监督,用于优化DETR训练过程,展示了这种方法的有效性和优越性。
研究思路
论文《MS-DETR: Efficient DETR Training with Mixed Supervision》主要提出了一种新的对象检测训练方法,旨在提高DETR(Detection Transformer)的训练效率,具体研究思路如下:
该论文的理论框架基于DETR模型,DETR是一种端到端的对象检测方法,通过将图像特征与对象查询进行交互来生成多个对象候选。传统的DETR方法采用的是一对一的监督方式,即每个查询对应一个真实标签,这种方法在候选生成方面缺乏直接监督。本研究通过引入混合监督(混合一对一监督和一对多监督)来提升候选生成的质量和训练效率。
研究方法
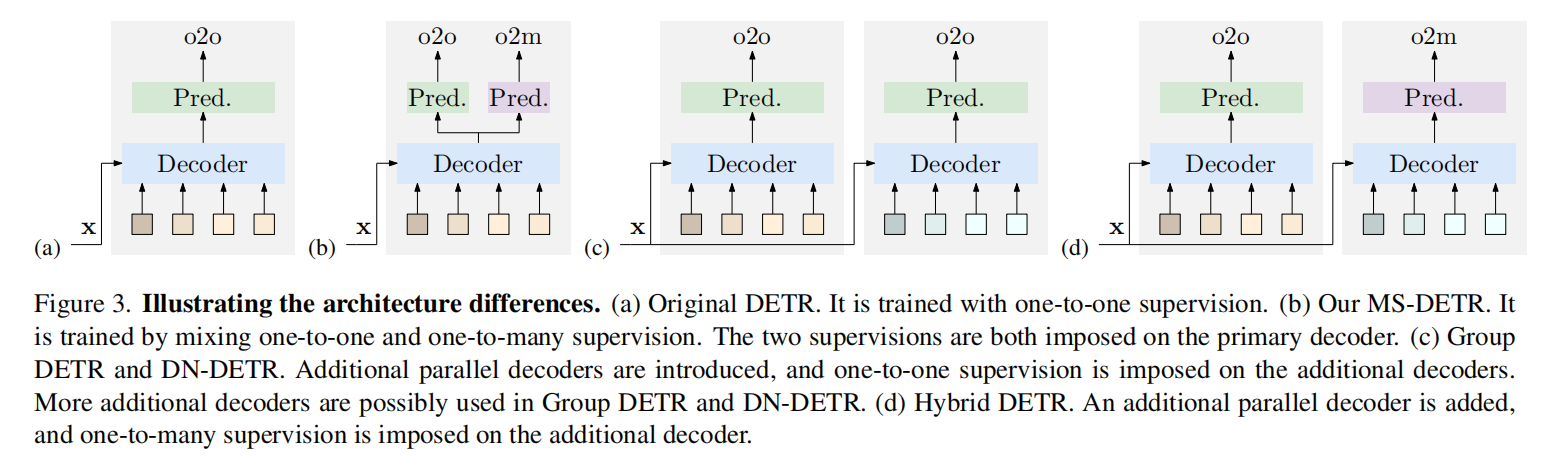
模型架构:在基本的DETR模型中,添加了一个额外的模块用于一对多的预测(one-to-many prediction)。这个模块包含框预测器和类别预测器,用于对主解码器的对象查询进行一对多监督。
监督方式:
- 一对一监督:保持了DETR中原有的一对一监督,确保每个预测与一个真实目标对应,形成标准的损失计算。
- 一对多监督:通过额外的模块,对每个真实目标分配多个预测候选,帮助模型更好地捕捉到目标的多态特征。这种方法通过引入类别分数和IoU(Intersection over Union)分数的组合匹配来实现。
候选生成和消歧:模型利用解码器的自注意力机制处理候选去重,一对一和一对多的监督共同作用于候选生成与信息聚合。
训练流程优化:针对模型的训练,使用了改进的超参数设置和匹配策略,使得训练过程更加高效且收敛更快。
DETR 架构
最初的DETR架构由CNN和变压器编码器、变压器解码器,对象类和框位置预测器组成。
输入图像 I \mathbf{I} I 通过编码器,得到图像特征:
X = Encoder ( I ) . \mathbf{X}=\operatorname{Encoder}(\mathbf{I}). X=Encoder(I).
可学习的对象查询 Q \mathbf{Q} Q 和图像特征 X \mathbf{X} X 被输入到解码器中,从而得到最终的对象查询:
Q ~ = Decoder ( Q ) . \tilde{\mathbf{Q}}=\operatorname{Decoder}(\mathbf{Q}). Q~=Decoder(Q).
对象查询通过预测器被解析为框和分类分数(分类分数是候选类别属于某一类的程度与它比其他(重复)候选类别更好的程度的结合。):
B = b o x 11 ( Q ~ ) , S = c l s 11 ( Q ~ ) . ( 1 ) \mathbf{B}=\mathrm{~box}_{11}(\tilde{\mathbf{Q}}),\quad\mathbf{S}=\mathrm{~cls}_{11}(\tilde{\mathbf{Q}}).\quad(1) B= box11(Q~),S= cls11(Q~).(1)
为了简洁起见,我们使用下标 11 和 1m 分别表示一对一和一对多。
解码器。变压器解码器是一个堆叠的解码层,主要有两个主要层:一个自注意力层,用于收集每个查询(候选)的其他查询的信息以进行重复候选删除;一个交叉注意力层,从图像特征中收集对象候选,并将其作为查询输入到 FFN 层,然后是框和类预测器。
一对一监督。原始的DETR是通过一对一监督进行训练的,一个候选预测对应于一个真实对象,反之亦然,
( y σ ( 1 ) , y ˉ 1 ) , ( y σ ( 2 ) , y ˉ 2 ) , … , ( y σ ( N ) , y ˉ N ) , ( 2 ) (\mathbf{y}_{\sigma(1)},\mathbf{\bar{y}}_1),(\mathbf{y}_{\sigma(2)},\mathbf{\bar{y}}_2),\ldots,(\mathbf{y}_{\sigma(N)},\mathbf{\bar{y}}_N),\quad(2) (yσ(1),yˉ1),(yσ(2),yˉ2),…,(yσ(N),yˉ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











