




 本文介绍了DeepLabv3+在语义图像分割中的应用,该模型结合了空间金字塔池模块和编码/解码器结构的优势。通过添加解码器模块优化分割效果,特别是对象边界的细节。文章详细阐述了DeepLabv3+的网络结构,包括深度可分离卷积的应用,并提供了PyTorch实现的代码链接。
本文介绍了DeepLabv3+在语义图像分割中的应用,该模型结合了空间金字塔池模块和编码/解码器结构的优势。通过添加解码器模块优化分割效果,特别是对象边界的细节。文章详细阐述了DeepLabv3+的网络结构,包括深度可分离卷积的应用,并提供了PyTorch实现的代码链接。
一、论文
《Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation》
摘要: 在深度神经网络中,空间金字塔池模块或编码/解码器结构用于语义分割任务。 前者网络能够通过使用过滤器或以多种速率和多个有效视场进行池化操作来探查传入特征,从而对多尺度上下文信息进行编码,而后者网络则可以通过逐渐恢复空间信息来捕获更清晰的对象边界。 在这项工作中,我们建议结合两种方法的优点。 具体而言,我们提出的模型DeepLabv3 +通过添加简单而有效的解码器模块来扩展DeepLabv3,以优化分割结果,尤其是沿对象边界的分割结果。 我们进一步探索了Xception模型,并将深度可分离卷积应用于Atrous空间金字塔池和解码器模块,从而形成了更快,更强大的编码器-解码器网络。 我们在PASCAL VOC 2012和Cityscapes数据集上证明了所提出模型的有效性,无需任何后处理即可实现89.0%和82.1%的测试集性能。 我们的论文在https://github.com/tensorflow/models/tree/master/research/deeplab上提供了Tensorflow中提出的模型的公开参考实现。
二、网路结构
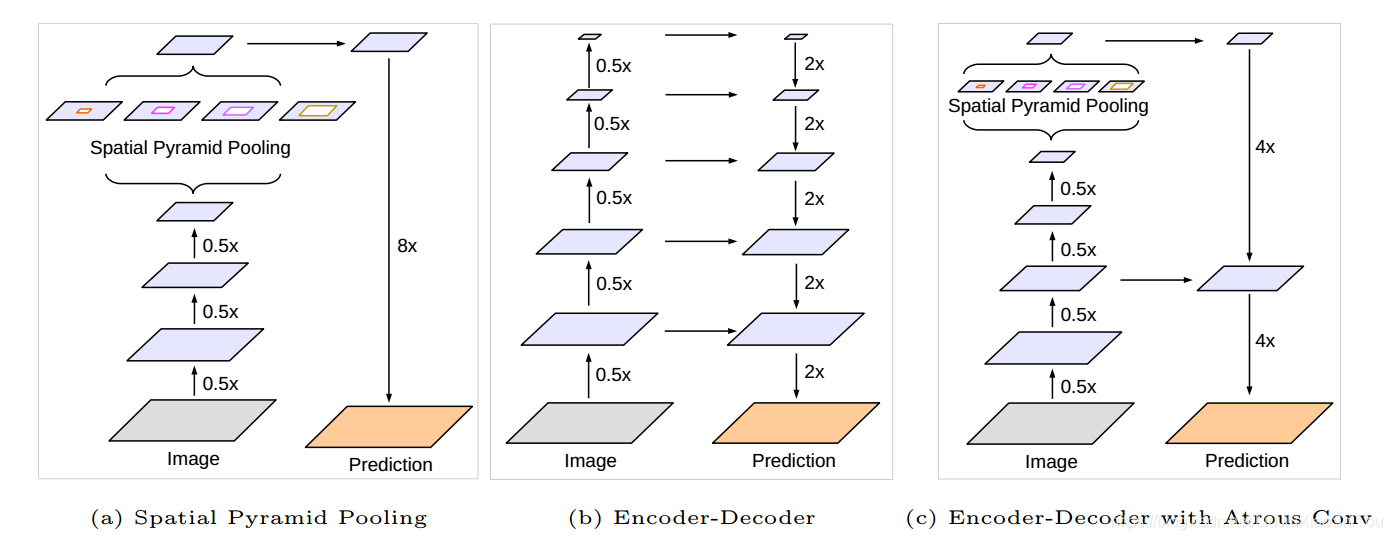
图1.我们改进了DeepLabv3,它采用了空间金字塔池模块(a)和编码器-解码器结构(b)。 提出的模型DeepLabv3 +包含来自编码器模块的丰富语义信息,而详细的对象边界由简单而有效的解码器模块恢复。 编码器模块允许我们通过应用无规则卷积以任意分辨率提取特征。
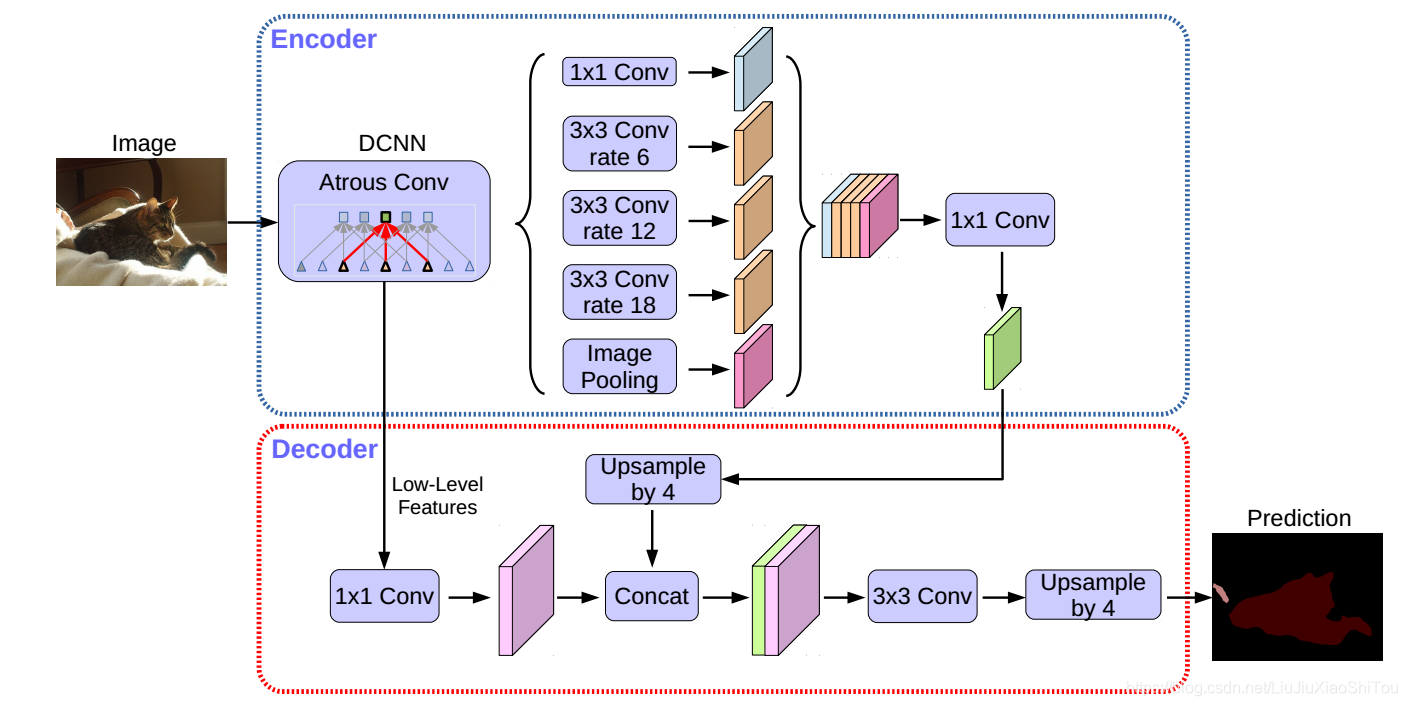
图2 我们提出的DeepLabv3 +通过采用编码器/解码器结构扩展了DeepLabv3。 编码器模块通过在多个尺度上应用无规则卷积来编码多尺度上下文信息,而简单而有效的解码器模块则沿对象边界细化分段结果。
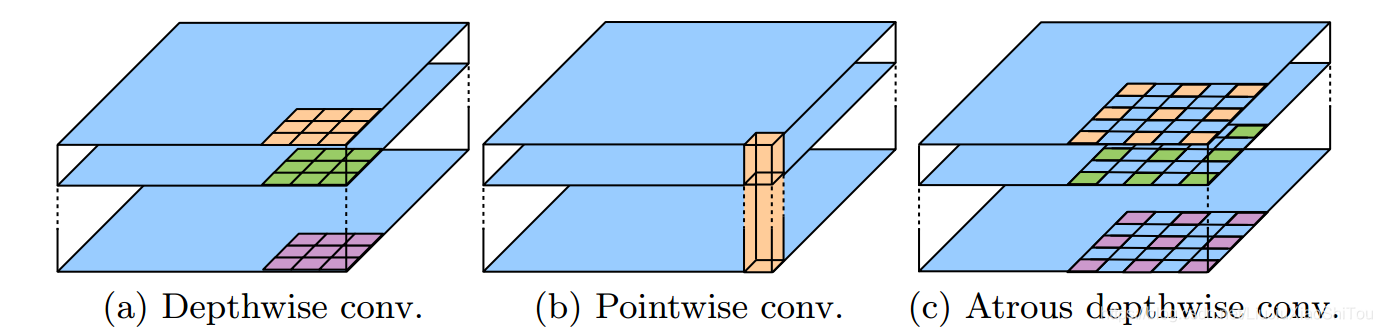
图3 3×3深度可分离卷积将标准卷积分解为(a)深度卷积(对每个输入通道应用一个滤波器)和(b)点向卷积(合并跨通道的深度卷积的输出)。 在这项工作中,我们探索了atrousable可分离卷积,其中在深度卷积中采用了atrous卷积,如(c)中所示,速率为2。
三、代码
https://github.com/VainF/DeepLabV3Plus-Pytorch/blob/master/network/_deeplab.py
import torch
from torch import nn
from torch.nn import functional as F
from .utils import _SimpleSegmentationModel
__all__ = ["DeepLabV3"]
class Deep 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2166
2166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









