




 本文介绍了如何在热更新中将旧的ini数据转换为JSON格式,通过对象替换和编程实现,然后用Node.js读取、分割和序列化数据,最终生成易于使用的JSON文件。
本文介绍了如何在热更新中将旧的ini数据转换为JSON格式,通过对象替换和编程实现,然后用Node.js读取、分割和序列化数据,最终生成易于使用的JSON文件。
应用场景
在编写热更新的时候,我发现了一个古早的 ini 文件,记录了许多有用的数据
由于使用的语言年份较新,没有办法较好地对 ini 文件的相关配置进行支持
所以把这串数据转换成 json、xml、lua 是更有效的办法!
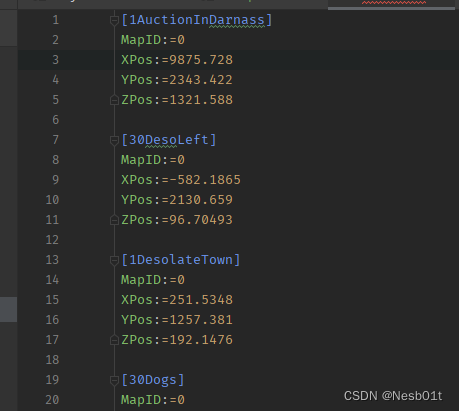
序列化 - 对象
我第一时间想到的是正则表达式,如果你熟练的话正则表达式是好的选择,但我们可以换个思路,直接处理文件后读取,相比较编程新手来说更加简单
要更改源文件时,请先做好文件备份工作~
替换原内容,方便使用
我们不妨把 “[” 和 “]” 先去掉,这样我们只要读取这一行,数据就是有效的 ID 了~

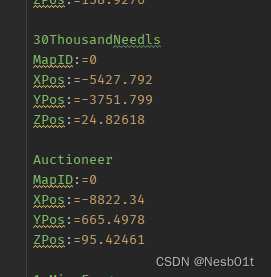
经过这样的处理我们发现碍事的只剩下下面的 MapID:= 之类的关键词了,仍然选择去掉
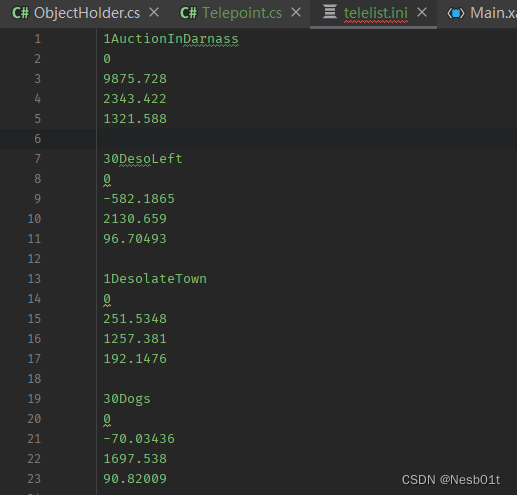
获得了这样的结果,很轻松地就可以用最原始的方法来读取入程序并序列化了!
编写程序
这里可以使用 Python、JS、C++ 等你熟悉的语言,举例用 Node.js 了~
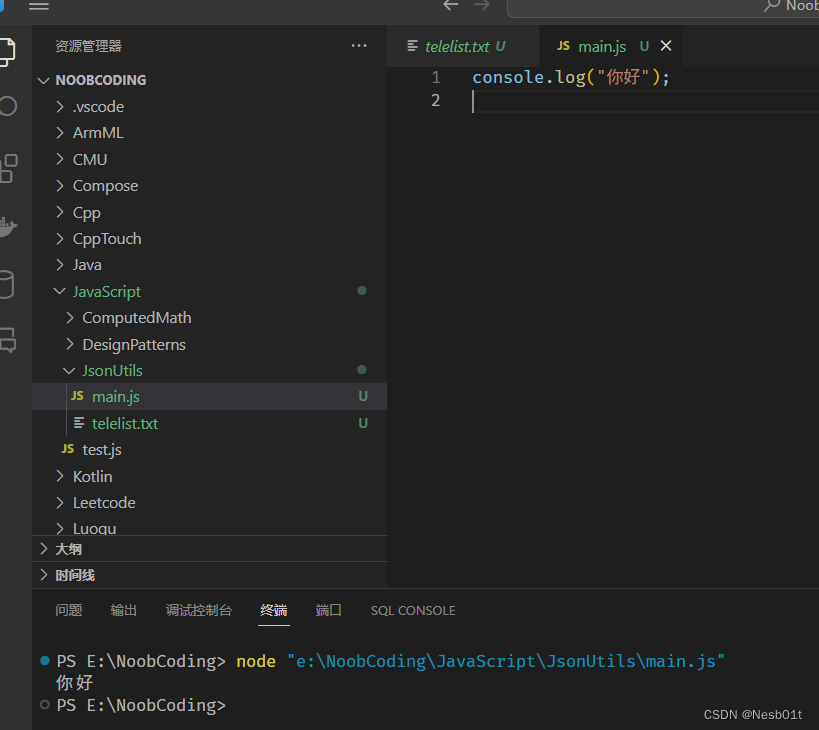
我们先把 telelist.txt 读取到 main.js 文件里面去,试着输出,是成功的:
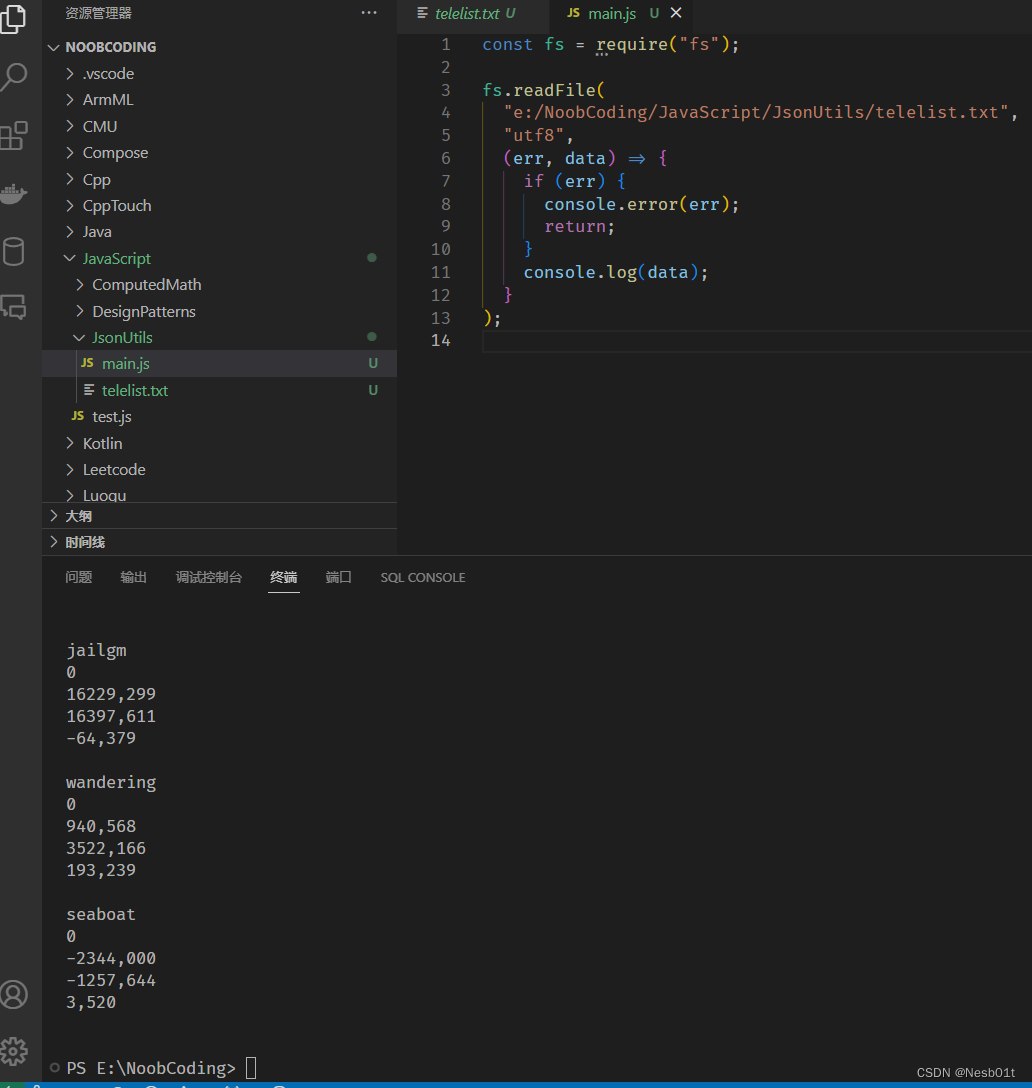
接下来用 split 进行分割,把每一行都变成一个元素,放到一个数组里面去
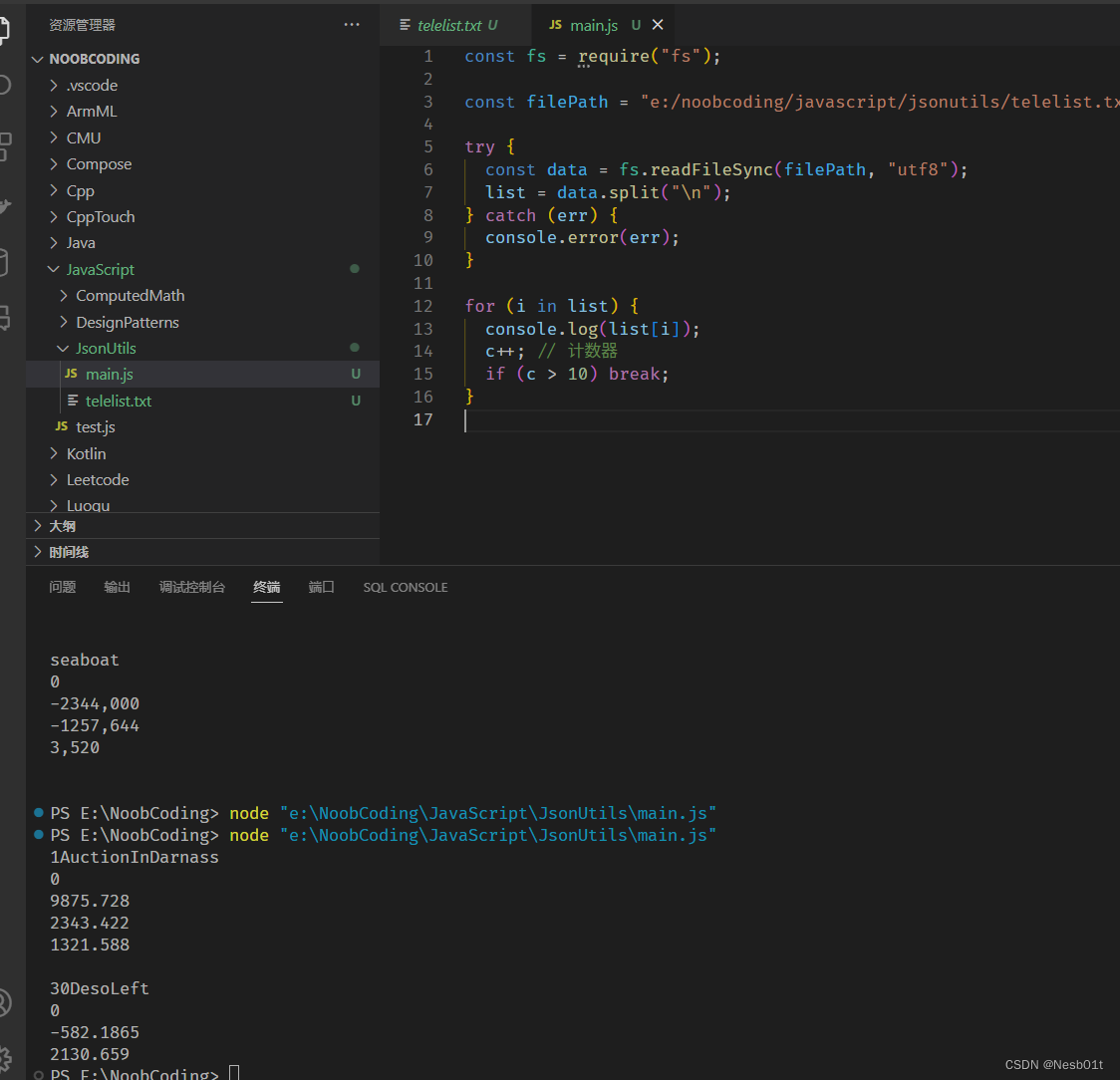
我们还要对这个巨大的数组进行切片,把他们分割成长度为 6 的小数组,然后依次把信息读入 teleObj,最后导入 teleList
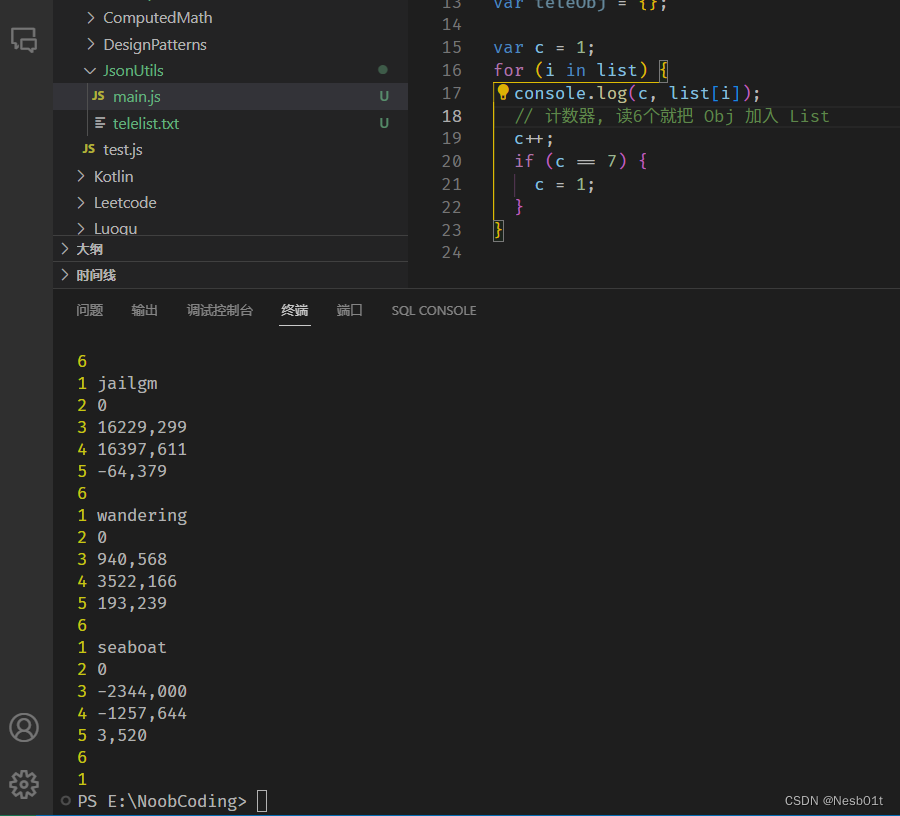
这就是把小数组完整读入的切片代码:
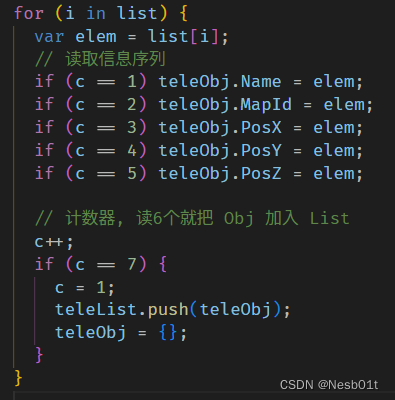
取得结果数组
进行输出,显然我们发现数据已经全部序列化成了 JS 中的对象了,这时候想要序列化成 JSON 文件就非常容易了~
注意到文件末尾还有 换行符,所以我们用 replace 再对元素筛一遍~
序列化 - JSON
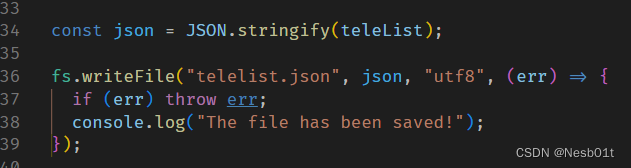
通常高级语言都有 JSON 序列化库,这样即可快速完成 JSON 序列化~
如果你有特殊的格式要求,也可以自行编写~
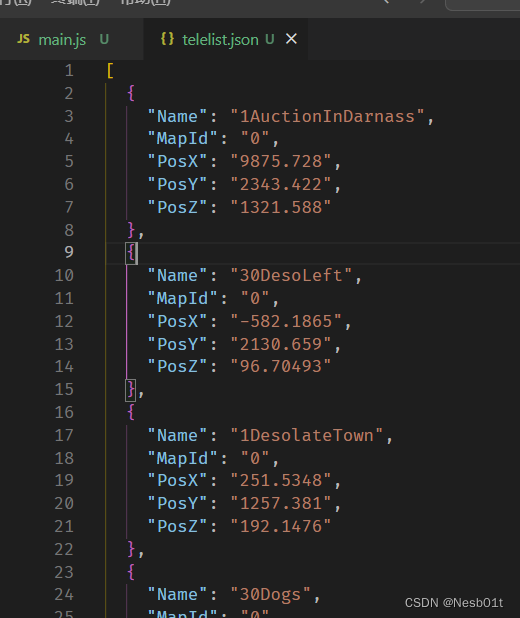
打开 .json 文件并 beautify 美化一下格式,就得到了序列化成功后的结果~

















 62
62

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









