



Python基础(二)
函数
函数的创建和调用
什么是函数
函数就是执行特定任和以完成特定功能的一段代码
为什么需要函数
-
复用代码
-
隐藏实现细节
-
提高可维护性
-
提高可读性便于调试
函数的创建
def calc(a,b): #a,b称为形式参数,简称形参 ,形参的位置是在函数的定义处
c=a+b
return c
result=calc(10,20) #10,20称为实际参数的值,简称实参,实参的位置是函数的调用处
print(result)
res=calc(b=10,a=20) # =左侧的变量的名称称为 关键字参数
print(res)
函数的调用
result=calc(10,20) #10,20称为实际参数的值,简称实参,实参的位置是函数的调用处
print(result)
函数的参数传递
- 位置实参
根据形参对应的位置进行实参传递

- 关键字实参
根据形参名称进行实参传递

函数调用的参数传递内存分析图

def fun(arg1,arg2):
print('arg1',arg1)
print('arg2',arg2)
arg1=100
arg2.append(10)
print('arg1',arg1)
print('arg2',arg2)
#return
n1=11
n2=[22,33,44]
print('n1',n1)
print('n2',n2)
fun(n1,n2) #将位置传参,arg1,arg2是函数定义处的形参,n1,n2是函数调用的处的实参,总结,实参名称与形参名称可以不一致
print('n1',n1)
print('n2',n2)
'''在函数调用过程中,进行参数的传递
如果是不可变对象, 在函数体的修改不会影响实参的值 arg1的修改为100,不会影响n1的值
如果是可变对象,在函数体的的修改会影响到实参的值 arg2的修改,append(10),会影响到n2的值
'''
函数的参数定义
- 函数定义默认值参数
函数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递实参

-
个数可变的位置参数
-
定义函数时,可能无法事先确定传递的位置实参的个数时,使用可变的位置参数
-
使用*定义个数可变的位置形参
-
结果为一个元组

-
-
个数可变的关键字形参
-
定义函数时,无法事先确定传递的关键字实参的个数时,使用可变的关键字形参
-
使用**定义个数可变的关键字形参
-
结果为一个字典

-
def fun(*args): #函数定义时的可变的位置参数
print(args)
#print(args[0])
fun(10)
fun(10,30)
fun(30,405,50)
def fun1(**args):
print(args)
fun1(a=10)
fun1(a=20,b=30,c=40)
print('hello','world','java')
'''def fun2(*args,*a):
pass
以上代码,程序会报错,个数可变的位置参数,只能是1个
def fun2(**args,**args):
pass
以上代码,程序会报错,个数可变的关键字参数,只能是1个
'''
def fun2(*args1,**args2):
pass
'''def fun3(**args1,*arg2): #报错
pass
在一个函数的定义过程中,既有个数可变的关键字形参,也有个数可变的位置形参,
要求:个数可变的位置形参放在个数可变的关键字形参之前
'''
函数的参数总结
| 序号 | 参数的类型 | 函数的定义 | 函数的调用 | 备注 |
|---|---|---|---|---|
| 1 | 位置实参 | √ | ||
| 将序列中的每个元素都转换为位置实参 | √ | 使用* | ||
| 2 | 关键字实参 | √ | ||
| 将字典中的每个键值对都转换为关键字实参 | √ | 使用** | ||
| 3 | 默认值形参 | √ | ||
| 4 | 关键字形参 | √ | 使用* | |
| 5 | 个数可变的位置形参 | √ | 使用* | |
| 6 | 个数可变的关键字形参 | √ | 使用 ** |
def fun(a,b,c): #a,b,c在函数的定义处,所以是形式参数
print('a=',a)
print('b=',b)
print('c=',c)
#函数的调用
fun(10,20,30) #函数调用时的参数传递,称为位置传参
lst=[11,22,33]
fun(*lst) #在函数调用时,将列表中的每个元素都转换为位置实参传入
print('---------------------')
fun(a=100,c=300,b=200) #函数的调用,所以是关键字实参
dic={'a':111,'b':222,'c':333}
fun(**dic) #在函数调用时,将字典中的键值对都转换为关键字实参传入
def fun(a,b=10): #b是在函数的定义处,所以b是形参,而且进行了赋值,所以b称为默认值形参
print('a=',a)
print('b=',b)
def fun2(*args): #个数可变的位置形参 参数以列表传进来
print(args)
def fun3(**args2): #个数可变的关键字形参 参数以字典传进来
print(args2)
fun2(10,20,30,40)
fun3(a=11,b=22,c=33,d=44,e=55)
'''需求,c,d只能采用关键字实参传递'''
def fun4(a,b,*,c,d): #从*之后的参数,在函数调用时,只能采用关键字参数传递
print('a=',a)
print('b=', b)
print('c=', c)
print('d=', d)
#调用fun4函数
#fun4(10,20,30,40) #位置实参传递 报错
fun4(a=10,b=20,c=30,d=40) #关键字实参传递
fun4(10,20,c=30,d=40) #前两个参数,采用的是位置实参传递,而c,d采用的是关键字实参传递
'''函数定义时的形参的顺序问题'''
def fun5(a,b,*,c,d,**args):
pass
def fun6(*args,**args2):
pass
def fun7(a,b=10,*args,**args2):
pass
函数的返回值
函数返回多个值时,结果为元组
def fun(num):
odd=[] #存奇数
even=[]#存偶数
for i in num:
if i%2:
odd.append(i)
else:
even.append(i)
return odd,even
print(fun([10,29,34,23,44,53,55]))
'''
函数的返回值
(1)如果函数没有返回值【函数执行完毕之后,不需要给调用处提供数据】 return可以省略不写
(2)函数的返回值,如果是1个,直接返回类型
(3)函数的返回值,如果是多个,返回的结果为元组
'''
def fun1():
print('hello')
#return
fun1()
def fun2():
return 'hello'
res=fun2()
print(res)
def fun3():
return 'hello','world'
print(fun3())
'''函数在定义时,是否需要返回值,视情况而定'''
变量的作用域
程序代码能访问该变量的区域
根据变量的有效范围可分为
- 局部变量
在函数内定义并使用的变量,只在函数内部有效,局部变量使用global声明,这个变量就
会成全局变量
- 全局变量
函数体外定义的变量,可作用于函数内外
def fun(a,b):
c=a+b #c,就称为局部变量,因为c在是函数体内进行定义的变量,a、b为函数的形参,作用范围也是函数内部,相当于局部变量
print(c)
#print(c) ,因为a,c超出了起作用的范围(超出了作用域)
#print(a)
name='杨老师' #name的作用范围为函数内部和外部都可以使用 -->称为全局变量
print(name)
def fun2():
print(name)
#调用函数
fun2()
def fun3():
global age #函数内部定义的变量,局部变量,局部变量使用global声明,这个变量实际上就变成了全局变量
age=20
print(age)
fun3()
print(age)
递归函数
什么是递归函数
- 如果在一个函数的函数体内调用了该函数本身,这个函数就称为递归函数
递归的组成部分
- 递归调用与递归终止条件
递归的调用过程
-
每递归调用一次函数,都会在栈内存分配一个栈帧,
-
每执行完一次函数,都会释放相应的空间
递归的优缺点
-
缺点:占用内存多,效率低下
-
优点:思路和代码简单
def fac(n):
if n == 1:
return 1
else:
res = n * fac(n-1)
return res
print(fac(6))
#斐波那契数列
def fib(n):
if n==1:
return 1
elif n==2:
return 1
else:
return fib(n-1)+fib(n-2)
#斐波那契数列第6位上的数字
print(fib(6))
print('------------------------------')
#输出这个数列的前6位上的数字
for i in range(1,7):
print(fib(i))
BUG&异常
Bug的由来及分类
世界上第一部万用计算机的进化版-马克2号(Mark II)
Bug的常见类型
-
粗心导致的语法错误 SyntaxError
(1)

(2)

(3)

-
粗心导致错误的自查宝典
-
漏了末尾的冒号,如if语句,循环语句,else子句等
-
缩进错误,该缩进的没缩进,不该缩进的瞎缩进
-
把英文符号写成中文符号,比如说:引号,冒号,括号
-
字符串拼接的时候,把字符串和数字拼在一起
-
没有定义变量,比如说while的循环条件的变量
-
“==”比较运算符和”=”赋值运算符的混用
-
-
知识不熟练导致的错误
(1)索引越界问题IndexError
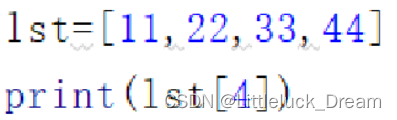
(2)append()方法的使用掌握不熟练

-
知识点不熟悉导致错误的自查宝典
-
思路不清导致的问题解决方案
(1)使用print()函数
(2)使用"#"暂时注释部分代码
-
被动掉坑:程序代码逻辑没有错,只因为用户错误操作或者一些“例外情况”而导致
程序崩溃
Python提供了异常处理机制,可以在异常出现时即时捕获,然后内部“消化”,让程序继续运行
异常处理机制
多个except结构
捕获异常的顺序按照先子类后父亲类的顺序,为了避免遗漏可能出现的异常,可以在最后增加BaseException
try:
n1=int(input('请输入一个整数:'))
n2=int(input('请输入另一个整数:'))
result=n1/n2
print(’结果为:’,result)
except ZeroDivisionError:
print(’除数不能为0哦!!!”)
except ValueError:
print(’不能将字符串转换为数字’)
except BaseException as e:
print(e)
try…except…else结构
如果try块中没有抛出异常,则执行else块,如果try中抛出异常,则执行except块
try:
n1=int(input(’请输入一个整数:’))
n2=int(input(’请输入另一个整数:’))
result=n1/n2
except BaseException as e:
print(’出错了’)
print(e)
else:
print(’结果为:,result)
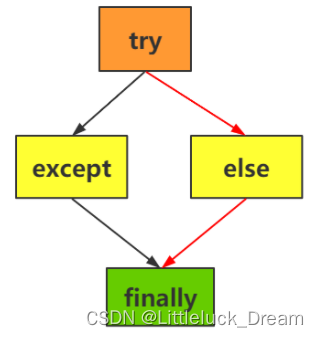
try…except…else…finally结构
finally块无论是否发生异常都会被执行,能常用来释放try块中申请的资源
try:
n1=int(input(’请输入一个整数:’))
n2=int(input(’请输入另一个整数:’))
result=n1/n2
except BaseException as e:
print(’出错了’)
print(e)
else:
print(’结果为:’,result)
finally:
print(’无论是否产生异常,总会被执行的代码’)
print(’程序结束’)
Python常见的异常类型
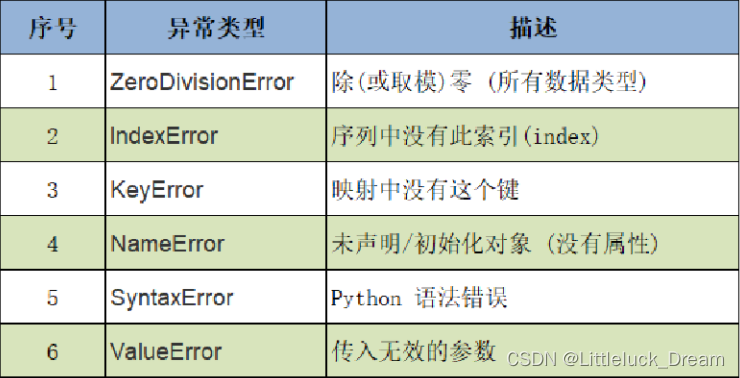
#(1)数学运算异常
#print(10/0) #ZeroDivisionError
lst=[11,22,33,44]
#print(lst[4]) #IndexError 索引从0开始
dic={'name':'张三','age':20}
#print(dic['gender']) #KeyError
#print(num) #NameError
#int a=20 #SyntaxError
#a=int('hello') #ValueError
raceback模块
使用traceback模块打印异常信息
import traceback
try:
print('1.----------')
num=10/0
except:
traceback.print_exc()
PyCharm开发环境的调试
- 断点
程序运行到此处,暂时挂起,停止执行。此时可以详细观察程序的运行情况,方便做出进一步的判断
- 进入调试视图
进入调试视图的三种方式
(1)单击工具栏上的按钮

(2)右键单击编辑区:点击:debug’模块名’
(3)快捷键:shift+F9
类与对象
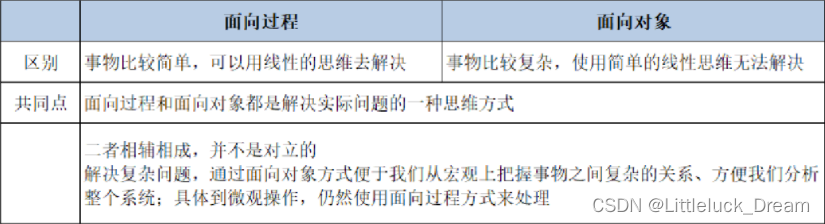
编程界的两大阵营
类
是多个类似事物组成的群体的统称。能够帮助我们快速理解和判断事物的性质
数据类型
-
不同的数据类型属于不同的类
-
使用内置函数查看数据类型

对象
100、99、520都是int类之下包含的相似的不同个例,这个个例专业数语称为实例或对象
Python中一切皆对象
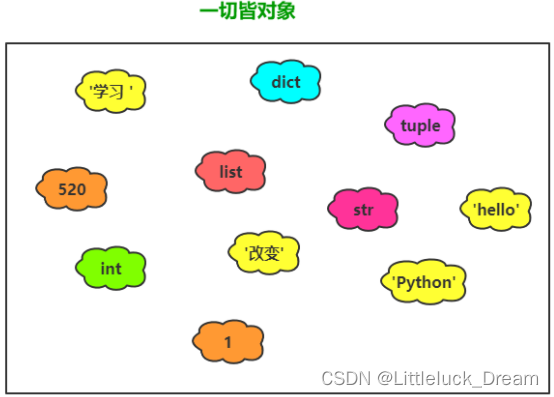
类的创建
创建类的语法

class Student: #Student为类的名称(类名)由一个或多个单词组成,每个单词的首字母大写,其余小写
pass
#Python中一切皆对象Student是对象吗?内存有开空间吗?
print(id(Student)) #2926222013040
print(type(Student)) #<class 'type'>
print(Student) #<class '__main__.Student'>
类的组成
-
类属性
-
实例方法
-
静态方法
-
类方法
class Student: #Student为类的名称(类名)由一个或多个单词组成,每个单词的首字母大写,其余小写
native_pace='吉林' #直接写在类里的变量,称为类属性
def __init__(self,name,age):
self.name=name #self.name 称为实体属性,进行了一个赋值的操作,将局部变量的name的值赋给实体属性
self.age=age
#实例方法
def eat(self): #self必须有,可以其他命名
print('学生在吃饭...')
#静态方法
@staticmethod
def method(): #静态方法不允许写self
print('我使用了statticmethod进行修饰,所以我是静态方法')
#类方法
@classmethod
def cm(cls):
print('我是类方法,因为我使用了classmethod进行修饰')
#在类之外定义的称为函数,在类之内定义的称为方法
def drink():
print('喝水')
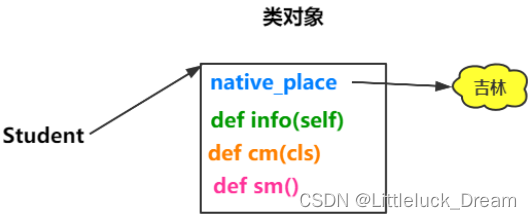
对象的创建
对象的创建又称为类的实例化
语法:

例子:
#创建Student类的实例对象
stu=Student('Jack',20)
print(stu.name)#实例属性
print(stu.age)#实例属性
stu.eat()#实例方法
#创建Student类的对象
stu1=Student('张三',20)
print(id(stu1))
print(type(stu1))
print(stu1)
print('---------------------')
print(id(Student)) #Student是类的名称
print(type(Student))
print(Student)
Student.eat(stu1) #与stu.eat()代码功能相同,都是调用Student中的eat方法
#类名.方法名(类的对象)-->实际上就是方法定义处的self
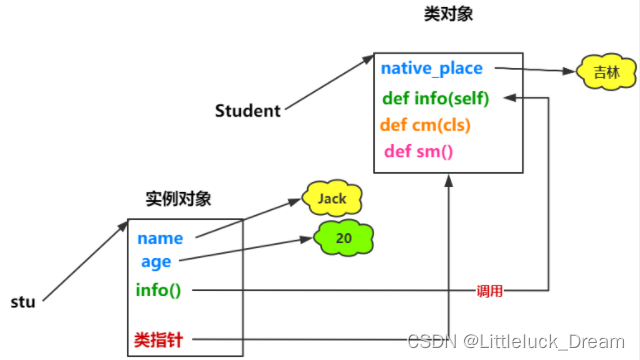
意义:有了实例,就可以调用类中的内容
类属性、类方法、静态方法
类属性:类中方法外的变量称为类属性,被该类的所有对象所共享
类方法:使用@classmethod修饰的方法,使用类名直接访问的方法
静态方法:使用@staticmethod修饰的主法,使用类名直接访问的方法
#类属性的使用方式
print(Student.native_pace) #访问类属性
stu1=Student('张三',20)
stu2=Student('李四',30)
print(stu1.native_pace)
print(stu2.native_pace)
Student.native_pace='天津'
print(stu1.native_pace)
print(stu2.native_pace)
print('---------类方法的使用方式------------------')
Student.cm()
print('---------静态方法的使用方式------------------')
Student.method()
动态绑定属性和方法
Python是动态语言,在创建对象之后,可以动态地绑定属性和方法
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def eat(self):
print(self.name+'在吃饭')
stu1=Student('张三',20)
stu2=Student('李四',30)
print(id(stu1))
print(id(stu2))
print('------------为stu1动态绑定性别属性---------------------------')
stu1.gender='男'
print(stu1.name,stu1.age,stu1.gender)
#print(stu2.name,stu2.age,stu2.gender)
print(stu2.name,stu2.age)
print('--------------------------')
stu1.eat()
stu2.eat()
def show():
print('定义在类之外的,称函数')
#动态绑定方法
stu1.show=show
stu1.show()
#stu2.show() #因为stu2并没有绑定show方法
对象的三大特征
- 封装:提高程序的安全性 将数据(属性)和行为(方法)包装到类对象中。在方法内部对属
性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔
离了复杂度。 在Python中没有专门的修饰符用于属性的私有,如果该属性不希望在类对象
外部被访问,前边使用两个“_” 。
-
继承:提高代码的复用性
-
多态:提高程序的可扩展性和可维护性
封装
封装的实现
class Student:
def __init__(self,name,age):
self.name=name
self.__age=age #年龄不希望在类的外部被使用,所以加了两个_
def show(self):
print(self.name,self.__age)
def get_age(self):
return self.__age
def set_age(self,age):
if O<=age<=120:
self.__age=age
else:
self.__age=18
stu1=Student(150)
stu2=Student(30)
print(stu1.get_age())
print(stu2.get_age())
stu=Student('张三',20)
stu.show()
#在类的外使用使用name与age
print(stu.name)
#print(stu.__age)
#print(dir(stu)) #查看类有哪些属性
print(stu._Student__age) #在类的外部可以通过 _Student__age 进行访问
继承
语法格式

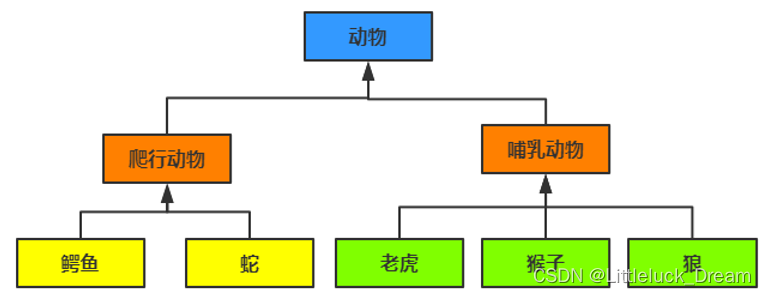
如果一个类没有继承任何类,则默认继承object
Python支持多继承定义子类时,必须在其构造函数中调用父类的构造函数
继承的代码实现
class Person(object): #Person继承object类,默认继承object,可省略
def __init__(self,name,age):
self.name=name
self.age=age
def info(self):
print(’姓名:{0},年龄:{1}'.format(self.name, self.age))
#定义子类
class Student(Person): #继承Person类
def __init__(self,name, age, stu_no):
super().__init__(name,age)
self.stu_no = stu_no
class Teacher(Person): #继承Person类
def __init__(self, name, age, teachOfYear):
super().__init__(name,age)
self.teachOfYear = teachOfYear
stu = Student('张三',20,'1001')
teacher = Teacher('李四',34,10)
stu.info()
teacher.info()
Python支持多重继承
-
一个子类可以有多个“直接父类”,这样,就具备了“多个父类”的特点
-
通过类的特殊属性__mro__ 可以查看类的组织结构
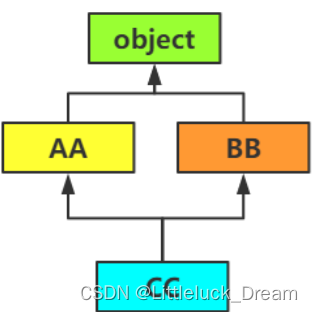
class AA(object):
def aa(self):
print('aa')
class BB(object):
def bb(self):
print(’bb’)
class CC(AA,BB):
def cc(self):
print('cc')
#查看类的组织结构print(CC.__mro__)

多态
简单地说,多态就是“具有多种形态”,它指的是:即便不知道一个变量所引用的对象到底
是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,
动态决定调用哪个对象中的方法。
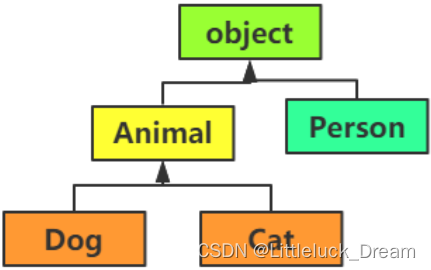
class Animal(object):
def eat(self):
print(’动物要吃东西’)
class Dog(Animal):
def eat(self):
print(’狗吃肉’)
class Cat(Animal):
def eat(self):
print(’猫吃鱼’)
class Person(object):
def eat(self):
print(’人吃五谷杂粮’)
def fun(animal):
animal.eat()
fun(Dog())
fun(Cat())
fun(Person())

静态语言与动态语言
-
静态语言实现多态的三个必要条件
- 继承 - 方法重写 - 父类引用指向子类对象 -
动态语言的多态崇尚“鸭子类型”当看到一只鸟走起来像鸭子、游泳起来像鸭子、收起来也像鸭子,那么这只鸟就可以被称为鸭子。在鸭子类型中,不需要关心对象是什么类型,到底是不是鸭子,只关心对象的行为。
方法重写
-
如果子类对继承自父类的某个属性或方法不满意,可以在子类中对其(方法体)进行重新编写
-
子类重写后的方法中可以通过super().xxx() 调用父类中被重写的方法
class Person(object):
def __init__(self,name,age):
self.name=nameself.age=age
def info(self):
print(’姓名:{0},年龄:{1}'.format(self.name,self.age))
#定义子类
class Student(Person):
def __init__(self,name,age,score):
super().__init__(name,age)
self.score=score
def info(self):
super().info()
print('学号:{0}'.format(self.score))
class Teacher(Person):
def __init__(self,name,age,teachOfYear):
super().__init__(name,age)
self.teachOfYear=teachOfYear
def info(self):
super().info()
print('教龄: {0}'.format(self.teachOfYear)
#测试
stu=Student('Jack',20,'1001')
teacher=Teacher('李四',34,10)
stu.info()
teacher.info()
object类
-
object类是所有类的父类,因此所有类都有object类的属性和方法。
-
内置函数dir()可以查看指定对象所有属性
-
Object有一个__str__()方法,用于返回一个对于“对象的描述”,对应于内置函数str()经常用于print()方法,帮我们查看对象的信息,所以我们经常会对__str__()进行重写
class Person(object):
def __init__(self,name,age):
self.name=nameself.age=age
def info(self):
print('姓名:{0},年龄:{1}'.format(self.name,self.age))
def __str__(self):
return '姓名:{0},年龄:{1}'.format(self.name,self.age)
o=object()
p=Person('Jack',20)
print(dir(o))
print(dir(p))
print(p) #默会调用__str__()这样的方法
print(type(p))
特殊方法和特殊属性
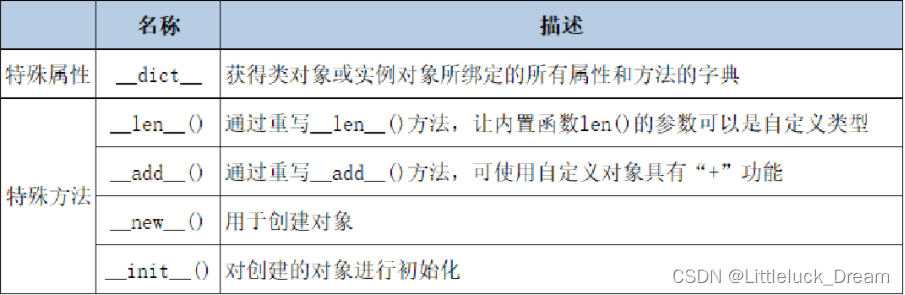
#print(dir(object))
class A:
pass
class B:
pass
class C(A,B):
def __init__(self,name,age):
self.name=name
self.age=age
class D(A):
pass
#创建C类的对象
x=C('Jack',20) #x是C类型的一个实例对象
print(x.__dict__) #实例对象的属性字典
print(C.__dict__)
print('--------------------')
print(x.__class__) #<class '__main__.C'> 输出了对象所属的类
print(C.__bases__) #C类的父类类型的元素
print(C.__base__) #类的基类,谁写在前面展示谁如C(A,B)则是A
print(C.__mro__) #类的层次结构
print(A.__subclasses__()) #子类的列表
a=20
b=100
c=a+b #两个整数类型的对象的相加操作
d=a.__add__(b)
print(c)
print(d)
class Student:
def __init__(self,name):
self.name=name
def __add__(self, other):
return self.name+other.name
def __len__(self):
return len(self.name)
stu1=Student('Jack')
stu2=Student('李四')
s=stu1+stu2 #实现了两个对象的加法运算(因为在Student类中 编写__add__()特殊的方法
print(s)
s=stu1.__add__(stu2)
print(s)
print('----------------------------------------')
lst=[11,22,33,44]
print(len(lst)) #len是内容函数len
print(lst.__len__())
print(len(stu1)) #需要重写__len__方法
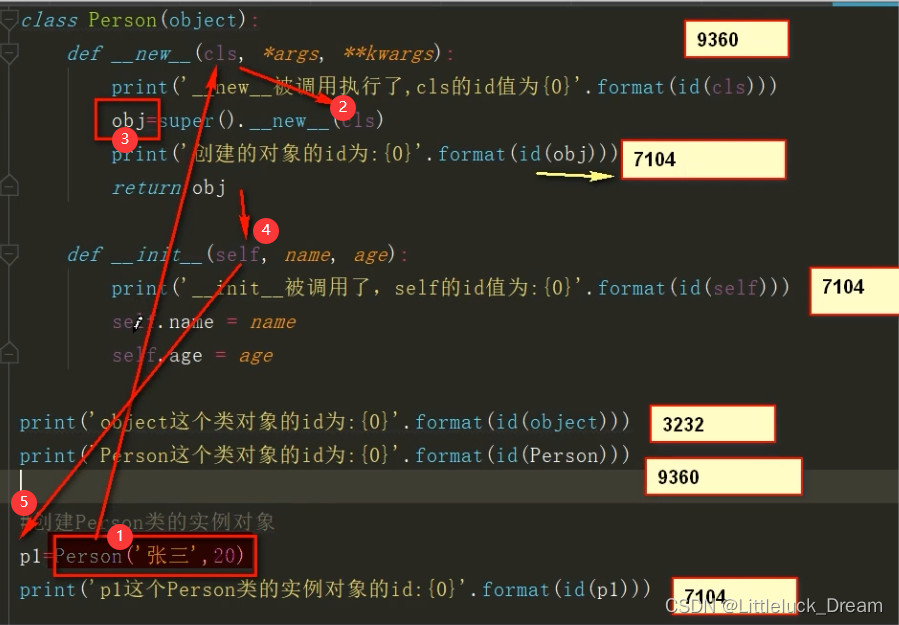
class Person(object):
def __new__(cls, *args, **kwargs):
print('__new__被调用执行了,cls的id值为{0}'.format(id(cls)))
obj=super().__new__(cls)
print('创建的对象的id为:{0}'.format(id(obj)))
return obj
def __init__(self, name, age):
print('__init__被调用了,self的id值为:{0}'.format(id(self)))
self.name = name
self.age = age
print('object这个类对象的id为:{0}'.format(id(object)))
print('Person这个类对象的id为:{0}'.format(id(Person)))
#创建Person类的实例对象
p1=Person('张三',20)
print('p1这个Person类的实例对象的id:{0}'.format(id(p1)))
类的浅拷贝与深拷贝
变量的赋值操作
只是形成两个变量,实际上还是指向同一个对象
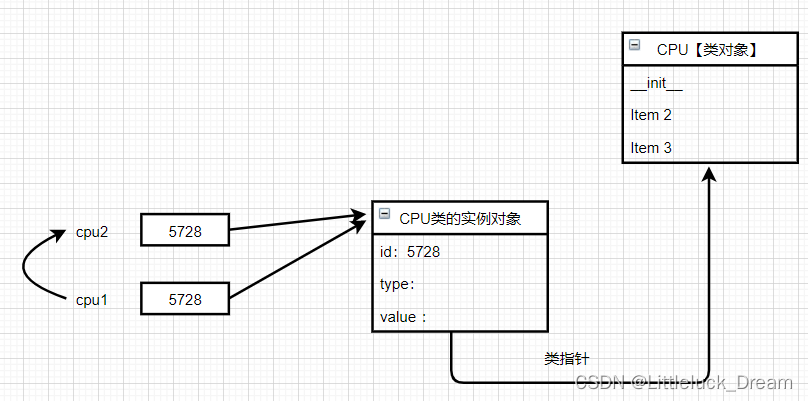
浅拷贝
Python拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝
对象会引用同一个子对象
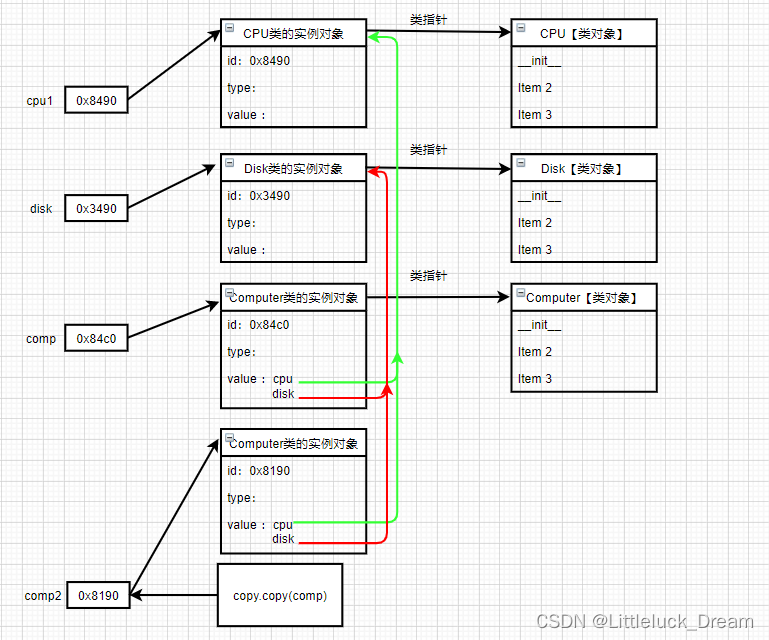
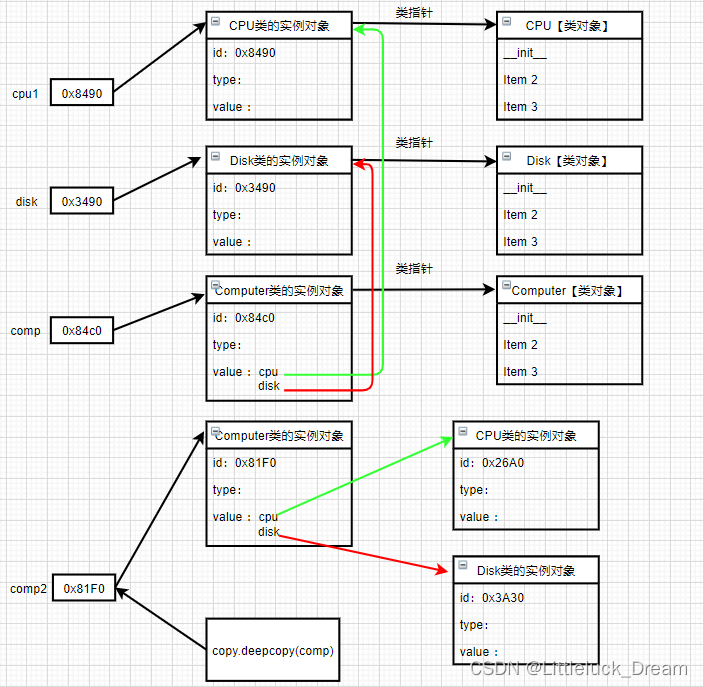
深拷贝
使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu=cpu
self.disk=disk
#(1)变量的赋值
cpu1=CPU()
cpu2=cpu1
print(cpu1,id(cpu1))
print(cpu2,id(cpu2))
#(2)类有浅拷贝
print('------------------------------')
disk=Disk() #创建一个硬盘类的对象
computer=Computer(cpu1,disk) #创建一个计算机类的对象
#浅拷贝
import copy
print(disk)
computer2=copy.copy(computer)
print(computer,computer.cpu,computer.disk)
print(computer2,computer2.cpu,computer2.disk)
print('----------------------------------------')
#深拷贝
computer3=copy.deepcopy(computer)
print(computer,computer.cpu,computer.disk)
print(computer3,computer3.cpu,computer3.disk)
模块
-
模块英文为Modules
-
函数与模块的关系
一个模块中可以包含N多个函数、类、语句 -
在Python中一个扩展名为.py的文件就是一个模块
-
使用模块的好处
- 方便其它程序和脚本的导入并使用 - 避免函数名和变量名冲突 - 提高代码的可维护性 - 提高代码的可重用性
自定义模块
创建模块
新建一个.py文件,名称尽量不要与Python自带的标准模块名称相同
导入模块

import math #导入关于数学运算的所有
print(id(math))
print(type(math))
print(math)
print(math.pi)
print('----------------------------------------')
print(dir(math))
print(math.pow(2,3),type(math.pow(2,3)))
print(math.ceil(9.001))
print(math.floor(9.9999)
#只想导入其中想用的部分
from math import pi
from math import pow
print(pi)
print(pow(2,3))
#print(math.pow(2,3))
以主程序形式运行
在每个模块的定义中都包括一个记录模块名称的变量__name__,程序可以检查该变量,以确定他们在哪个模块中执行。如果一个模块不是被导入到其它程序中执行,那么它可能在解释器的顶级模块中执行。顶级模块的__name__变量的值为__main__

定义一个calc.py模块
def add(a,b):
return a+b
print(add(10, 20)) #其他引入该模块调用add方法也会执行该语句
if __name__ == '__main__':
print(add(10,20)) #该语句只有当点击运行calc时,才会执行运算,其他地方引入该模块抵用add方法不会执行该语句
Python中的包
包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下,一个python程序包含N多个包,一个包下面有N多个模块,通过new Python package来创建一个包
作用:
-
代码规范
-
避免模块名称冲突
包与目录的区别
-
包含__init__.py文件的目录称为包
-
目录里通常不包含__init__.py文件
包的导入

#在demo8的模块中导入 pageage1包
import pageage1.module_A as ma #ma是pageage1.module_A这个模块的别名
#print(pageage1.module_A.a)
print(ma.a)
#导入带有包的模块时注意事项
#使用import方式进行导入时,只能跟包名或模块名
import pageage1
import calc
#使用from ...import可以导入包,模块,函数,变量.
from pageage1 import module_A
from pageage1.module_A import a #导入变量
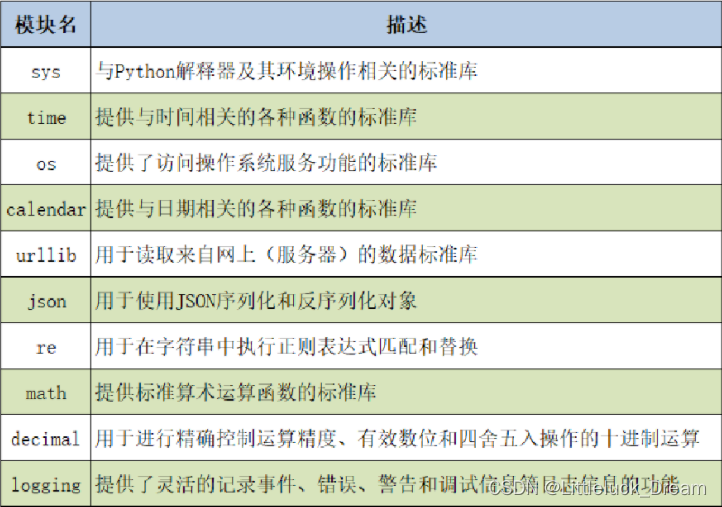
Python中常用的内置模块
import sys
import time
import urllib.request
import math
print(sys.getsizeof(24))
print(sys.getsizeof(45))
print(sys.getsizeof(True))
print(sys.getsizeof(False))
print(time.time())
print(time.localtime(time.time()))
print(urllib.request.urlopen('http://www.baidu.com').read())
print(math.pi)
第三方模块的安装及使用
第三方模块的安装
pip install 模块名
如pip install schedule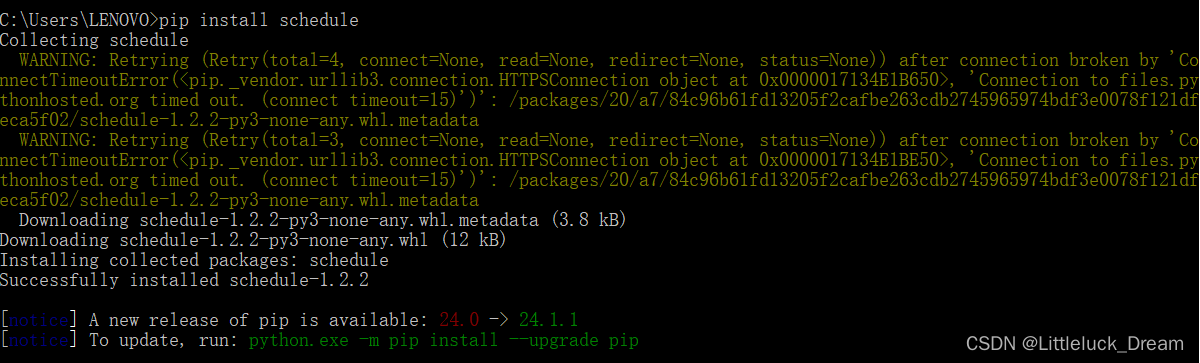
第三方模块的使用
import 模块名
import schedule
import time
def job():
print('哈哈 -------')
schedule.every(3).seconds.do(job)
while True:
schedule.run_pending()
time
文件的读写
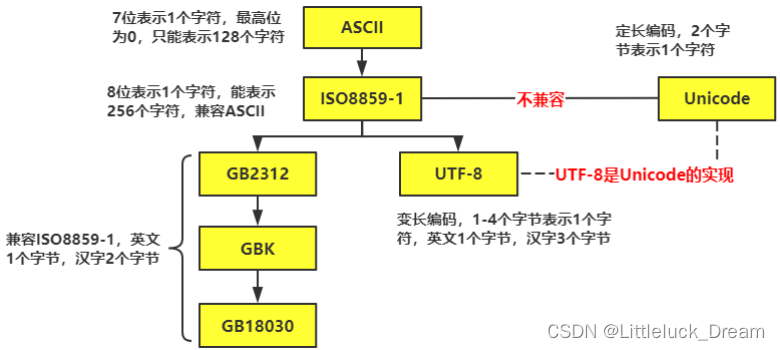
常见的字符编码格式
-
Python的解释器使用的是Unicode(内存)
-
.py文件在磁盘上使用UTF-8存储(外存)
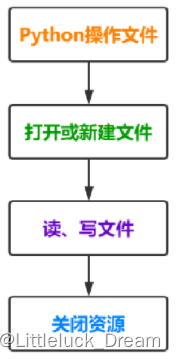
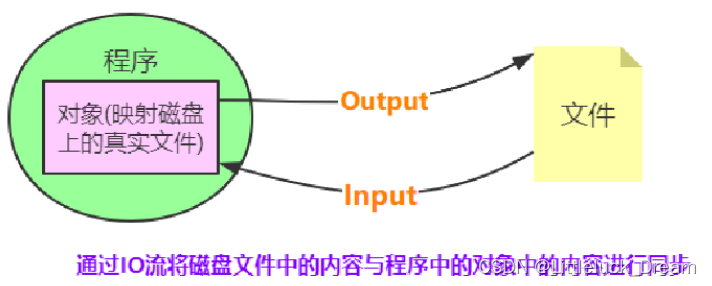
文件的读写原理
-
文件的读写俗称“IO操作”
-
文件读写操作流程
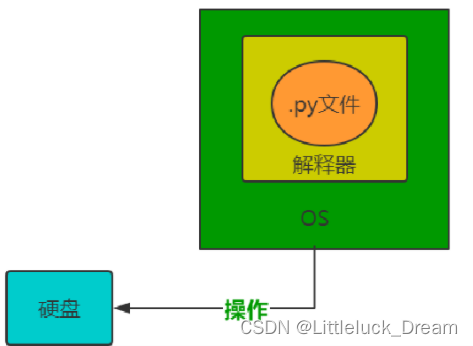
-
操作原理
文件的读写操作
- 内置函数open()创建文件对象
- 语法规则
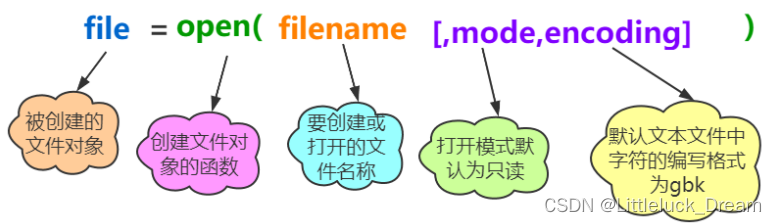
file=open('a.txt','r')
print(file.readlines())
file.close()
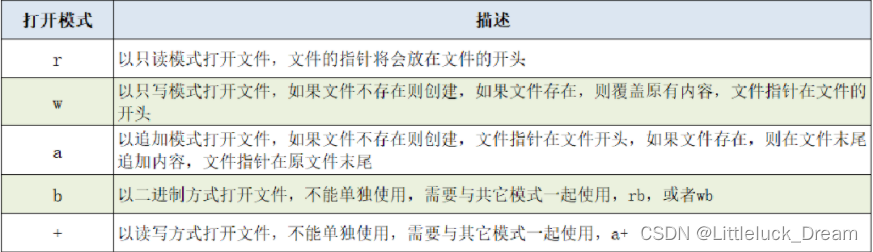
常用的文件打开模式
文件的类型
按文件中数据的组织形式,文件分为以下两大类
-
文本文件 :存储的是普通“字符”文本,默认为unicode字符集,可以使用记本事程序打
-
二进制文件:把数据内容用“字节”进行存储,无法用记事本打开,必须使用专用的软件打开 ,举例:mp3音频文件,jpg图片 .doc文档等
src_file=open('logo.png','rb')
target_file=open('copylogo.png','wb')
target_file.write(src_file.read())
target_file.close()
src_file.close()
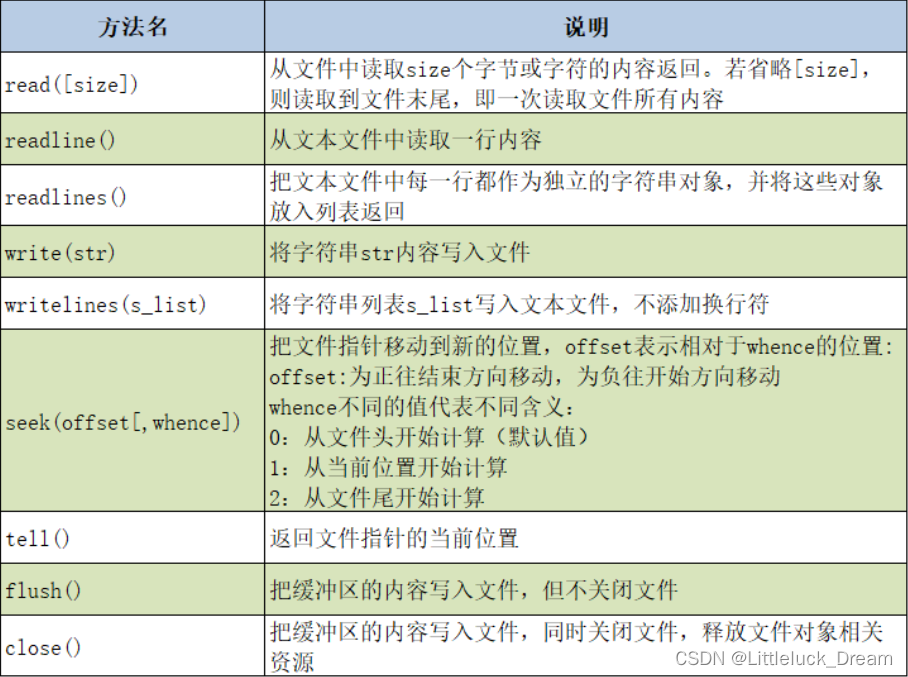
文件对象的常用方法
file=open('a.txt','r')
#print(file.read(2))
#print(file.readline())
print(file.readlines())
file.close()
file=open('c.txt','a')
#file.write('hello')
lst=['java','go','python']
file.writelines(lst)
file.close()
file=open('c.txt','r')
file.seek(2)
print(file.read())
print(file.tell())
file.close()
file=open('d.txt','a')
file.write('hello')
file.flush()
file.write('world')
file.close()
with语句(上下文管理器)
with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,
以此来达到释放资源的目的
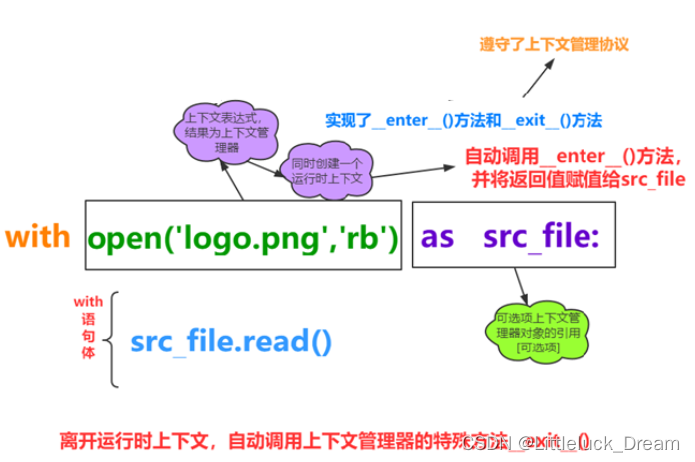
with open('a.txt','r') as file:
print(file.read()) #不需要手动close()
#实现文件复制
with open('logo.png','rb') as src_file:
with open('copy2logo.png','wb') as target_file:
target_file.write(src_file.read())
'''
MyContentMgr实现了特殊方法__enter__(),__exit__()称为该类对象遵守了上下文管理器协议
该类对象的实例对象,称为上下文管理器
'''
class MyContentMgr(object):
def __enter__(self):
print('enter方法被调用执行了')
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print('exit方法被调用执行了')
def show(self):
print('show方法被调用执行了',1/0)
with MyContentMgr() as file: #相当于file=MyContentMgr()
file.show()
目录操作
- os模块是Python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样。
- os模块与os.path模块用于对目录或文件进行操作
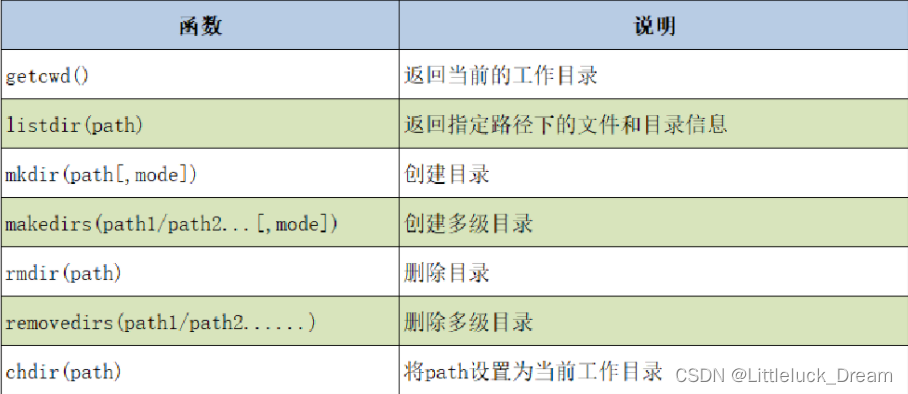
os模块操作目录相关函数
#os模块与操作系统相关的一个模块
import os
#os.system('notepad.exe')
#os.system('calc.exe')
#直接调用可执行文件
os.startfile('C:\\Program Files\\Tencent\QQ\\Bin\\qq.exe')
import os
print(os.getcwd())
lst=os.listdir('../chap15')
print(lst)
#os.mkdir('newdir2')
#os.makedirs('A/B/C')
#os.rmdir('newdir2')
#os.removedirs('A/B/C')
os.chdir('E:\\vippython\\chap15')
print(os.getcwd())
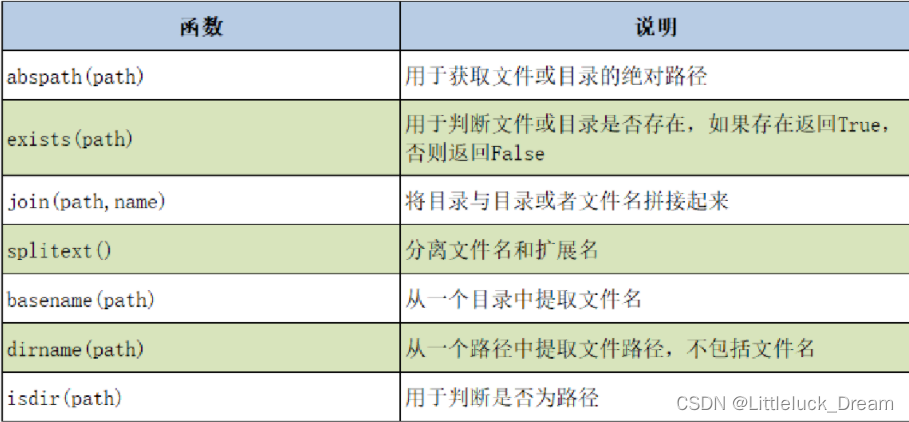
os.path模块操作目录相关函数
import os.path
print(os.path.abspath('demo13.py'))
print(os.path.exists('demo13.py'),os.path.exists('demo18.py'))
print(os.path.join('E:\\Python','demo13.py'))
print(os.path.split('E:\\vipython\\chap15\\demo13.py'))
print(os.path.splitext('demo13.py'))
print(os.path.basename('E:\\vippython\\chap15\\demo13.py'))
print(os.path.dirname('E:\\vippython\\chap15\\demo13.py'))
print(os.path.isdir('E:\\vippython\\chap15\\demo13.py'))
#列出指定目录下的所有py文件
import os
path=os.getcwd()
lst=os.listdir(path)
for filename in lst:
if filename.endswith('.py'):
print(filename)
import os
path=os.getcwd()
lst_files=os.walk(path) #递归遍历目录下所有文件, 结果是一个元组
for dirpath,dirname,filename in lst_files:
'''print(dirpath)
print(dirname)
print(filename)
print('-------------------------------------')'''
for dir in dirname:
print(os.path.join(dirpath,dir))
for file in filename:
print(os.path.join(dirpath,file))
print('----------------------------------')
项目打包
在线安装方式
pip install PyInstaller
执行打包操
找到对应文件,双击即可运行

















 138万+
138万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









