







 本文介绍了一种基于卷积神经网络(CNN)进行年龄和性别识别的方法,并提供了详细的实现步骤与模型结构。该模型是在Adience数据集上训练得到的。
本文介绍了一种基于卷积神经网络(CNN)进行年龄和性别识别的方法,并提供了详细的实现步骤与模型结构。该模型是在Adience数据集上训练得到的。
Age and Gender Classification Using Convolutional Neural Networks - Demo
数据地址:
主要任务点:
按照例程实现实际模型的运用,这是动手实现的第一个caffe应用,理解了大体轮廓与应用过程。
import os
import numpy as np
import matplotlib.pyplot as plt
import sys
import caffe
caffe_root = '/home/kangyemeng/caffe/'
sys.path.insert(0,caffe_root + 'python')
plt.rcParams['figure.figsize'] = (10,10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
#loading the mean image
mean_filename = '/home/kangyemeng/AgeGenderDeepLearning/models/mean.binaryproto'
proto_data = open(mean_filename,'rb').read()
a = caffe.io.caffe_pb2.BlobProto.FromString(proto_data)
mean = caffe.io.blobproto_to_array(a)[0]
#loading the age network
age_net_pretrained = '/home/kangyemeng/AgeGenderDeepLearning/models/age_net.caffemodel'
age_net_model_file = '/home/kangyemeng/AgeGenderDeepLearning/models/model_and_data/deploy_age.prototxt'
age_net = caffe.Classifier(age_net_model_file,age_net_pretrained,
mean = mean,
channel_swap = (2,1,0),
raw_scale = 255,
image_dims=(256,256))
#loading the gender network
gender_net_pretrained='/home/kangyemeng/AgeGenderDeepLearning/models/age_net.caffemodel'
gender_net_model_file='/home/kangyemeng/AgeGenderDeepLearning/models/model_and_data/deploy_age.prototxt'
gender_net = caffe.Classifier(gender_net_model_file, gender_net_pretrained,
mean=mean,
channel_swap=(2,1,0),
raw_scale=255,
image_dims=(256,256))
#labels
age_list=['(0, 2)','(4, 6)','(8, 12)','(15, 20)','(25, 32)','(38, 43)','(48, 53)','(60, 100)']
gender_list=['Male','Female']
#reading and plotting the input image
example_image = '/home/kangyemeng/AgeGenderDeepLearning/models/model_and_data/timg10.jpg'
input_image = caffe.io.load_image(example_image)
_ = plt.imshow(input_image) #服务器端绘图无法显示,原因还不知道。。。。?!
#age prediction
prediction = age_net.predict([input_image])
print 'predicted age:',age_list[prediction[0].argmax()]
#gender prediction
prediction = gender_net.predict([input_image])
print 'predicted gender:',gender_list[prediction[0].argmax()]
本文使用的网络结构为根据AlexNet删减得来,具体结构如下
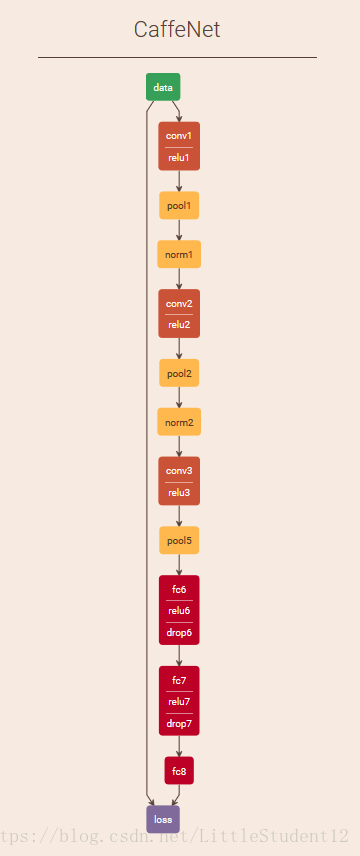
name: "CaffeNet"
layers {
name: "data"
type: DATA
top: "data"
top: "label"
data_param {
source: "/home/ubuntu/AdienceFaces/lmdb/Test_fold_is_4/gender_train_lmdb"
backend: LMDB
batch_size: 50
}
transform_param {
crop_size: 227
mean_file: "/home/ubuntu/AdienceFaces/mean_image/Test_folder_is_4/mean.binaryproto"
mirror: true
}
include: { phase: TRAIN }
}
layers {
name: "data"
type: DATA
top: "data"
top: "label"
data_param {
source: "/home/ubuntu/AdienceFaces/lmdb/Test_fold_is_4/gender_val_lmdb"
backend: LMDB
batch_size: 50
}
transform_param {
crop_size: 227
mean_file: "/home/ubuntu/AdienceFaces/mean_image/Test_folder_is_4/mean.binaryproto"
mirror: false
}
include: { phase: TEST }
}
layers {
name: "conv1"
type: CONVOLUTION
bottom: "data"
top: "conv1"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 7
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
name: "relu1"
type: RELU
bottom: "conv1"
top: "conv1"
}
layers {
name: "pool1"
type: POOLING
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layers {
name: "conv2"
type: CONVOLUTION
bottom: "norm1"
top: "conv2"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layers {
name: "relu2"
type: RELU
bottom: "conv2"
top: "conv2"
}
layers {
name: "pool2"
type: POOLING
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
name: "norm2"
type: LRN
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layers {
name: "conv3"
type: CONVOLUTION
bottom: "norm2"
top: "conv3"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers{
name: "relu3"
type: RELU
bottom: "conv3"
top: "conv3"
}
layers {
name: "pool5"
type: POOLING
bottom: "conv3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
name: "fc6"
type: INNER_PRODUCT
bottom: "pool5"
top: "fc6"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
inner_product_param {
num_output: 512
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layers {
name: "relu6"
type: RELU
bottom: "fc6"
top: "fc6"
}
layers {
name: "drop6"
type: DROPOUT
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layers {
name: "fc7"
type: INNER_PRODUCT
bottom: "fc6"
top: "fc7"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
inner_product_param {
num_output: 512
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layers {
name: "relu7"
type: RELU
bottom: "fc7"
top: "fc7"
}
layers {
name: "drop7"
type: DROPOUT
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layers {
name: "fc8"
type: INNER_PRODUCT
bottom: "fc7"
top: "fc8"
blobs_lr: 10
blobs_lr: 20
weight_decay: 1
weight_decay: 0
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
name: "accuracy"
type: ACCURACY
bottom: "fc8"
bottom: "label"
top: "accuracy"
include: { phase: TEST }
}
layers {
name: "loss"
type: SOFTMAX_LOSS
bottom: "fc8"
bottom: "label"
top: "loss"
}
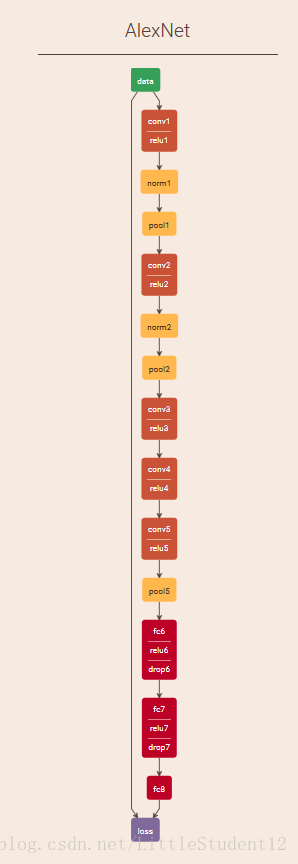
原始AlexNet如下所示


















 3745
3745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









