



 本文详细介绍了Hadoop伪分布式和完全分布式的配置过程。伪分布式配置包括安装VMWare、Linux,配置网络服务、主机名称等,还涉及安装jdk、ssh免密、Hadoop等步骤。完全分布式修改则需建立4台Linux主机,修改主机名和网关等。
本文详细介绍了Hadoop伪分布式和完全分布式的配置过程。伪分布式配置包括安装VMWare、Linux,配置网络服务、主机名称等,还涉及安装jdk、ssh免密、Hadoop等步骤。完全分布式修改则需建立4台Linux主机,修改主机名和网关等。
关于伪分布式的配置全程
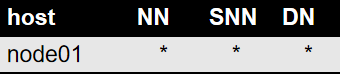
伪分布式图示
1.安装VMWare WorkStation,直接下一步,输入激活码即可安装
2.安装Linux(需要100GB)
引导分区Boot200MB
交换分区Swap2048MB
其余分配到/
3.配置网络服务
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.118.11
NETMASK=255.255.255.0
GATEWAY=192.168.118.2
DNS1=114.114.114.114
DNS2=192.168.118.11
注意点:
1.关于IPADDR的前三个网关,要与虚拟网络编辑器的VMnet8的子网IP的前三个网关一样
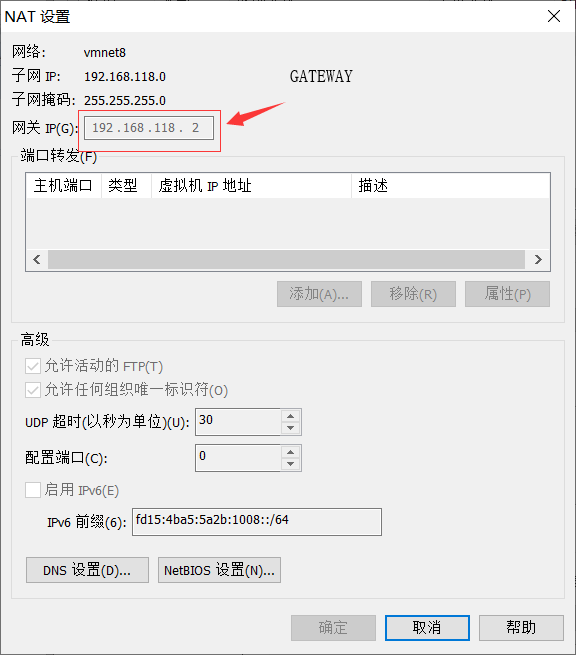
2.关于GATEWAY要与NAT下的GATEWAY一样,详情如下
虚拟网络编辑器:在VMWare编辑下打开
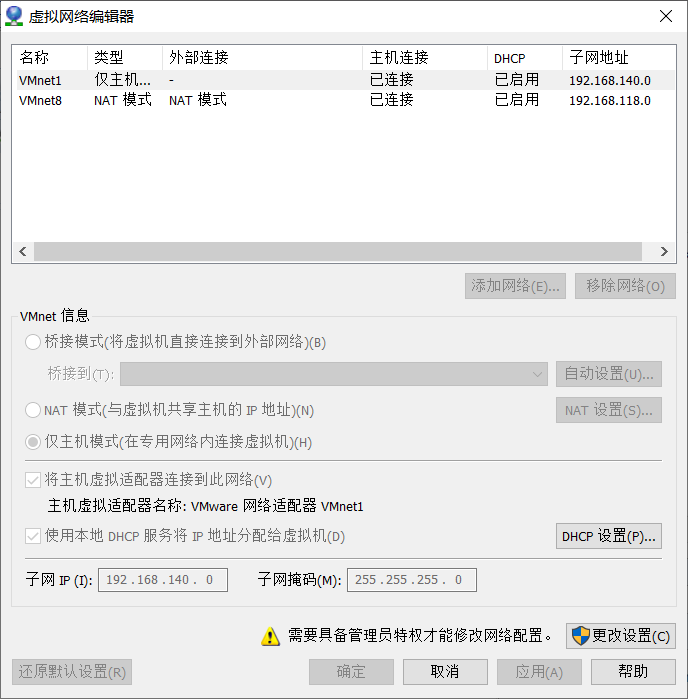
点击NAT设置,查看GATEWAY
4.修改主机名称
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node01
5.设置Host(关于Host,是指IP和主机名的映射关系)
vi /etc/hosts
192.168.150.11 node01
192.168.150.12 node02
6.关闭防火墙,开机不启动防火墙
service iptables stop
chkconfig iptables off
7.关闭selinux(selinux是Linux下一种安全模式,打开可能会连不上XShell)
vi /etc/selinux/config
SELINUX=disabled
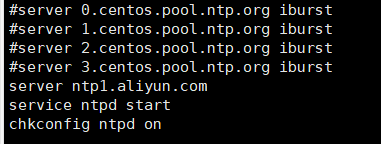
8.时间同步
使用yum安装ntp,并把原有的server注释,替换成
server ntp1.aliyun.com
service ntpd start
chkconfig ntpd on
9.安装jdk,使用xftp上传rpm文件
jdk-8u181-linux-x64.rpm
修改JAVA_HOME
vi /etc/profile
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
10.安装ssh免密
(1)检验ssh是否可以登录
ssh localhost
需要输入密码,则不免密
(2)设置免密
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh-keygen -t dsa表示使用dsa算法加密
-p ''表示密码为空
-f ~/ .ssh/id_dsa 将公钥放在/home/.ssh/id_dsa下
不能自己私自创建目录,关于ssh的目录权限,必须为755或者700,不能是777,否则不能使用免密
11.安装Hadoop
mkdir /opt/bigdata
tar xf hadoop-2.6.5.tar.gz
mv hadoop-2.6.5 /opt/bigdata/
pwd
/opt/bigdata/hadoop-2.6.5
设置Hadoop的环境变量
vi /etc/profile
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/opt/bigdata/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
12.修改hadoop-env.sh,此文件为hadoop启动脚本,将JAVA_HOME改为具体的环境变量
cd $HADOOP_HOME/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/usr/java/default
13.给出NN角色在哪里启动vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
14.配置一个hdfs副本
<!-- 副本数量为1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- NameNode的路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/local/dfs/name</value>
</property>
<!-- DataNode的路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/local/dfs/data</value>
</property>
<!-- SecondaryNameNode在哪个端口启动-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<!-- SecondaryNameNode的路径-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/var/bigdata/hadoop/local/dfs/secondary</value>
</property>
15.配置Slave
vi slaves
node01
16.初始化&启动
hdfs namenode -format
创建目录,并且初始化一个空的fsimage
VERSION CID
start-dfs.sh
17.修改windows: C:\Windows\System32\drivers\etc\hosts(注意这边IP要与端口一样)
192.168.150.11 node01
192.168.150.12 node02
192.168.150.13 node03
192.168.150.14 node04
18.简单创建目录
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
19.HDFS的常见命令
hadoop fs == hdfs dfs
命令的执行要在bin目录下
例:./hadoop fs -ls /
hadoop fs -ls / 查看
hadoop fs -lsr
hadoop fs -mkdir /user/haodop 创建文件夹
hadoop fs -put a.txt /user/hadoop 上传到hdfs
hadoop fs -get /user/hadoop/a.txt 从hdfs下载
hadoop fs -cp src dst 复制
hadoop fs -mv src dst 移动
hadoop fs -cat /user/hadoop/a.txt 查看文件内容
hadoop fs -rm /user/hadoop/a.txt 删除文件
hadoop fs -rmr /user/hadoop 删除文件夹
hadoop fs -text /user/hadoop/a.txt 查看文件内容
hadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似
hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件
2、帮助命令查看
hadoop帮助命令查看,不需要输入help,只需要在bin目录下输入即可。
例:./hadoop
./hadoop fs
关于完全分布式的修改
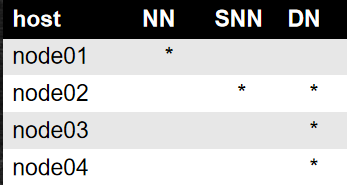
完全分布式图示
1.建立4台Linux主机
2.修改自己的主机名和网关
vim /etc/sysconfig/network-scripts/ifcfg-eth0
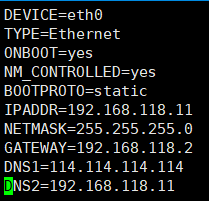
IPADDR分配4个不一样的IP

分配4个主机名
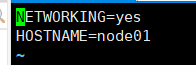
vim /etc/sysconfig/network
3.重启网卡
service network restart
4.重启网卡要记住删除文件
rm -f /etc/udev/rules.d/70-persistent-net.rules
5.文件命令
scp xxx node:0x/xx scp是一种远程拷贝
6.`pwd`可以在另一台主机同样位置进行定位

















 2336
2336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









