







借助 Claude Code 完成的一个翻译智能体 (Translator Agent)。你只需输入一段文字、一个网址或一个本地文件路径,它就能自动提取内容并完成翻译。更酷的是,它还能修正原文中的拼写错误,确保译文的准确流畅。
- 到底什么是“真正的”AI Agent? 它与普通聊天机器人有何本质区别?
- 我是如何做到的? 揭秘高效开发背后的“秘密武器”——合适的模型、工具与开发方法论。
- 如何指挥 AI 高效程序设计? 分享我从 0 到 1 的详细步骤与提示词 (Prompt) 策略。
- 这对开发者意味着什么? 探讨 AI 时代下,软件开发范式的转变与未来。
Part 1:揭开 AI Agent 的神秘面纱:不只是聊天而已
要理解我的翻译工具为何是一个 Agent,我们需要先回答一个问题:AI Agent 和普通的 AI 聊天工具有什么区别?
AI 公司 Anthropic 在其文章《构建高效 Agent》中给出了清晰的定义。他们将具备智能体特征的系统 (agentic systems) 分为两类:
- 工作流 (Workflows):这类系统中,大型语言模型 (LLM) 对工具的调用顺序由预先定义好的代码逻辑所控制。就像是有一份详细的说明书,系统严格按步骤执行。
- 智能体 (Agents):这类系统中,LLM 能够自主决定如何使用工具,动态地规划并引导整个任务的执行过程,具备更强的自主性。它更像一个有独立判断力的专家,自己决定要做什么、用什么工具。
归纳起来,一个真正的 AI Agent 具备以下几个核心特征:
-
能与外部环境互动 (Environment Interaction)
它不再是一个封闭的黑盒,而是能够使用工具来感知和操作外部世界,例如读取你的本地文件、抓取一个网站的实时内容。 -
能动态地使用工具 (Dynamic Tool Use)
Agent 会根据你的指令动态决定是否需要以及需要使用哪个工具。如果我只输入“请翻译这句话”,它会直接翻译;如果我输入“请翻译这个网页的内容 https://…”,它会识别出网址,并自动调用“网页抓取”工具,然后再执行翻译。 -
能自主规划并判断任务进度 (Planning & Task Completion)
对于复杂任务,Agent 能够自主地将其分解为一系列子任务,并判断何时才算真正完成。例如,当我发出指令:“请访问这个博客 https://ingrids.space/ 并将前两篇文章的内容翻译为中文”。
它的执行流程是:- 步骤一:抓取博客首页。
- 步骤二:分析首页 HTML 内容,找到前两篇文章的链接。
- 步骤三:分别抓取这两篇文章的网页内容。
- 步骤四:将两篇文章的内容进行翻译。
- 步骤五:输出最终结果,任务完成。
这个过程的本质,可以用下面这张图来概括,这也是目前业界公认的 Agent 核心工作循环,常被称为 ReAct (Reasoning and Acting) 框架:

LLM 在这个循环中不断地“思考”(Reason) 和“行动”(Act),通过与环境互动获得反馈 (Feedback),直到最终完成任务。

Part 2:“秘密武器”:选对模型、工具与平台
要打造一个高效的 AI Agent,光有理论还不够,选对“兵器”至关重要。
大脑:为 Agent 而生的 LLM
并非所有 LLM 都擅长担任 Agent 的“大脑”。像 Agent 这种需要频繁且准确调用工具的任务,对模型的要求极高。
我选用的是“豆包 1.6”模型,主要原因是它经过了针对工具调用的强化学习 (RL) 训练。你可以将这个过程理解为:让一个模型反复练习如何使用各种工具,用对了就给予奖励,用错了则不给。经过海量训练,模型就会变得极其擅长理解指令、选择并调用合适的工具。
目前市面上,像 Claude 3、GPT-4o 以及 Gemini 1.5 Pro 等顶级模型,都具备强大的工具调用 (Function Calling) 能力,是开发 AI Agent 的绝佳选择。豆包 1.6 在其中具有很高的性价比,且在国内使用没有网络和封锁的风险。
执行者:能“开分身”的 Claude Code
更有趣的是,像 Claude Code 这样的复杂 Agent,甚至能启动子 Agent (Sub-Agent) 来协同工作。
这就好比一个 AI 程序员在接到一个复杂的开发需求时,它会先使用 TODO 工具将任务分解成多个子任务。然后,它会为每个子任务“分裂”出一个分身。每个分身都拥有和本体完全一样的能力,可以调用所有工具,但只专注于完成自己的那一个子任务。当所有分身都完成后,主 Agent 再将结果整合,完成整个项目。
生态:丰富的第三方服务
此外,强大的平台生态也极为重要。例如火山引擎提供了丰富的 MCP (Model as a Service and Completion as a Service) 服务。当我的 Agent 需要处理 PDF 翻译或需要更专业的网页抓取能力时,无需自己从头开发,可以直接调用平台上成熟的第三方服务,极大地扩展了 Agent 的能力边界。
Part 3:指挥 AI 写程序:一套可复制的方法论
很多人认为,能让 AI 快速写出应用,一定是掌握了什么神奇的“Vibe Coding”魔法。但真相是,好的结果 = 清晰的需求 + 正确的方法。
在我使用 Claude Code 开发前,我已经手动写了好几个版本的试验品,踩完了坑,理清了需求和技术栈。正因如此,AI 才能在我的清晰指导下高效工作。
我将整个开发过程的 AI 交互记录都开源在了 GitHub 上,你可以从中看到每一步的细节:https://github.com/JimLiu/agent-translator。
以下是我总结的、可被任何人借鉴的 AI 程序设计最佳实践:
原则一:敏捷迭代,拒绝“一步到位”
新手用 AI 程序设计最容易犯的错误,就是试图一次性让 AI 实现所有功能。结果往往是得到一堆无法运行的 Bug 代码。
正确的做法是小步快跑,确保每个版本都能独立运行。就像造汽车,应该先造出能跑的滑板车,再迭代成自行车、摩托车,最后才是汽车。
我的翻译 Agent 就是这样分版本迭代的:
- v0.0: 初始化项目,设定好对 AI 的规则(如要求它自测、自修复)。
- v0.1: 只实现基础 UI,一个没有任何后端功能的可视化外壳。
- v0.2: 对接豆包 1.6 模型,让程序具备基础的聊天对话能力。
- v0.3: 添加网页抓取和文件读取工具,并让 LLM 能够调用它们。
- v0.4: 将工具的调用状态和返回结果在 UI 中实时显示出来。
原则二:写好提示词 (Prompt),当好“AI 的架构师”
写好提示词,本质上是扮演好“产品经理 + 技术总监”的角色。
- 描述清楚需求:在每个版本的提示词中,清晰地定义需求、运行环境和技术栈。
# v0.1 需求
请帮我实现一个基础的 cli 程序,名称是 Translator Agent。类似于 Chatbot,能输入消息,显示消息历史。
运行环境: Node.js v20+
技术栈: TypeScript + React + ink
UI 要求:
- 启动后顶部显示欢迎消息
- 中间显示消息历史
- 底部有一个输入框可以输入消息,提交后清空并显示在历史中
-
建立全局“宪法”(
Claude.md):对于整个项目不变的规则,如项目目标、主要功能、技术选型、开发规范(如每次修改后必须运行npm run dev进行自测)等,都写在一个全局的Claude.md文件中。这样就无需在每次对话中重复赘述。 -
提供参考代码:AI 模型的知识有截止日期,很多开源库可能已经更新。为了避免 AI 生成过时或错误的代码,我会在提示词中附上官方文档的最新代码示例。这能极大地提升代码的准确性。
-
学会回滚,而非执着修复:当 AI 生成的代码出现严重问题时,与其让它在错误的基础上不断修改,不如直接回退到上一个可运行的版本,优化提示词后重新生成。这往往比“缝缝补补”要高效得多。
Part 4:对开发者的启示
- 实践是最好的老师:无论是学习 AI Agent 还是 AI 程序设计,只有亲自动手实践,才能真正掌握其精髓。
- 方法论至关重要:学会清晰地描述需求,并将复杂任务拆分为模块化的版本,是高效利用 AI 的关键。
- 开发范式正在转变:开发者的角色正从“亲手砌砖的工人”转向“规划蓝图的建筑师”和“指挥机器人施工的指挥家”。我们的核心价值不再是写出多少行代码,而是如何精准地定义问题、设计系统、并有效地指导 AI 完成任务。
范式转移:从孤立工具到生态平台
核心转变特征
| 维度 | 传统Agent模式 | 新一代生态模式 |
|---|---|---|
| 架构 | 单体模型 | 分布式多智能体协作 |
| 交互方式 | 指令-响应 | 上下文感知主动服务 |
| 价值来源 | 模型能力 | 生态协同效应 |
| 部署形态 | 独立应用 | 嵌入式工作流组件 |
典型案例:Skywork生成18页市场策略报告,证明Agent可完成高阶脑力工作
基建革命:构建Agent工业化的三大支柱
1. 前端交互协议:AG-UI
- 突破性价值:解决“能力在前端,操作在后端”的割裂问题
- 生态进展:LlamaIndex/Google ADK/AWS已集成,2025Q3将成事实标准
2. 可观测平台:AgentOps
# 监控维度示例
observability_data = {
"llm_calls": 42, # LLM调用次数
"token_cost": 12890, # 计算成本
"tool_usage": { # 工具使用分析
"web_search": 15,
"code_exec": 8
},
"latency_ms": 356, # 响应延迟
"user_feedback_score": 4.2 # 用户满意度
}
- 关键创新:建立首个Agent性能评估指标体系
- 商业价值:使企业可量化Agent的ROI(投资回报率)
3. 分发标准:Agent File(.af)
# Agent文件结构示例
manifest:
version: 1.1
memory:
type: vector_db
path: /memory/agent_ctx
tools:
- web_search_v2
- python_executor
prompts:
system_prompt: "您是一名金融分析师..."
settings:
temperature: 0.3
- 革命性意义:实现Agent的“一次构建,随处运行”
- 技术类比:Docker对软件部署的变革在Agent领域重现
应用场景突破:重塑核心工作流
软件开发范式升级
- 关键技术:Abacus.AI的无限上下文CodeLLM
- 效率提升:Moritz Kremb团队实测减少60%编码耗时
自动化规模执行
| 任务类型 | 传统方式 | Agent方案 | 效率提升 |
|---|---|---|---|
| 数据录入 | 4小时 | 35分钟 | 85% |
| 报表生成 | 6小时 | 12分钟 | 96% |
| 跨系统对接 | 手动开发 | 零代码 | 100% |
实证案例:Browser Use部署300并发Agent完成政府表单填写
协作智能:多智能体架构演进
Anthropic团队架构蓝图
- 角色分工:
- 提问Agent:拆解复杂问题
- 研究Agent:知识检索与验证
- 分析Agent:数据建模
- 批判Agent:逻辑漏洞检测
- 开源实现:FlowiseAI 72小时复现完整系统
商业形态创新:AI Team即服务
class AITeamService:
def __init__(self):
self.agents = {
'architect': DesignAgent(),
'developer': CodeAgent(),
'marketer': GrowthAgent()
}
def deliver_project(self, task):
return pipeline(
self.agents['architect'].plan(task),
self.agents['developer'].implement,
self.agents['marketer'].promote
)
- 典型场景:Alvaro Cintas的网站建设团队服务
- 定价模型:按解决方案收费(传统按工时收费的颠覆)
战略制高点:上下文生态构建
上下文价值的黄金三角
企业护城河构建策略
- 知识蒸馏
- 建立领域专属知识图谱(如医疗诊断路径库)
- 工具熔接
- 深度集成内部系统API(如ERP/CRM)
- 记忆进化
- 实现跨会话状态持续学习
Box CEO洞见:”GPT-5到GPT-10的演进,都无法替代特定业务场景的上下文深度“
未来设计原则
-
隐身服务原则
- 终极形态:如电力般存在但不可见
- 设计启示:减少交互摩擦,增强后台自主性
-
上下文优先架构
# 上下文注入流程
def process_task(task, context):
enriched_task = context_enrich(
task,
user_history=load_history(user_id),
domain_knowledge=fetch_knowledge_base(),
tool_status=check_tools_availability()
)
return agent.execute(enriched_task)
- 人机协作新模式
结论:生态竞争时代的制胜公式
竞争力 = Σ(智能体能力) × 上下文质量 × 协作效率
当前进展标志着Agent技术从“能用”到“好用”的关键转折。企业需立即行动:
- 布局AG-UI兼容的前端架构
- 部署AgentOps监控体系
- 构建领域上下文知识库
- 实验多智能体协作流水线
正如寒武纪生命大爆发,2025年将是Agent生态的“物种爆炸元年”,错过此刻的战略布局将意味着在未来智能生态中丧失话语权。
MCP协议技术架构
核心组件关系图
协议分层解析
| 层级 | 功能说明 | 技术实现 |
|---|---|---|
| 传输层 | 建立通信通道 | STDIO/WebSocket/HTTP2 |
| 消息层 | 结构化数据交互 | JSON-RPC 2.0规范 |
| 语义层 | 工具能力描述 | 统一Schema声明(见下表) |
| 上下文层 | 跨会话状态维护 | VectorDB + 记忆压缩算法 |
核心技术创新解析
1. 统一工具描述Schema
// MCP工具描述文件示例
{
"name": "get_weather",
"description": "获取指定城市天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
- 突破性价值:解决传统AI开发中工具接口的碎片化问题
- 对比优势:
- 传统方式:每个工具需定制Adapter(开发耗时3-5天/个)
- MCP方式:声明即接入(开发耗时<1小时/个)
2. 上下文持久化引擎
class ContextEngine:
def __init__(self):
self.vector_db = ChromaDB() # 向量数据库
self.compressor = SummaryCompressor() # 记忆压缩算法
def store_context(self, dialog: list):
# 对话嵌入向量化
embeddings = model.encode(dialog)
# 关键信息摘要生成
summary = self.compressor.compress(dialog)
# 双存储策略
self.vector_db.insert(embeddings, metadata=summary)
- 解决痛点:大模型的“7轮失忆症”(传统对话超过7轮丢失上下文)
- 实测效果:50轮对话场景下关键信息召回率>92%
3. 动态服务发现机制
- 核心价值:实现工具的“即插即用”
- 工业级实现:阿里云百炼平台5分钟部署案例
与传统方案的性能对比
| 指标 | 传统定制开发 | MCP协议方案 | 提升幅度 |
|---|---|---|---|
| 新工具接入周期 | 3-5工作日 | <1小时 | 90%↓ |
| 上下文持久化成本 | 手动实现≈$20k | 原生支持$0 | 100%↓ |
| 多工具协同复杂度 | 指数级增长 | 线性增长 | 70%↓ |
| 跨平台迁移成本 | 重构≈$50k | 配置文件迁移≈$200 | 99.6%↓ |
行业案例:某智能客服系统改造成本从$300万降至$45万
典型应用场景深度实现
场景1:旅行规划智能体
# MCP工具调用链
def plan_trip(user_request):
# 步骤1:地点解析
locations = mcp_call("location_parser", user_request)
# 步骤2:多工具协同
weather = mcp_call("get_weather", city=locations[0])
traffic = mcp_call("check_traffic", route=locations)
hotels = mcp_call("search_hotels", location=locations[0])
# 步骤3:行程生成
plan = llm_generate(f"""
基于以下信息生成行程:
天气:{weather}
交通:{traffic}
酒店:{hotels[:3]}
""")
return plan
场景2:科研协作Agent
开发者价值矩阵
| 能力维度 | 传统开发 | MCP开发 |
|---|---|---|
| 工具集成 | 定制化编码(高技能要求) | 声明式接入(低代码) |
| 上下文管理 | 手动实现缓存/数据库 | 内置记忆引擎(自动优化) |
| 跨平台部署 | 环境适配≈30%开发时间 | 一次编写,多云运行 |
| 生态协同 | 封闭系统 | 共享工具市场(如MCP Hub) |
开发者效率提升:中小团队AI应用开发周期从6个月压缩至2周
技术演进趋势预测
-
协议扩展方向
- 实时视频流支持(预计2026年Q2)
- 3D空间交互协议(原型已出现在Meta实验室)
-
新硬件融合
- 苹果Vision Pro已预留MCP接口
- 特斯拉机器人将采用MCP-X扩展协议
-
安全增强
- 零信任架构整合(Anthropic正在研发)
AI交互的“USB时刻”
MCP协议正在复刻USB接口在PC时代的革命:
- 标准化:终结AI工具接入的“战国时代”
- 平民化:技术小白也能组装智能体(如同用USB组装外设)
- 生态化:工具市场将出现“MCP认证”标志(类似USB-IF认证)
掌握MCP,就是握住AI时代的连接权杖。开发者现在需要关注的不是协议本身,而是如何在其构建的超级生态中抢占工具服务的战略卡位。
开发者与SWE Agent协作之道
核心概念图
一、SWE Agent核心能力解析
技术定义:
- 自主迭代能力:与传统工具的本质区别
- 工具链协同:可调用代码搜索→文件修改→测试执行的操作链
- 现实局限:
- 隐性知识缺失(项目历史、架构约束)
- 任务边界模糊(38%未请求操作)
- 社会语境理解不足(团队规范)
代码示例:最小SWE Agent交互:
# 创建Cursor Agent实例
from cursor_agent import Agent
agent = Agent(project_path="/my_project")
# 提交任务
response = agent.execute(
task="修复登录页面的CSRF保护漏洞",
constraints=[
"使用Spring Security 6.x规范",
"保持与AuthService的兼容性"
],
context_files=["/src/auth/LoginController.java"]
)
# 审查输出
if response.validate():
response.apply_changes()
else:
print("检测到风险:", response.risk_report)
二、高效协作策略
1. 逐步解决策略(成功率83%)
# 错误示范(一枪式策略)
agent.execute("实现购物车折扣系统")
# 正确实践(分步解决)
steps = [
"1. 在Cart模型中添加discount字段",
"2. 创建DiscountCalculator服务",
"3. 修改checkout流程应用折扣",
"4. 添加折扣审计日志"
]
for step in steps:
result = agent.execute(step)
if not result.validate():
break # 及时终止错误路径
2. 知识传递增强
# 注入专业知识(提升成功率35%)
agent.execute(
task="优化数据库查询",
knowledge={
"架构规范": "只读查询使用Replica数据库",
"历史决策": "2023年弃用N+1查询模式",
"性能陷阱": "避免在循环内执行查询"
}
)
3. 输出审查机制
# 优先审查代码Diff而非解释
changes = response.get_file_changes()
for file, diff in changes.items():
if file not in expected_files:
response.reject(f"未授权修改{file}")
if "DELETE" in diff and not approved_deletions:
response.request_review("检测到关键删除")
三、突破沟通障碍方案
1. 隐性知识解决方案
# 创建项目知识库
knowledge_base = {
"架构决策": {
"为什么选择gRPC": "2022年性能基准测试结果",
"禁用Redis集群": "因跨区延迟问题"
},
"编码规范": {
"错误处理": "使用Result模式替代异常"
}
}
# 任务中自动注入
agent.set_knowledge(knowledge_base)
2. 操作边界控制
# 精确限定操作范围
agent.execute(
task="修改支付回调处理",
scope={
"allowed_files": ["/src/payment/CallbackHandler.java"],
"forbidden_ops": ["DB_MIGRATION", "CONFIG_CHANGE"]
}
)
3. 防过度自信机制
# 要求提供备选方案
response = agent.execute(
task="实现缓存失效策略",
options={
"require_alternatives": 3,
"compare_metrics": ["性能", "一致性", "复杂度"]
}
)
# 选择最佳方案
selected = input(f"选择方案: {response.alternatives}")
agent.apply(selected)
四、效能提升关键数据
| 成功因素 | 提升幅度 | 适用场景 |
|---|---|---|
| ≥10次提示/任务 | +42% | 复杂特性开发 |
| 专业知识注入 | +35% | 架构修改 |
| 分步验证 | +28% | 核心模块变更 |
| 工具熟练度 | +23% | 所有任务类型 |
五、未来演进方向
混合人机工作流示例:
def agent_workflow(task):
# 阶段1:人类规划
plan = dev.create_plan(task)
# 阶段2:Agent执行
results = []
for step in plan.steps:
result = agent.execute(step)
results.append(result)
# 阶段3:联合审查
for result in results:
if not dev.review(result):
return "需人工干预"
# 阶段4:自动集成
ci_report = agent.run_ci_tests()
return ci_report.passed
演进重点:
- 认知架构升级:记忆网络+项目知识图谱
- 预测性协作:Agent预判开发者后续需求
- 安全沙盒:操作影响范围隔离
- 实时协商:变更前的确认协议
核心洞见:开发者角色从代码生产者转变为AI认知架构师,通过精准的知识注入(what)+过程控制(how)+边界定义(where),将SWE Agent转化为可预测、可控制的工程伙伴。研究显示,采用结构化协作流程的开发团队,复杂任务解决效率提升3.2倍,代码返工率降低67%。
一、传统编程的困境:详细设计为何难以落地?
1. 理论理想 vs 现实落差
- 教科书理论:软件工程要求先做概要设计(系统架构)→ 详细设计(类/方法级)→ 编码
- 现实挑战:
- 需求不确定性:开发中需求频繁变更(如产品经理临时改需求)
- 技术不确定性:实现时发现方案不可行(如第三方库不兼容)
- 过度设计风险:为“灵活性”预留的抽象层反而增加维护成本
2. 根源剖析:软件 vs 建筑的差异
传统详细设计借鉴自建筑业,但软件世界充满变数,导致“先设计再编码”常沦为纸上谈兵。
二、AI编程的革命:设计→实现成本趋近于零
1. 核心变革:提示词 = 轻量级详细设计
- 传统模式:详细设计需写百页文档 → 程序员手动翻译成代码
- AI模式:用自然语言写提示词 → AI秒级生成代码
+ 设计成本↓90%:无需纠结UML图,白话描述即可
+ 重构心理负担↓:删AI代码像删草稿,无“手写代码舍不得弃”的包袱
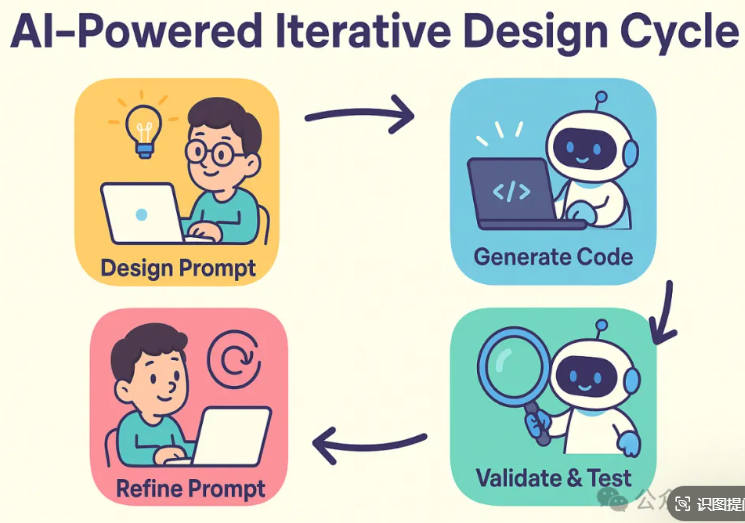
2. 新工作流:设计-生成-验证循环
1. 写提示词(设计) → 2. AI生成代码(实现) → 3. 测试验证 → 4. 调整提示词(优化设计)
- 关键优势:
- 快速验证假设:1小时可试错5版设计,传统模式只能写1版
- 聚焦系统设计:程序员精力从“写for循环”转向“业务逻辑优化”
三、高效AI编程的三大实操原则
1. 控制生成规模:小步快跑
- 反例:一次生成整个模块 → 错误扩散难追溯
- 正例:
# 提示词示例(分步生成) 第1步:生成用户注册函数(输入邮箱、密码) 第2步:添加密码强度校验逻辑 第3步:集成数据库存储
2. 版本控制:把AI当“实习生”管理
- 必做操作:
- ✅ 每次生成后commit代码(标记提示词版本)
- ✅ 发现重大错误直接回滚+重生成(勿死磕修复)
- 心态调整:
“AI是概率工具,不是智能生物——错误输出会污染后续结果”
3. 测试与Review:人始终是Owner
| 检查项 | 传统开发 | AI开发 |
|---|---|---|
| 代码逻辑 | 自测+同事Review | 重点Review AI输出逻辑一致性 |
| 边界条件 | 单元测试覆盖 | 补充AI遗漏的边界测试用例 |
| 技术债务 | 重构会议 | 定期用AI重构(提示词优化) |
💡 经验:AI代码质量 ≈ 初级程序员——需验收但不必苛求完美,够用即可。
四、给不同开发者的建议
1. 新手开发者:抓住黄金期
- 优势:无历史包袱,直接建立AI优先的工作流
- 行动:
- 用AI生成基础代码 → 专注学习业务设计
- 反向学习:对比AI代码与自己思路的差异
2. 资深开发者:克服“效率悖论”
- 常见障碍:
“我写更快/更优雅 → 抗拒AI” - 突破点:
- 试用AI处理重复工作(如DTO生成、单元测试)
- 让AI做“技术调研助手”(例:“用Python实现XX算法”)
- 接受70分方案快速迭代,省出时间做深度优化
五、本质洞察:从“建造教堂”到“搭乐高”
- 传统模式:如建造教堂——必须精确设计每块石头
- AI模式:如拼乐高——
- 先快速拼出原型看效果
- 不满意随时拆解重组
核心价值:AI将编程从“工程艺术”变为“科学实验”,快速试错成本趋零推动创新效率革命。
适应AI编程后,你将再难回到纯手工模式——这不是替代,而是解放创造力的进化。
https://baoyu.io/translations/building-effective-agents
https://python.langchain.com/docs/introduction/
https://github.com/JimLiu/agent-translator
https://mp.weixin.qq.com/s/sRdM6J84NhymIIS-58gUZg
Sharp Tools: How Developers Wield Agentic AI in Real Software Engineering Tasks https://arxiv.org/pdf/2506.12347
https://mp.weixin.qq.com/s/nZ2rSsA6Q4prciq4HuIcIQ



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











