







在大语言模型(LLMs)的发展历程中,「规模效应」始终是性能提升的核心驱动力。从GPT-3的1750亿参数到GPT-4的万亿级架构,模型通过海量文本 的「下一个token预测」任务(NTP)学习语言规律,但这种纯粹的自监督训练逐渐暴露出局限性:模型更擅长「记忆」而非「推理」,面对复杂问题时容易陷入「模式匹配」而非逻辑推导。
与此同时,强化学习(RL)在对齐人类偏好(如RLHF)和提升推理能力上展现潜力,但传统RL依赖昂贵的人工标注或领域特定奖励函数,难以在大规模预训练中应用。如何让RL突破数据瓶颈,与自监督预训练的 scalability 结合?微软研究院联合北大、清华提出的强化预训练(Reinforcement Pre-Training, RPT) 给出了全新答案。
-
通常情况下,预训练阶段会对模型进行全面训练,以学习语言的通用模式和知识。这部分可能得翻阅 xtuner 官方文档查看源代码了
-
监督微调(SFT)是对预训练模型进行进一步训练的方法,通常用于特定任务的适配。增量预训练则是在预训练模型的基础上,继续使用新的数据进行训练,以扩展模型的能力。在某些情况下,SFT 可以视为增量预训练的一种形式,特别是当新的数据集用于扩展模型的知识的时候。
https://thegenerality.com/agi/
论文原文:Reinforcement Pre-Training: A New Scaling Paradigm for Large Language Models
核心问题:大模型(LLM)像个“超级记忆王”,但有点“死脑筋”。
- 现在的LLM(比如ChatGPT)都是通过“猜下一个字”(下一个token预测)在海量文本里训练出来的。这就像让一个人疯狂背书,背得滚瓜烂熟。
- 问题来了:它们特别擅长背答案和找规律,但遇到需要真正动脑筋推理的问题(比如复杂的数学题、逻辑谜题),就显得有点“死记硬背”,而不是真正理解逻辑。
传统解法:请个“家教”教它思考(强化学习),但家教太贵。
- 强化学习(RL)可以让模型学会按人类期望的方式思考和行动,就像请家教教孩子解题思路。
- 但传统方法(如RLHF)需要大量人工来“批改作业”(标注数据和奖励),或者需要为特定任务定制复杂的“评分标准”(奖励函数)。这成本太高,没法在大规模预训练阶段用。
RPT的妙招:把“背书”本身变成“解题训练”!
RPT的核心创新在于:它巧妙地把原本用来“背答案”的预训练过程,变成了一个需要“写解题过程”的推理练习。 并且,它找到了一个免费、自动的“评分老师”!
具体是怎么做的?
-
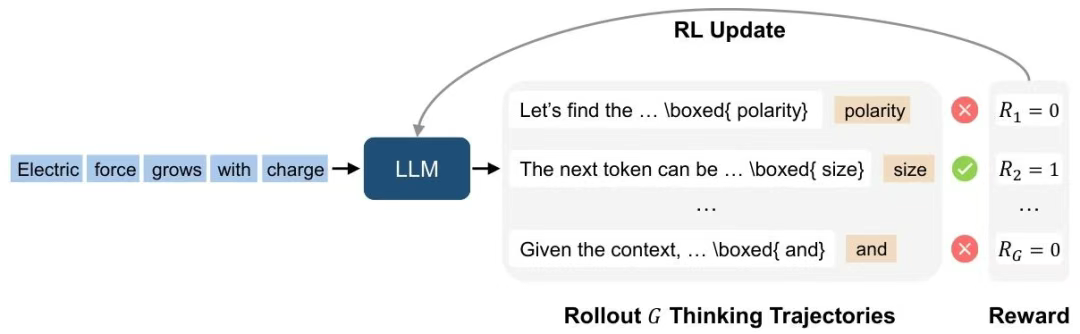
任务变身:从“猜字”到“写解题过程再猜字”
- 传统训练:给模型一句话的前半部分,让它直接猜下一个字/词是什么。
- RPT训练:给模型一句话的前半部分,要求它先生成一段“思考过程”(像我们写数学题的草稿、推理步骤),然后再基于这个思考过程去猜下一个字/词。
- 关键比喻: 就像考试时,老师不仅要求你写最终答案(ABCD),还要求你在卷子上写出详细的解题步骤(草稿)。
-
神奇的“自动判卷老师”:标准答案就在旁边
- RPT如何判断模型做得好不好?它有一个天然的优势:训练用的文本数据本身就有标准答案(真实的后续文字)!
- 评分规则极其简单粗暴:
- 如果模型最终猜的字/词和文本中真实的那个字/词 完全一样(严格匹配),就给它打 1分(满分)。
- 如果猜错了,就是 0分。
- 关键比喻: 这个免费老师只看你最终写的答案(ABCD)和标准答案对不对得上。对得上就给满分,对不上就零分。它不仔细看你的解题过程写得对不对、好不好!但是,它强制要求你必须写解题过程。
-
模型被迫“动脑筋”:为了猜对答案,必须写好推理
- 模型很“功利”,它想要高分(奖励1分)。
- 但规则要求它必须先写“思考过程”才能猜答案。
- 为了最终猜对那个字词,模型就不得不认真写思考过程,尝试通过这段思考过程来真正理解上下文逻辑,从而提高猜对的可能性。
- 训练时,模型会尝试生成多条不同的“思考路径”(多条推理轨迹),看看哪条路径最终能导向正确的答案。
- 关键比喻: 虽然老师只看最终答案给分,但学生发现,如果不认真写解题步骤(推理),就更容易猜错答案得零分。为了得高分,学生就被迫去写解题步骤,并且努力让这些步骤能帮自己得出正确答案。久而久之,就养成了先思考、再作答的好习惯。
-
用“免费”数据训练“思考能力”
- 最大的好处:不需要人工标注! 训练用的文本数据(互联网上的网页、书籍等)本身就有上下文关系,天然提供了“标准答案”。
- RPT把这些海量的、未标注的文本,直接变成了训练模型推理能力的资源。
- 关键比喻: 学校不用花钱请老师专门出一堆“思考题”和“标准答案”,而是直接拿现成的课本、习题册(里面的题目本身就有答案)来训练学生“写解题步骤”的习惯。
RPT带来了什么好处?
-
模型更“聪明”了: 实验证明,经过RPT训练的大模型:
- 在需要推理的任务上表现更好(比如数学、逻辑题),准确率显著提升。
- 甚至小模型也能有大智慧:一个14B参数的RPT模型,推理能力可以媲美甚至超过参数大一倍的(32B)普通模型。相当于一个中学生(RPT)的解题能力比大学生(普通模型)还强!
- 有了**“零样本”推理能力**:没专门教过的新题目类型,也能靠推理能力去尝试解决,泛化能力更强。
- 推理模式更接近人类:分析显示,RPT模型生成的思考过程中,“提出假设”、“进行演绎推理”等高级思维活动明显增多。
-
打通“预训练”和“微调”的隔阂:
- 传统模型预训练是“背书”,微调(用RL教特定技能)是“补课”,两者目标不一致,转换起来很费劲。
- RPT让模型在“背书”阶段就养成了“思考”的习惯(推理基因),后续再进行强化学习微调时,就像给一个已经会思考的学生补课,效果更好、效率更高、更顺畅。
总结一下RPT的革命性:
- 目标变了: 从“猜对答案”(NTP)变成了“通过写思考过程来猜对答案”(RPT)。
- 监督信号变了: 从“概率匹配”(似然)变成了“答案对错”(二元奖励)。
- 核心能力变了: 在预训练阶段就内嵌了推理能力,不再是单纯记忆。
- 数据要求变了: 无需人工标注,直接用海量无标注文本训练推理能力。
- 效果变了: 模型在推理能力、参数效率、泛化能力上都有显著提升。
RPT就像给大模型在“幼年”学习阶段,制定了一条“必须写解题步骤才能答题”的强制校规。虽然老师(奖励机制)只看最终答案打分,但这个规矩逼着模型(学生)从一开始就养成动脑筋、讲逻辑的思维习惯,从而变成了一个真正的“思考者”,而不仅仅是个“记忆王”。这为大模型通向真正的“智能”铺了一条新路。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











