



 AMD的RyzenAI笔记本电脑搭载AI引擎,加速ML框架运行,但目前仅限Windows。AMD员工重开Linux支持请求,回应用户需求。随着AI工作负载增长,期待AMD为Linux启用RyzenAI以与英特尔竞争。
AMD的RyzenAI笔记本电脑搭载AI引擎,加速ML框架运行,但目前仅限Windows。AMD员工重开Linux支持请求,回应用户需求。随着AI工作负载增长,期待AMD为Linux启用RyzenAI以与英特尔竞争。
| 导读 | 近日消息,最新的 AMD Ryzen 7040 系列笔记本电脑配备了基于 Xilinx IP 的专用 AI 引擎,名为“Ryzen AI”,可以加速 PyTorch 和 TensorFlow 等机器学习框架的运行。不过目前这个 Ryzen AI 只支持微软 Windows 系统。但是如果有足够的客户需求,这种情况可能会改变。 |
早在 6 月份,AMD 就在 GitHub 上发布了一些 Ryzen AI 的演示代码,其中一部分是开源的,但都只适用于 Windows,AMD 也没有发布任何 Ryzen AI Linux 驱动程序。
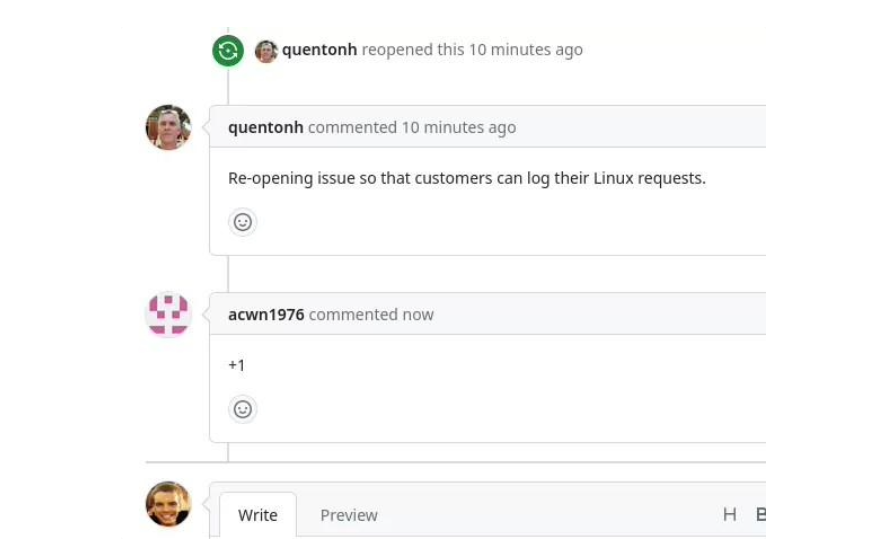
之后有人在 GitHub 上开了一个关于 Linux 支持的请求,但是三天后这个问题就被关闭了,没有任何解决方案或 Linux 支持计划被传达。
但今天这个 Linux 请求被 AMD 的一名员工重新打开了,理由是让(Linux)客户可以表达他们的需求: “重新打开问题,以便客户可以记录他们的 Linux 请求。”
在另一个关于 Linux 支持的请求中,也建议给 Linux 支持线程点赞(+1),如果有兴趣看到 Ryzen AI 支持 Linux:“请在#2 中添加一个“+1”的评论,以支持 Linux。”
目前 Ryzen AI 只在 Ryzen 7040 移动系列中提供,但可以预见的是,在他们未来的处理器中会出现更多的 Xilinx IP。考虑到 AI 工作负载的不断增加,以及英特尔已经在 Linux 6.3 中将其开源的 Meteor Lake VPU / NPU 支持主线化,并且甚至其下一代 NPU 已支持 Arrow Lake,希望 AMD 能够开始为 Linux 启用 Ryzen AI。

















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









