 Redis与Zookeeper实现分布式锁的对比分析
Redis与Zookeeper实现分布式锁的对比分析





 本文探讨了在分布式系统中解决库存超卖问题的必要性,引出了分布式锁的概念。分析了Java原生锁在多机部署场景下的局限性,提出使用Redis和Zookeeper作为分布式锁的解决方案。基于Redis的实现方式包括RedLock算法和Redisson框架,而基于Zookeeper的实现利用了其临时节点和事件监听特性。文章总结了两者在实现上的优缺点,并给出了选择分布式锁技术的建议,指出实际选型应考虑公司现有技术栈和场景需求。
本文探讨了在分布式系统中解决库存超卖问题的必要性,引出了分布式锁的概念。分析了Java原生锁在多机部署场景下的局限性,提出使用Redis和Zookeeper作为分布式锁的解决方案。基于Redis的实现方式包括RedLock算法和Redisson框架,而基于Zookeeper的实现利用了其临时节点和事件监听特性。文章总结了两者在实现上的优缺点,并给出了选择分布式锁技术的建议,指出实际选型应考虑公司现有技术栈和场景需求。
在讨论这个问题之前,我们先来看一个业务场景:
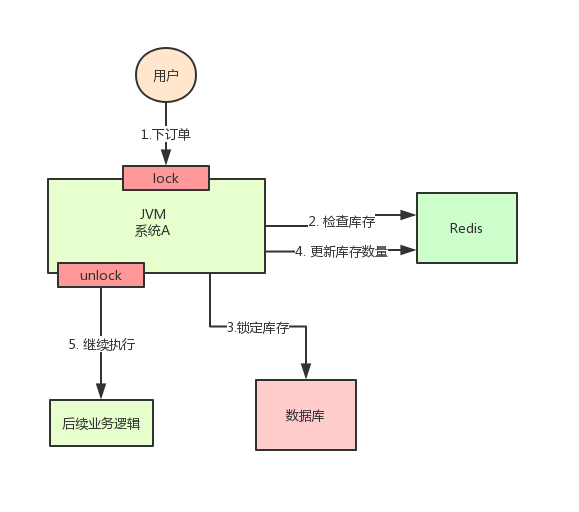
系统A是一个电商系统,目前是一台机器部署,系统中有一个用户下订单的接口,但是用户下订单之前一定要去检查一下库存,确保库存足够了才会给用户下单。
由于系统有一定的并发,所以会预先将商品的库存保存在redis中,用户下单的时候会更新redis的库存。
此时系统架构如下:

但是这样一来会产生一个问题:假如某个时刻,redis里面的某个商品库存为1,此时两个请求同时到来,其中一个请求执行到上图的第3步,更新数据库的库存为0,但是第4步还没有执行。
而另外一个请求执行到了第2步,发现库存还是1,就继续执行第3步。
这样的结果,是导致卖出了2个商品,然而其实库存只有1个。
很明显不对啊!这就是典型的库存超卖问题
此时,我们很容易想到解决方案:用锁把2、3、4步锁住,让他们执行完之后,另一个线程才能进来执行第2步。
按照上面的图,在执行第2步时,使用Java提供的synchronized或者ReentrantLock来锁住,然后在第4步执行完之后才释放锁。
这样一来,2、3、4 这3个步骤就被“锁”住了,多个线程之间只能串行化执行。
但是好景不长,整个系统的并发飙升,一台机器扛不住了。现在要增加一台机器,如下图:
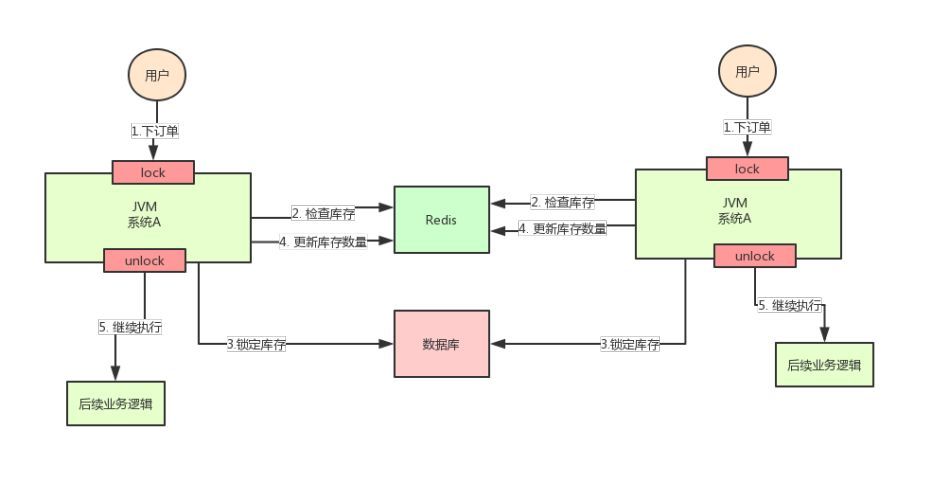
增加机器之后,系统变成上图所示,我的天!
假设此时两个用户的请求同时到来,但是落在了不同的机器上,那么这两个请求是可以同时执行了,还是会出现库存超卖的问题。
为什么呢?因为上图中的两个A系统,运行在两个不同的JVM里面,他们加的锁只对属于自己JVM里面的线程有效,对于其他JVM的线程是无效的。
因此,这里的问题是:Java提供的原生锁机制在多机部署场景下失效了
这是因为两台机器加的锁不是同一个锁(两个锁在不同的JVM里面)。
那么,我们只要保证两台机器加的锁是同一个锁,问题不就解决了吗?
此时,就该分布式锁隆重登场了,分布式锁的思路是:
在整个系统提供一个全局、唯一的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。
至于这个“东西”,可以是Redis、Zookeeper,也可以是数据库。
文字描述不太直观,我们来看下图:
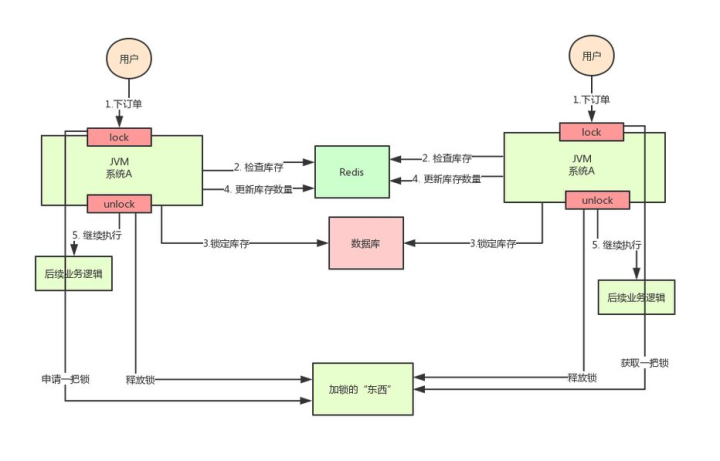
通过上面的分析,我们知道了库存超卖场景在分布式部署系统的情况下使用Java原生的锁机制无法保证线程安全,所以我们需要用到分布式锁的方案。
那么,如何实现分布式锁呢?接着往下看!
【文章福利】另外小编还整理了一些C++后台开发面试题,教学视频,后端学习路线图免费分享,需要的可以自行添加:学习交流群点击加入~ 群文件共享
小编强力推荐C++后台开发免费学习地址:C/C++Linux服务器开发高级架构师/C++后台开发架构师

基于Redis实现分布式锁
上面分析为啥要使用分布式锁了,这里我们来具体看看分布式锁落地的时候应该怎么样处理。
最常见的一种方案就是使用Redis做分布式锁
使用Redis做分布式锁的思路大概是这样的:在redis中设置一个值表示加了锁,然后释放锁的时候就把这个key删除。
具体代码是这样的:
// 获取锁
// NX是指如果key不存在就成功,key存在返回false,PX可以指定过期时间
SET anyLock unique_value NX PX 30000
// 释放锁:通过执行一段lua脚本
// 释放锁涉及到两条指令,这两条指令不是原子性的
// 需要用到redis的lua脚本支持特性,redis执行lua脚本是原子性的
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end这种方式有几大要点:
一定要用SET key value NX PX milliseconds 命令
如果不用,先设置了值,再设置过期时间,这个不是原子性操作,有可能在设置过期时间之前宕机,会造成死锁(key永久存在)
value要具有唯一性
这个是为了在解锁的时候,需要验证value是和加锁的一致才删除key。
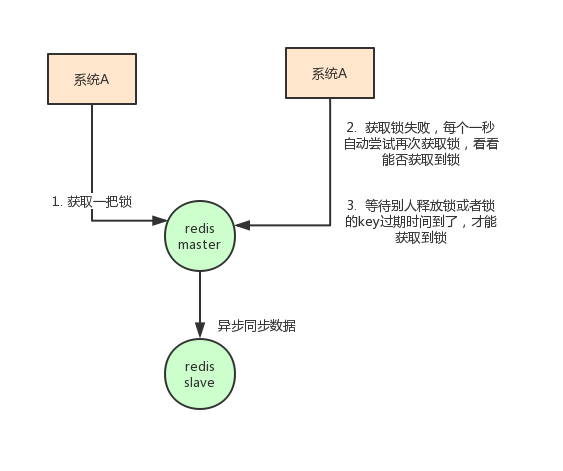
这是避免了一种情况:假设A获取了锁,过期时间30s,此时35s之后,锁已经自动释放了,A去释放锁,但是此时可能B获取了锁。A客户端就不能删除B的锁了。
 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









