




 本文介绍了Python的`bisect`模块如何用于管理已排序的序列,包括`bisect`函数在查找和保持序列升序时的作用,以及`bisect.insort`函数如何插入元素并保持有序。内容涵盖了`bisect`库、`sys`库和`random`库的使用,以及在Python脚本中利用`if name == 'main'`来控制代码执行的情况。
本文介绍了Python的`bisect`模块如何用于管理已排序的序列,包括`bisect`函数在查找和保持序列升序时的作用,以及`bisect.insort`函数如何插入元素并保持有序。内容涵盖了`bisect`库、`sys`库和`random`库的使用,以及在Python脚本中利用`if name == 'main'`来控制代码执行的情况。
# 用 bisect 管理已排序的序列
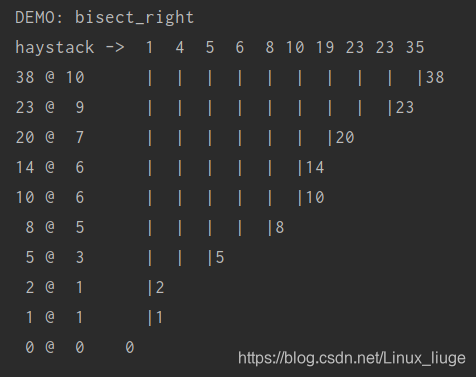
bisect(haystack, needle) 在 haystack(干草垛)里搜索 needle(指针)的位置,该位置满足的条件是,把needle插入这个位置后,haystack 还能保持升序
也就是说在这个函数返回的位置的前面的值,都小于或者等于needle的值,其中haystack必须是一个有序的序列
可以先用bisect查找位置index,再用haystack.insert(index, needle)插入新值,也可以直接使用后者
调用 bisect库 , sys 库及random库
import bisect
import sys
import random
num_hay = [1, 4, 5, 6, 8, 10, 19, 23, 23, 35] # 定义被插入数列
num_need = [0, 1, 2, 5, 8, 10, 14, 20, 23, 38] # 定义插入数列的数列
row_fmt = '{0:2d} @ {1:2d} {2}{0:<2d}' # 定义数据显示格式
def demo(bisect_fn):
"""定义测试bisect的函数"""
for needle in reversed(num_need): # reversed() 返回一个反转的迭代器即将数列倒序。只能进行一次循环遍历。显示一次所包含的值!
position = bisect_fn(num_hay, needle) # 使用bisect(haystack, needle)函数查询指针位置(第1个数之前为0,第1个数之后为1,第2个数之后为2 )
offset = position * ' |' # 通过 pisition 计算制表需要的 “ |” 数
print(row_fmt.format(needle, position, offset)) # 将数据填入定义好的数据显示格式(row_fmt)中
if __name__ == '__main__':
if sys.argv[-1] == 'left': # 执行脚本文件时,python3 脚本文件名 left 即定义数值从位置左侧插入
bisect_fn_1 = bisect.bisect_left
else:
bisect_fn_1 = bisect.bisect # bisect.bisect 实际上就是bisect.bisect_right 前者是别名
print('DEMO:', bisect_fn_1.__name__) # 打印上面判断的函数名
print('haystack ->', ' '.join('%2d' % n for n in num_hay)) # str.join()通过指定字符连接序列中元素后生成的新字符串。str为指定字符
demo(bisect_fn_1) # 调用函数demo
一个python的文件有两种使用的方法,第一是直接作为脚本执行,第二是import到其他的python脚本中被调用(模块重用)执行。
而当一个.py文件作为模块被导入时,我们可能不希望一部分代码被运行。
所以在if name == ‘main’: 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而import到其他脚本中是不会被执行的。
所以如果说定义的某一部分代码只需要在本脚本文件中使用的情况下,就写在if name == ‘main’:语句下。
# bisect可以用来建立一个用数字作为索引的查询表格,比如说把分数和成绩对应起来
def grade(score):
"""定义函数grade() 的默认值,score表示要查询的成绩,breakpoints表示成绩划分的界限,grades表示对应输出的成绩等级。"""
breakpoints = [60, 70, 80, 90]
grades = 'FDCBA'
a = bisect.bisect(breakpoints, score) # 利用bisect()函数来找出在breakpoints中的位置
return grades[a] # 然后利用对应返回值,作为索引打印grades中的对应成绩等级
print([grade(score) for score in [33, 58, 67, 85, 97]])

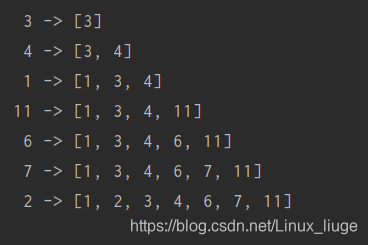
# bisect.insort 插入新元素
insort(seq, item)把变量item插入到有序序列seq中,并能保持seq的升序顺序。
调用bisect库以及random库(顶端)
random.seed(4) # random.seed() 表示固定随机生成的数列,不会每次都变。seed()的值任意指定。
my_list = []
for i in range(7):
new_items = random.randrange(14)
bisect.insort(my_list, new_items)
print(str('{:2d} ->'.format(new_items)), my_list)
本文为作者学习整理笔记,文章来源:《流畅的python》

















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









