




本系列将讲解《汇编语言》一书,本节讲解第7章——更灵活的定位内存地址的方法。
前面,我们用[0]、[bx]的方法,在访问内存的指令中,定位内存单元的地址。本章我们主要通过具体的问题来讲解一些更灵活的定位内存地址的方法和相关的编程方法。
|
|
|---|
| 1.and和or指令 |
| 2.处理ascii码的本质讲解 |
| 3.5大寻址方式 |
| 4.综合测试-双重循环处理 |
一、and和or指令
1.定义
| 指令使用 | 解释 |
|---|---|
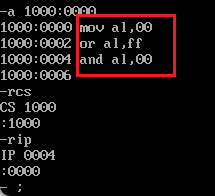
| and al,11111111b | 将ax寄存器与二进制数11111111b相与,结果为11111111 |
| or al,00000000b | 将ax寄存器与二进制数00000000b相或,结果为00000000 |
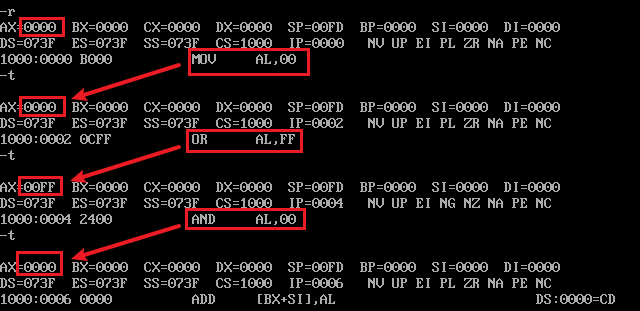
2.实战
前置阅读:😉【DOSBox】1-debug
||
V
二、处理ascii码的本质讲解
1.按下键盘到显示字符的过程
世界上有很多编码方案,有一种方案叫做ASCII编码,是在计算机系统中通常被采用的。
简单地说,所谓编码方案,就是一套规则,它约定了用什么样的信息来表示现实的对象。比如说,在ASCII编码方案中,用61H表示“a”,62H表示“b”。一种规则需要人们遵守才有意义。
在文本编辑过程中,我们按一下键盘的a键,就会在屏幕上看到“a”这是怎样一个过程呢?我们安下键盘的 a键,这个按键的信息被送入计算机,计算机用 ASCII 码的规则对其进行编码,将其转化为61H存储在内存的指定空间中;文本编辑软件从内存中取出61H,将其送到显卡上的显存中:工作在文本模式下的显卡,用ASCII码的规则解释显存中的内容61H被当作字符“a”,显卡驱动显示器,将字符“a”的图像画在屏幕上。
(至于这里怎么画的,我们就不必了解了,知识屏蔽即可。)我们可以看到,显卡在处理文本信息的时候,是按照ASCI码的规则进行的。这也就是说,如果我们要想在显示器上看到“a”写入显存中。
-
就要给显卡提供“a”的ASCII码,61H。
-
如何提供?当然是写入显存中。
-
如何写入?当然是从键盘驱动。
2.利用ascii编程
源码:
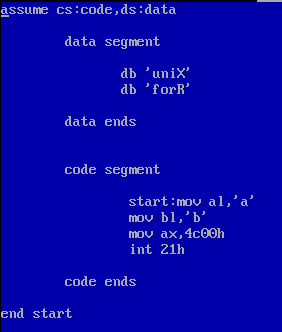
1.查看数据段
本程序没有执行data段,仅仅是将数据写入数据段中。我们使用-d ds+10h:0000查看内容:
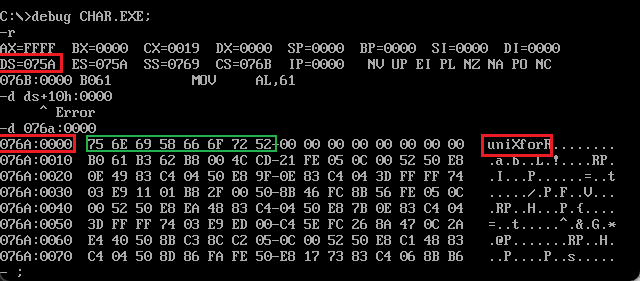
这个实验充分证明了可以使用字符代替写入显存中,本质上字符也会翻译成对应的ASCII码,这是本质。所以应该说字符是ASCII码的包装。
为什么ds=075a,那么076a:0000处才是我们真实的数据?请移步此处查看: 【DOSBox】2-debug可执行文件-DOS加载可执行文件的过程
2.查看代码段
直接使用r命令执行代码,并使用t命令往下执行:
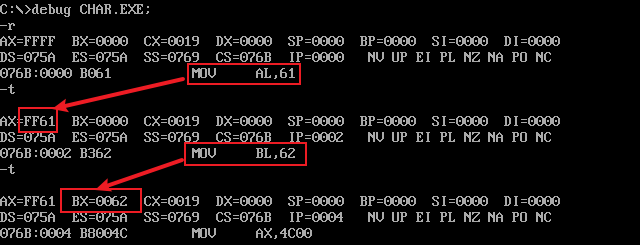
显然此处使用’a’'b’的本质就是61H,62H。编译器都自动转化了。
三、5种灵活的寻址方式
(1)[idata]用一个常量来表示地址,可用于直接定位一个内存单元;
(2)[bx]用一个变量来表示内存地址,可用于间接定位一个内存单元;
(3)[bx+idata]用一个变量和常量表示地址,可在一个起始地址的基础上用变量间接定位一个内存单元;
(4)[bx+si]用两个变量表示地址;
(5)[bx+si+idata]用两个变量和一个常量表示地址。
可以看到,从[idata]一直到[bx+si+idata],我们可以用更加灵活的方式来定位一个内存单元的地址。这使我们可以从更加结构化的角度来看待所要处理的数据。
注意,所谓寻址方式,无非就是常数、寄存器、寄存器与寄存器、寄存器与常数这些叠加。不用记专用什么间接寻址、基址寻址等晦涩的名字。计算机是实践学科,不是靠记忆的!
下面我们通过个问题的系列来体会CPU提供多种寻址方式的用意,并学习一些相关的编程技巧。
四、实战——双重循环
1.问题
编程,将 datasg 段中每个单词的头一个字母改为大写字母
assume cs:codesg,ds:datasg
datasg segment
db '1. file ' ;注意这里每一串16个字符,也就是16个字节每行
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
datasg ends
codesg segment
start:
codesg ends
end start
2.问题分析
1.大小写转换
注意,因为同一字符的大小的ASCII码之间仅仅相差32,这也正是2的5次方,所以完全可以使用码点增加32或者减少32来实现大小写转换,那么如何快速实现增加32或者减少32呢?
- 显然,小写字符的32位一定是1,因为它的码点大;小写字符的32位一定是0,因为它的码点小;所以我们完全可以使用与或指令来完成特定二进制位的置0置1。
对应的C代码:
#include <stdio.h>
int main(void)
{
int char_a = 'a';
printf("%c %c\n", char_a, char_a & 0b11011111); // 减少32
int char_A = 'A';
printf("%c %c\n", char_A, char_A | 0b00100000); // 多出32
return 0;
}
结果:

对应汇编
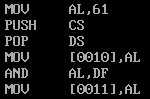
查看结果:

||
V

2.正式的源码
①使用单层循环
显然,我们每次处理一行16个字节,那么有一个最初的变量用于记录每一行的起始地址,另一个变量用做偏移地址,遍历该行,并且该变量每到一行,都要重新置0,意为重新遍历。
assume cs:codesg,ds:datasg
datasg segment
db '1. file ' ;注意这里每一串16个字符,也就是16个字节每行
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
datasg ends
codesg segment
start:
;注意从编译器给定的地址datasg这里开始进行转换
mov ax,datasg;用作数据起始地址
mov ds,ax;用ds承接数据起始地址
mov cx,6;设置循环次数
mov bx,0;用做偏移地址
s: and byte ptr ds:[bx+2], 0dfh
add bx,16;每次增加16个字符,换到下一行
loop s
codesg ends
end start

②使用双层循环
上面的程序是使用单层循环的,固定了偏移量为3,但是我们可以将这个环节变成循环。从而有了两层循环的代码:
assume cs:codesg,ds:datasg
datasg segment
db '1. file ' ;注意这里每一串16个字符,也就是16个字节每行
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
datasg ends
codesg segment
start:
mov ax,datasg
mov ds,ax
mov cx,6;外层循环
mov bx,0;定位行数
s1:
push cx;保存外层循环
mov cx,4;每一层的偏移,这里可以改为1,就是首字母大写,也可以改为4,就是四个字母大写
xor si,si
s2:
and byte ptr ds:[bx+si+3],0dfh;最佳实践,bx基地址,si偏移地址,3是固定偏移
inc si
loop s2
add bx,16
pop cx
loop s1
mov ax,4c00h ; 程序正常退出
int 21h
codesg ends
end start
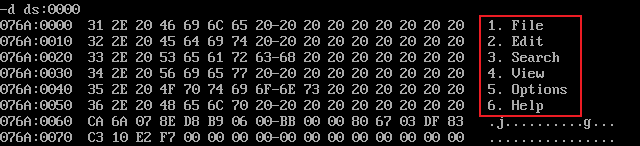
执行结果:

重点在于二层循环,两个注意点:
| 二层循环,两个注意点 |
|---|
| 1.每一层循环都是用的cx,只不过使用push和pop进行保存前一层的循环次数。 |
| 2.基地址使用bx,偏移地址使用si,记住了,这是计算有效地址的规定,也是最佳实践。 |
结尾
好了,本节我们讲述了【汇编语言】第6章包含多个段的程序的基础知识,让我们再来回顾回顾:
|
|
|---|
| 1.and和or指令是指? |
| 2.用and和or指令进行大小写转换的原理是? |
| 3.讲解ASCII码的本质? |
| 3.5大寻址方式是? |
| 4.在X86中,循环次数、基地址、偏移地址分别是用什么寄存器保存?(cx,bx,si) |
| 5.双重循环的循环次数转接是怎么实现的? |
如果您不能对着这个表格给出每一项的讲解,那么,再把上面的内容好好复习一遍吧!
答案见评论区,欢迎大家讨论~

专注讲解Linux中的常用命令,共计发布100+文章。
本系列将精讲Linux0.11内核中的每一个文件,共计会发布100+文章。
和Linux内核102系列不同,本系列将会从全局描绘Linux内核的各个模块,而非逐行源码分析,适合想对Linux系统有宏观了解的家人阅读。
😉【Linux】Linux概述1-linux对物理内存的使用
关于小希
😉嘿嘿嘿,我是小希,专注Linux内核领域,同时讲解汇编和C语言等知识。
我的wx:C_Linux_Cloud,期待与您学习交流!

加wx请备注哦
小希的座右铭:
别看简单,简单也是难。别看难,难也是简单。我的文章都是讲述简单的知识,如果你喜欢这种风格:
下一期想看什么?在评论区留言吧!我们下期见!

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









