



简介
该脚本旨在通过Python自动化处理Excel表格数据,实现最小二乘法(OLS)线性回归分析。用户只需输入自变量和因变量所在的列号,脚本将自动完成数据读取、模型拟合及结果输出,适用于统计分析、数据建模等场景。
1. 配置环境:
如果说未配置Python环境,可参考以下步骤进行配置
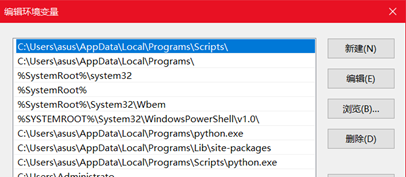
查找现有环境变量
在环境变量窗口的“用户变量”(仅影响当前账户)或“系统变量”(影响所有用户)列表中,滚动查找目标变量名(如 PATH)。若需确认变量是否存在,可点击列表并通过键盘输入首字母快速定位。
编辑现有变量
选中目标变量(如 PATH)后点击“编辑”,在变量值末尾添加新路径时需注意:
路径之间用英文分号 ; 分隔,末尾无需分号。
路径需为绝对路径(例如 C:\Program Files\Java\bin),避免使用相对路径。
若路径包含空格或特殊字符,无需额外引号,系统会自动处理。
新建环境变量
若变量不存在,点击“新建”并输入:
变量名:通常为大写(如 JAVA_HOME),遵循编程规范。
变量值:根据需求填写(如 C:\Program Files\Java\jdk-17)。
验证配置
保存后需执行以下操作生效:
重启终端:关闭所有已打开的CMD、PowerShell或IDE窗口,重新启动。
全局生效:部分程序需重启操作系统或注销重新登录。
验证命令:在终端输入 echo %PATH%(Windows)或 echo $PATH(Linux/macOS)检查路径是否包含新增值。
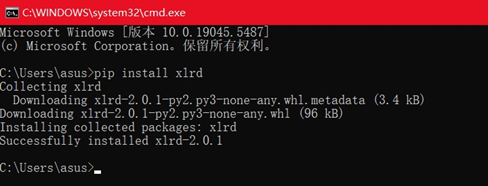
2. 在命令提示符中下载xlrd库
pip install xlrd
3.代码演示
import pandas as pd
import numpy as np
import statsmodels.api as sm
def main():
# 读取Excel文件
file_path = input("请输入Excel文件路径:")
try:
df = pd.read_excel(file_path)
except Exception as e:
print("文件读取失败:{}".format(str(e)))
return
# 显示数据预览(带Excel列号)
print("\n[数据预览] 列号对应关系:")
print("Excel列号 | 列名")
print("-------------------")
for i, col in enumerate(df.columns, 1):
print(" {:2d} | {}".format(i, col)) # 修改此处
print("\n前5行数据:")
print(df.head())
# 获取用户输入
try:
y_col = int(input("\n请输入因变量的Excel列号(单个数字):")) - 1
x_cols = [int(x)-1 for x in input("请输入自变量的Excel列号(多个用空格分隔):").split()]
except ValueError:
print("错误:请输入有效的数字列号")
return
# 验证列号有效性
max_col = len(df.columns) - 1
if y_col < 0 or y_col > max_col or any(x < 0 or x > max_col for x in x_cols):
print("错误:列号应在1-{}之间".format(len(df.columns))) # 修改此处
return
# 准备数据
X = df.iloc[:, x_cols]
y = df.iloc[:, y_col]
# 处理缺失值
data = pd.concat([X, y], axis=1).dropna()
if data.empty:
print("错误:数据中存在缺失值,删除后无剩余数据")
return
X_clean = data.iloc[:, :-1]
y_clean = data.iloc[:, -1]
# 添加常数项
X_clean = sm.add_constant(X_clean)
# 执行回归
try:
model = sm.OLS(y_clean, X_clean)
results = model.fit()
except Exception as e:
print("回归分析失败:{}".format(str(e))) # 修改此处
return
# 打印结果
print("\n" + "="*50)
print("回归分析结果(因变量:{})".format(df.columns[y_col])) # 修改此处
print("="*50)
print(results.summary())
# 输出关键参数
print("\n关键参数:")
print("R-squared: {:.4f}".format(results.rsquared))
print("Adj R-squared: {:.4f}".format(results.rsquared_adj))
print("\n系数:")
for name, coef in zip(X_clean.columns, results.params):
print("{:>15}: {:.6f}".format(name, coef)) # 修改此处
if __name__ == "__main__":
main()
4.页面展示
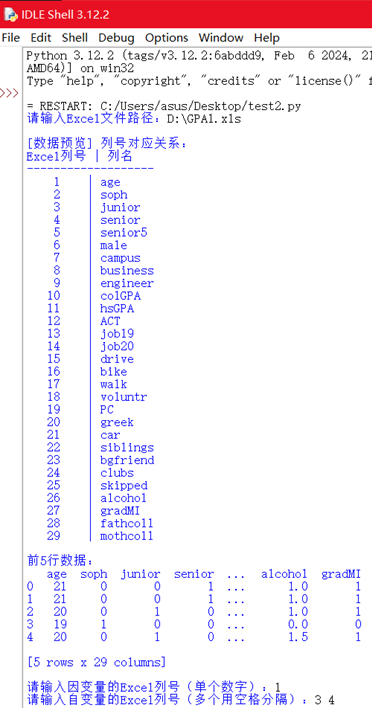
在此处输入excel的文件路径

在此处输入要分析excel的因变量列号,以及在下一行输入自变量列号

5.输出结果展示
1.列出所有列名,以及前五行数据
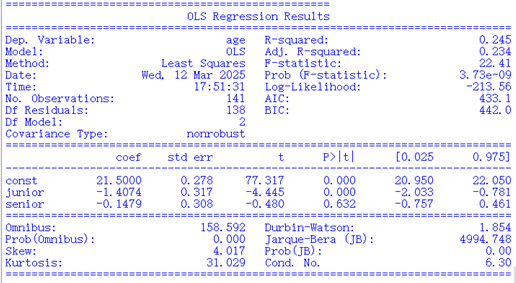
2.ols回归分析结果展示


















 1397
1397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











