




 本文详细介绍了使用Python的BeautifulSoup库进行网页数据抓取的方法,包括解析HTML文档、查找特定元素、提取图片链接及处理复杂属性等高级技巧,是网络爬虫开发者的实用指南。
本文详细介绍了使用Python的BeautifulSoup库进行网页数据抓取的方法,包括解析HTML文档、查找特定元素、提取图片链接及处理复杂属性等高级技巧,是网络爬虫开发者的实用指南。
################################################################
from urllib.request import urlopen from bs4 import BeautifulSoup html=urlopen('http://www.pythonscraping.com/pages/page3.html') bs=BeautifulSoup(html, 'html.parser')
#find_all(tag, attributes, recursive, text, limit, keywords)
nameList = bs.findAll('span', {'class':'green'})
for name in nameList:
print(name.get_text())
nameList = bs.find_all(text='the prince')########
print(len(nameList))
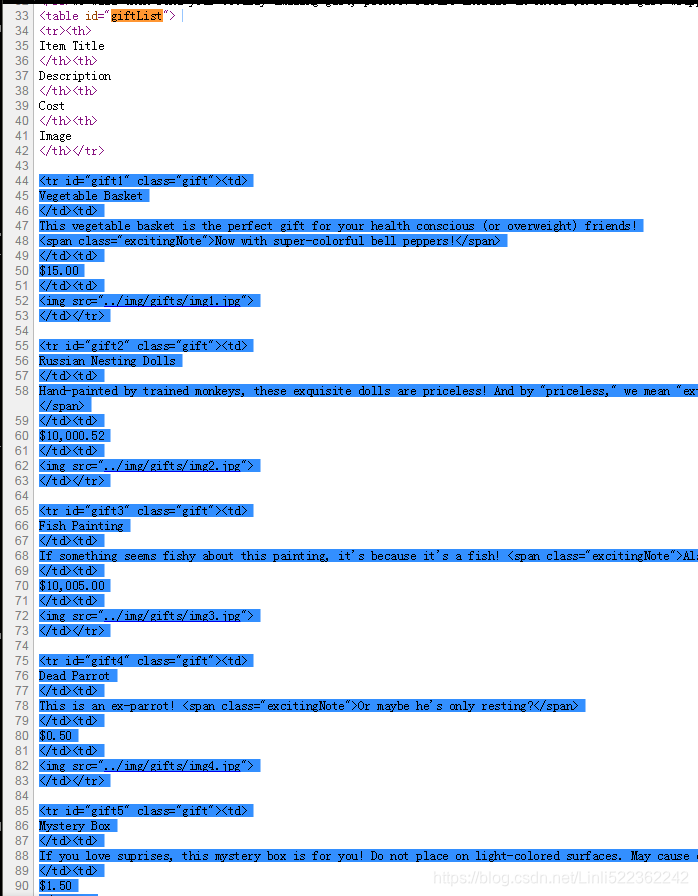
for child in bs.find('table', {'id':'giftList'}).children:
print(child)
for sibling in bs.find('table', {'id':'giftList'}).tr.next_siblings:
print(sibling)
#<img src="../img/gifts/img1.jpg">
print(bs.find('img', {'src':'../img/gifts/img1.jpg'}
).parent.previous_sibling.get_text()
)# $15.00
#<td>$15.00</td>
#<td><img src="../img/gifts/img1.jpg"></td></tr>
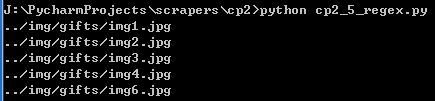
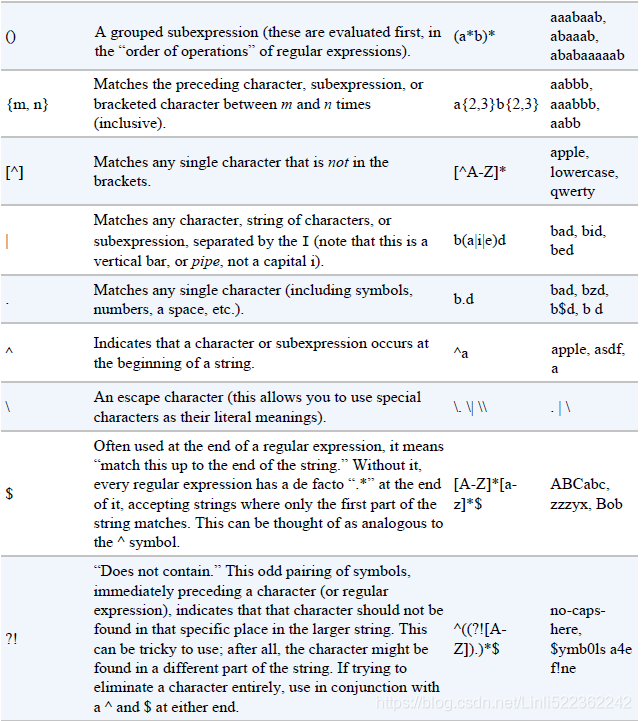
images = bs.find_all('img', {'src':re.compile('\.\.\/img\/gifts\/img.*\.jpg')})
#images = bs.find_all('img', {'src':re.compile('\.\.\/img\/gifts/img.*\.jpg')})
for image in images:
print(image['src'])
# the following retrieves all tags that have exactly two attributes:
print(
bs.find_all(lambda tag: len(tag.attrs)==2)
)
That is,
it will find tags with two attributes, such as the following:
<div class="body" id="content"></div>
<span style="color:red" class="title"></span>
################################################################
bs.find_all(lambda tag: tag.get_text() ==
'Or maybe he\'s only resting?')
This can also be accomplished without a lambda function:
bs.find_all('', text='Or maybe he\'s only resting?')
![]()
################################################################
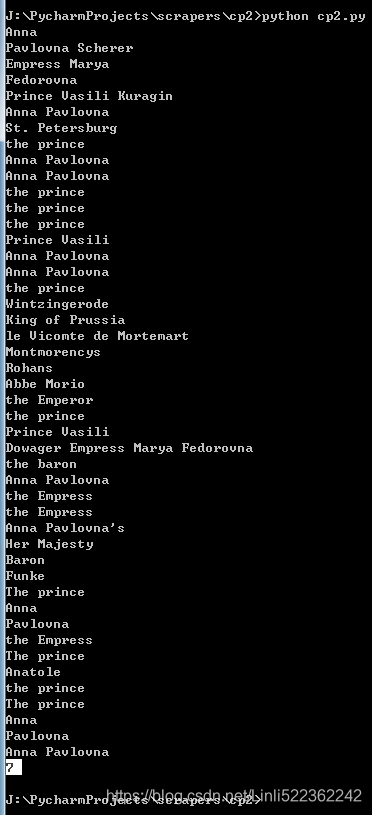
from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen('http://www.pythonscraping.com/pages/warandpeace.html') bs = BeautifulSoup(html.read(), 'html.parser') #find_all(tag, attributes, recursive, text, limit, keywords) nameList = bs.findAll('span', {'class':'green'}) for name in nameList: print(name.get_text()) nameList = bs.find_all(text='the prince') ############ print(len(nameList))
Result:
http://www.pythonscraping.com/pages/warandpeace.html

...

################################################################
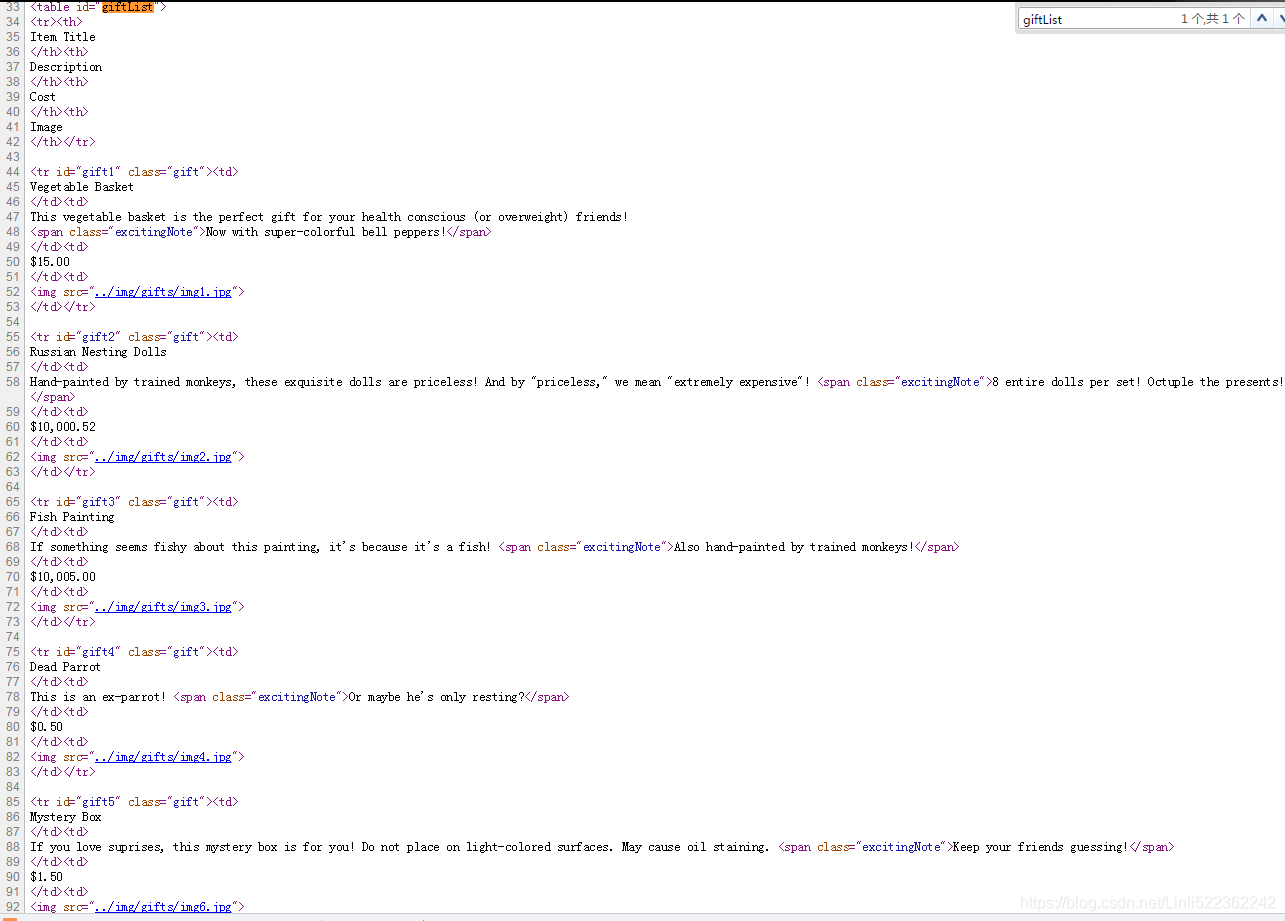
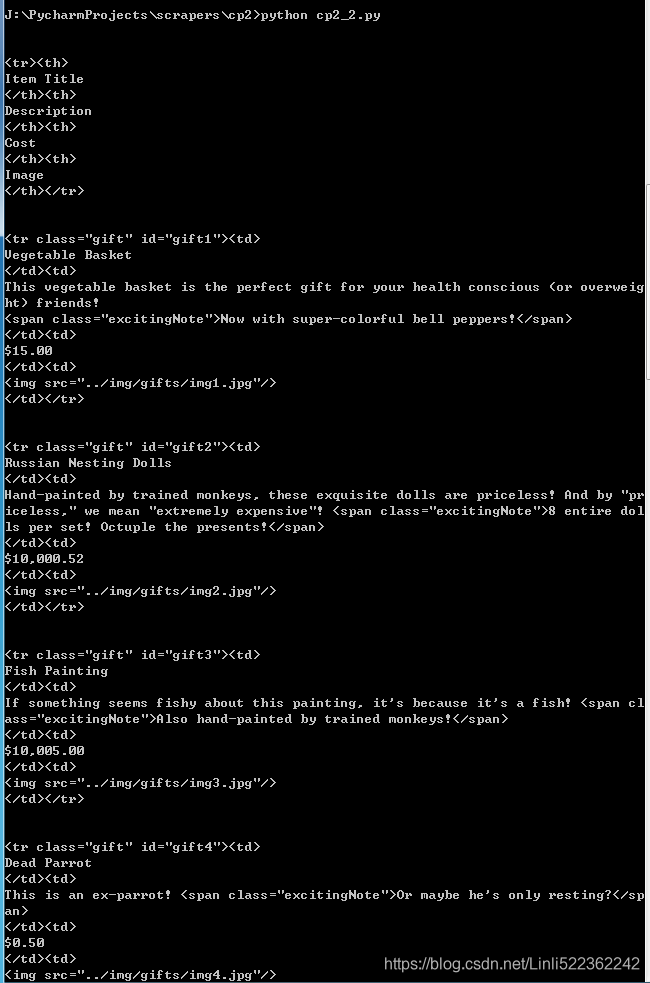
from urllib.request import urlopen from bs4 import BeautifulSoup html=urlopen('http://www.pythonscraping.com/pages/page3.html') bs=BeautifulSoup(html, 'html.parser') #.descendants for child in bs.find('table', {'id':'giftList'}).children: print(child)
Result:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html, 'html.parser')
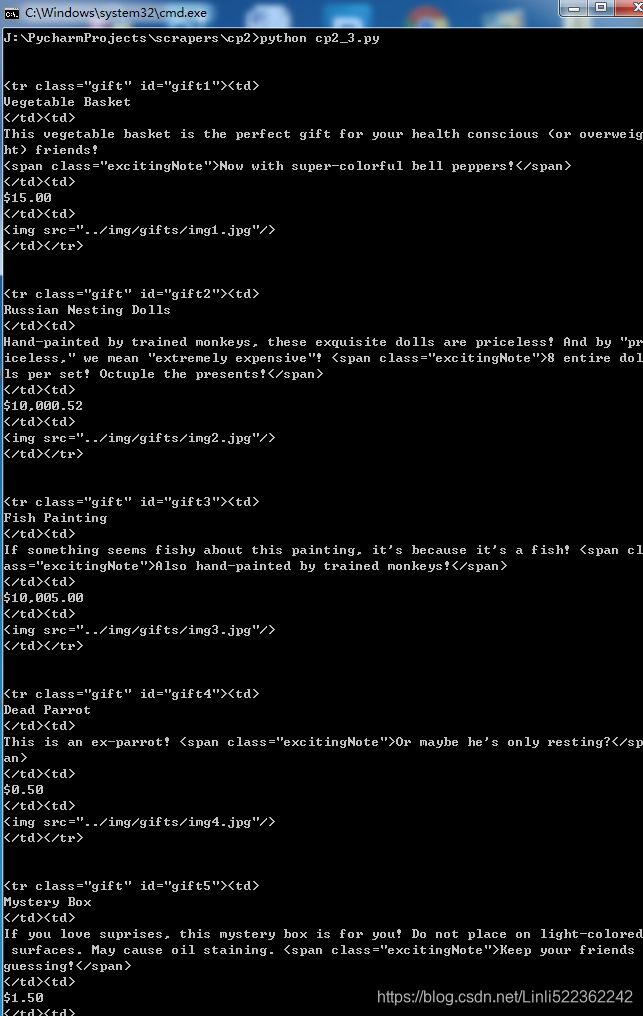
for sibling in bs.find('table', {'id':'giftList'}).tr.next_siblings:
print(sibling)
Result:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html, 'html.parser')
#<img src="../img/gifts/img1.jpg">
print(bs.find('img', {'src':'../img/gifts/img1.jpg'}
).parent.previous_sibling.get_text()
)# $15.00
#<td>$15.00</td>
#<td><img src="../img/gifts/img1.jpg"></td></tr>


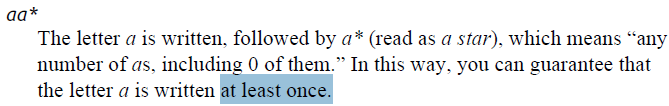

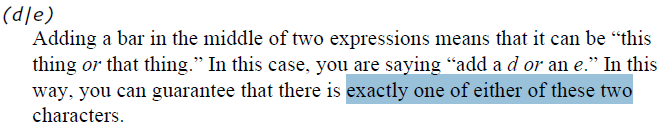

![]()
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html, 'html.parser')
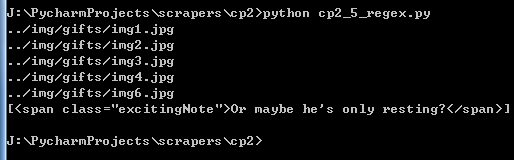
images = bs.find_all('img', {'src':re.compile('\.\.\/img\/gifts\/img.*\.jpg')})
for image in images:
print(image['src'])
print(
#bs.find_all(lambda tag: len(tag.attrs)==2)
bs.find_all(lambda tag: tag.get_text() == 'Or maybe he\'s only resting?')
)


















 3875
3875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











