



-Mysql——从根上理解mysql
B+树的应用
CREATE TABLE person_info(
id INT NOT NULL auto_increment,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name, birthday, phone_number)
);
id是主键列,存储了一个自动递增的整数,
所以InnoDB引擎会自动为id列建立聚簇索引。
而idx_name_birthday_phone_number是一个二级索引,三个列组成的联合索引,B+树的叶子结点只会存储用户信息的name,birthday,phone_number这三个列的值,以及主键ID的值。
所以有多少索引就会建立多少B+树
因此在这个例子里,person_info 表会为聚簇索引和idx_name…索引建立两颗B+树,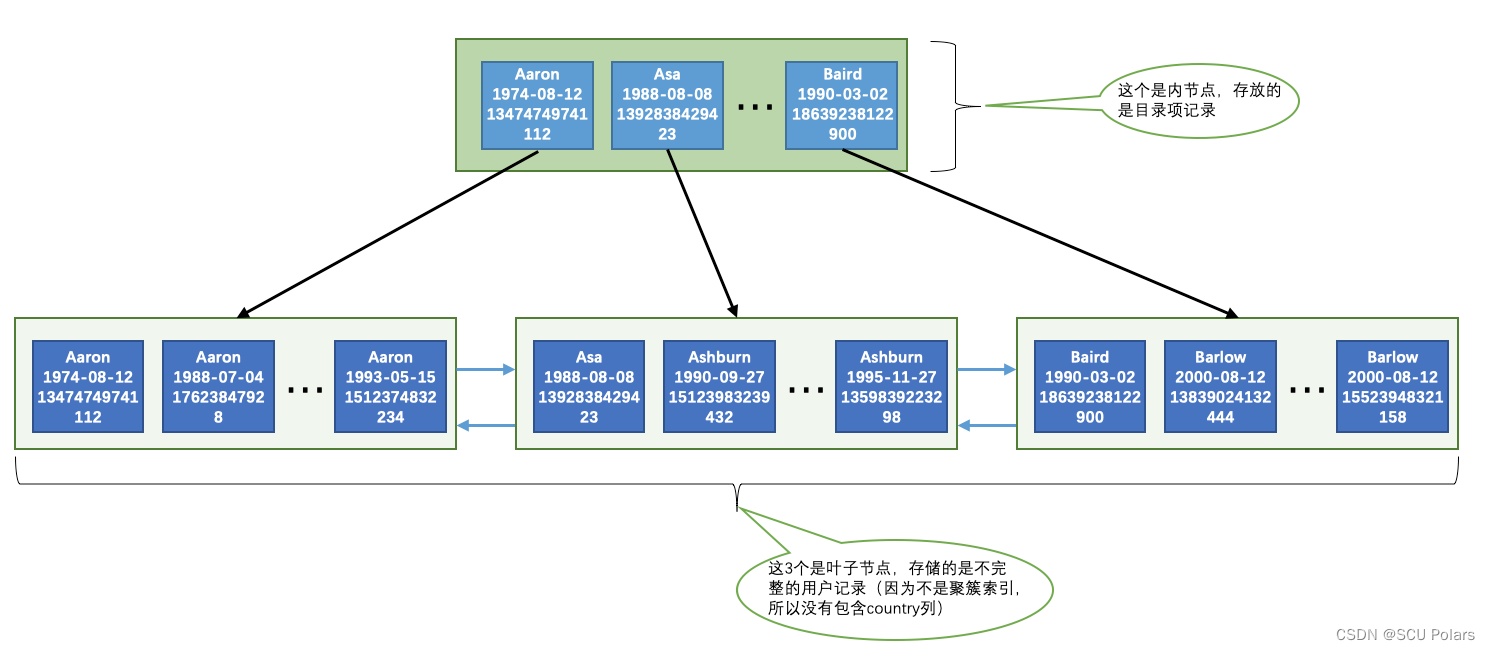
内结点中存储的是目录项记录,叶子节点中存储的是用户记录。
先按照name列的值进行排序。
如果name列的值相同,则按照birthday列的值进行排序。
如果birthday列的值也相同,则按照phone_number的值进行排序。
全值匹配
如果搜索条件中的列和索引列一致,这种情况就称为全值匹配。
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday = '1990-09-27' AND phone_number = '15123983239';
关注一下这个B+树的查询过程
1.由于B+树的数据页和记录先是按照name列的值在这里插入代码片进行排序的,可以很快定位到name是Ashburn的记录位置。
2.在name列相同的记录又是按照birthday列的值进行排序的,所以在name列的值是Ahburn的记录里又可以快速定位到值为1990-09-27的记录。
3.如果name和birthday都相同,那么就按照phone_number排序,所以联合索引中三个列都会用到。
- 如果我们尝试去调换查询语句中条件的顺序,会对结果产生影响吗?
比如调换为:
SELECT * FROM person_info WHERE birthday = '1990-09-27' AND phone_number = '15123983239' AND name = 'Ashburn';
答案是没有影响,因为MySQL有一个查询优化器,会分析搜索条件决定先后使用顺序。
匹配左边的列
例如如下查询语句:
SELECT * FROM person_info WHERE name = 'Ashburn';
或者包含多个左边的列:
比如
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday = '1990-09-27';
搜索条件中出现左边的列才可以使用到这个B+树索引,比如下面的语句就用不到B+树
SELECT * FROM person_info WHERE birthday = '1990-09-27';
- 因为B+树的数据页和记录是先按照name列的值进行排序的,在name列值相同的个时候birthday列才有序,也就是说当name值不相同、也就是说不是左边匹配列的时候,birthday的值是无序的。
- 如果真的想查询birthday,那么就对birthday列创建一个B+树索引。
如果我们在联合索引中,搜索条件有中间的空缺,例如搜索条件只有name和phone_number的话,缺了中间的birthday,就比如:
SELECT * FROM person_info WHERE name = 'Ashburn' AND phone_number = '15123983239';
就只能用到name列的索引,后面两个就用不上了,因为只有birthday相同的记录才会对phone_number排序。
匹配列前缀
就以这个例子来说,name列的排列应该是这样的:
Aaron
Aaron
…
Aaron
Asa
Ashburn
…
Ashburn
Baird
Barlow
…
Barlow
字符串排序本质上也是一个个字符比较来排序的,因此我们可以通过匹配词前缀来快速定位记录。
如果我们想查询**以’AS‘**开头的语句,可以这样查询:
SELECT * FROM person_info WHERE name LIKE 'As%';
如果只给出后缀或者中间的某个字符串,可以这样:
SELECT * FROM person_info WHERE name LIKE '%As%';
这二者的不同点在于,第一个查询语句可以根据As已经排好序这件事来快速定位,但第二个查询语句中并没有前面的匹配,就只能全表扫描了。
- 所以这里有一个比较鸡贼的方法:
例如一个表中有url列,大概如下:
±---------------+
| url |
±---------------+
| www.baidu.com |
| www.google.com |
| www.gov.cn |
| … |
| www.wto.org |
±---------------+
如果想查询以com为后缀的网址,可以写WHERE url LIKE ’%com' 但是不难看出,我们依然无法用该url列的索引,为了不全盘扫描,可以把后缀查询写成前缀查询,怎么实现呢,逆序存储一下表中数据就可以了:
±---------------+
| url |
±---------------+
| moc.udiab.www |
| moc.elgoog.www |
| nc.vog.www |
| … |
| gro.otw.www |
±---------------+
这样就可以用 `WHERE url LIKE ‘moc%’ 啦。


















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











