




 自编码器是一种无监督学习方法,通过神经网络进行数据编码和解码,实现特征提取。文章介绍了不同类型的自编码器,包括不完整的自编码机用于执行PCA,栈式自编码器用于逐层学习,降噪编码器增强模型鲁棒性,稀疏自编码器减少神经元相关性,以及变分自编码器用于数据生成和增强。
自编码器是一种无监督学习方法,通过神经网络进行数据编码和解码,实现特征提取。文章介绍了不同类型的自编码器,包括不完整的自编码机用于执行PCA,栈式自编码器用于逐层学习,降噪编码器增强模型鲁棒性,稀疏自编码器减少神经元相关性,以及变分自编码器用于数据生成和增强。
自编码机可以认为是一种无监督学习方式,它的神奇之处在于,通过自编码机,我们可以自动地从数据所有输入特征中,精炼特征。
预测模型
自编码机的精髓在于,它将同样的数据作为神经网络的两端,进行训练,使得原始数据能够经过神经网络进行编码,然后再解码,恢复到原来的模样。如下图结构所示:

输入在最中间的一层获得编码。
在大体上,损失模型和训练方法与普通神经网络类似。但是下面讲一些具体的自编码机,他们都具有这种基础结构,但是在细节上又有所不同。
不完整的自编码机(用于执行PCA)
当自编码机最中间的编码层神经元数量少于输入时,我们称其为不完整的。在这个时候,我们可以从高维输入特征中提取出低维特征。
一般而言,自编码机采用线性激活,并且使用均方误差作为损失函数,便可以执行PCA分析。
栈式自编码器
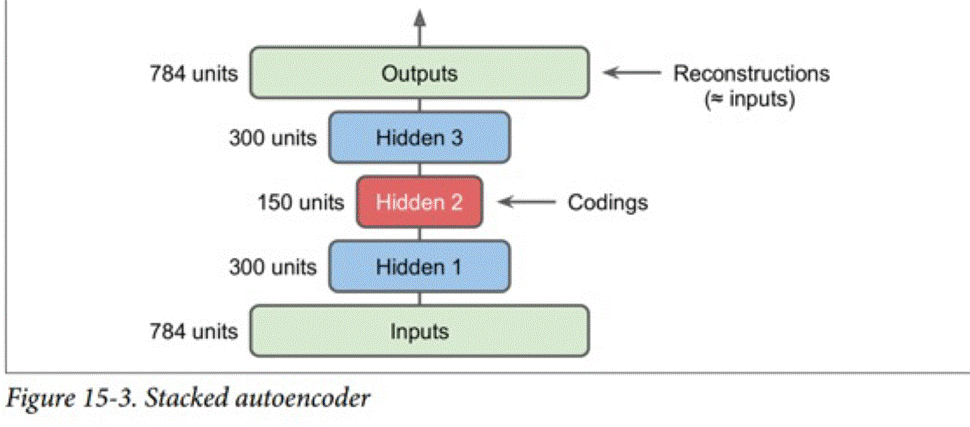
栈式自编码器如图所示,它两侧对称,逐层递进,相对称的两层采用相同的权值。
对于栈式自编码器的训练,我们一般逐层进行,一般有如下两种方式
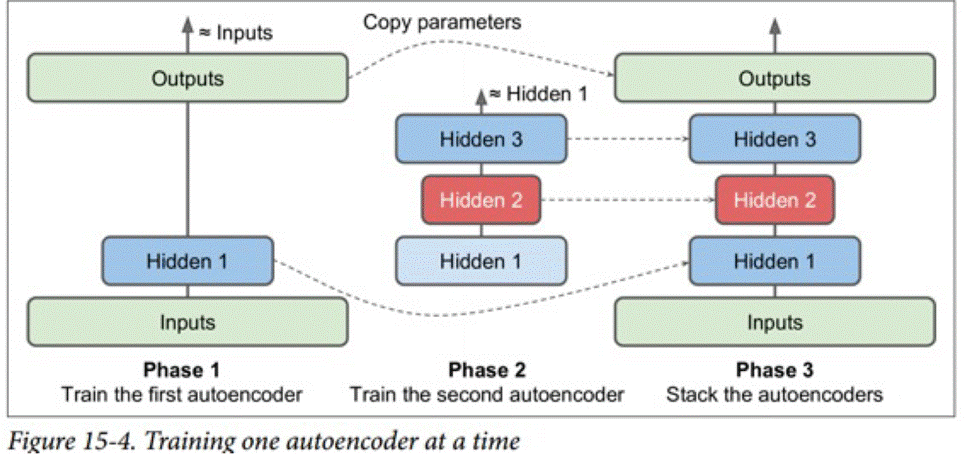
(将整个自编码器分为多个神经网络)
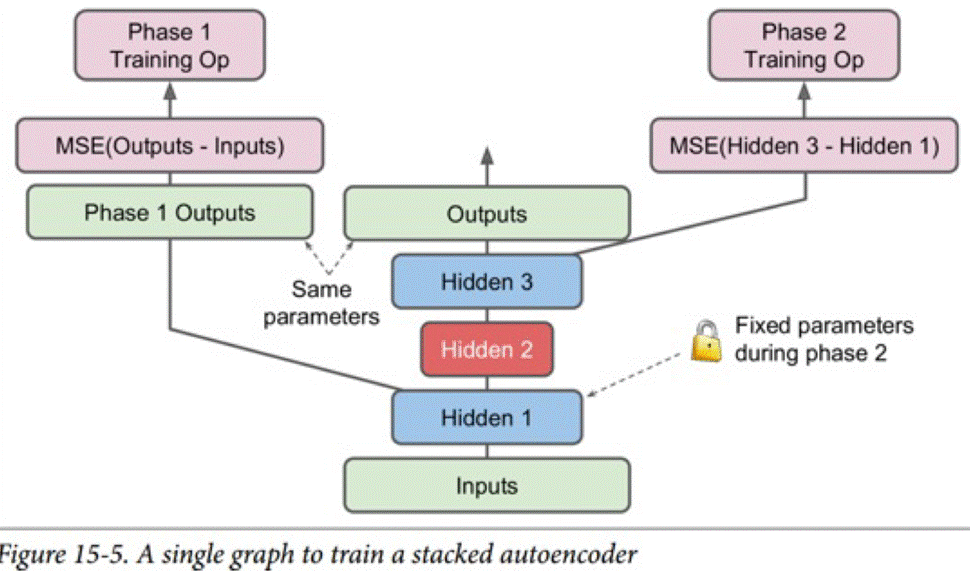
(作为一个神经网络进行训练)
当我们手里没有足够的标注数据时,我们可以可以先采用栈式自编码器训练出底层网络,然后再用标注数据进行进一步学习。
降噪编码器
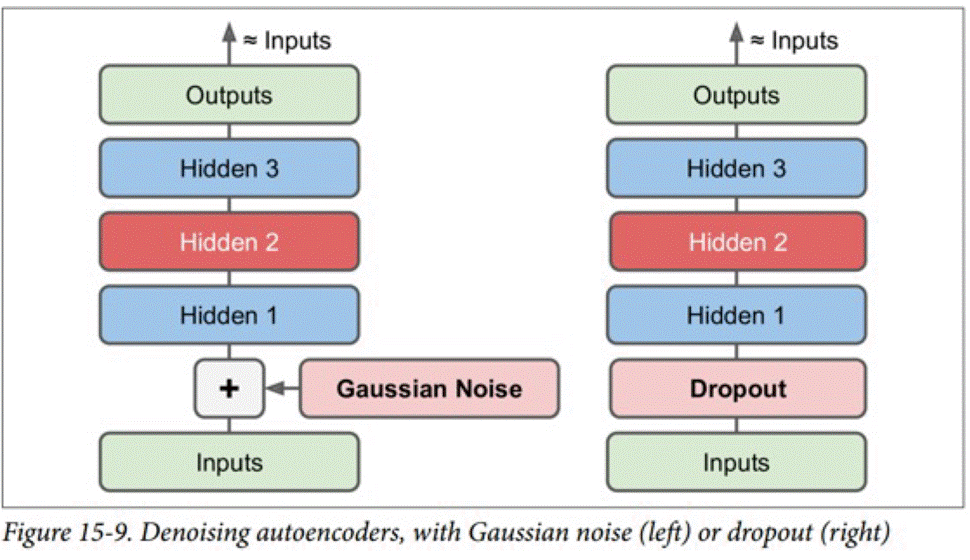
通过对输入数据加入高斯噪音,或者进行适当的dropout,我们可以得到适应性更强的降噪编码器。
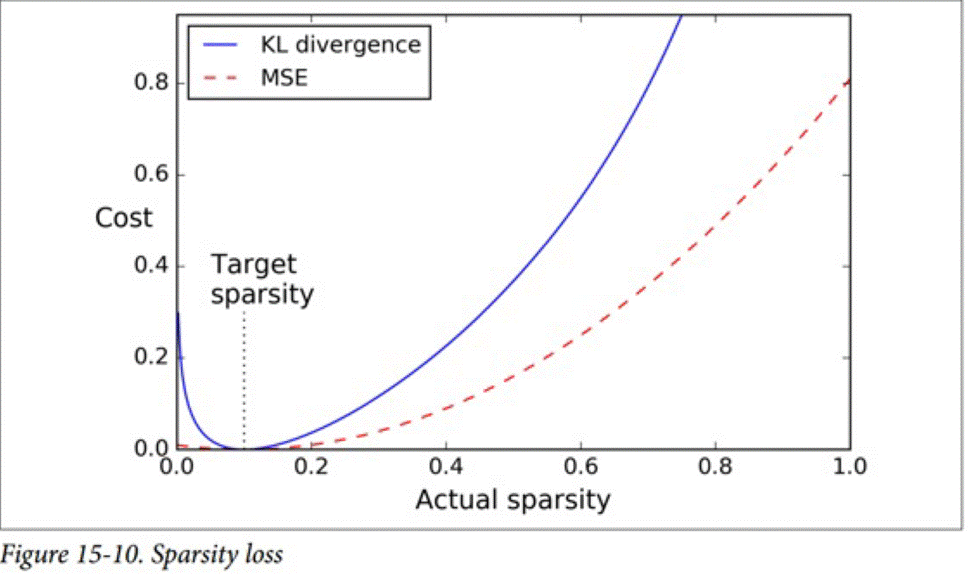
稀疏自编码器
稀疏自编码器的目的在于,使得最终的编码层的激活神经元尽量少,这样可以尽量去除神经元之间的相关效果,使最终的编码效果类似于热度变量的样子。
这样的结果是通过向损失函数中加r入额外的惩罚项来达到的。一种惩罚项是平方误差,一种是KL散度。


变分自编码器
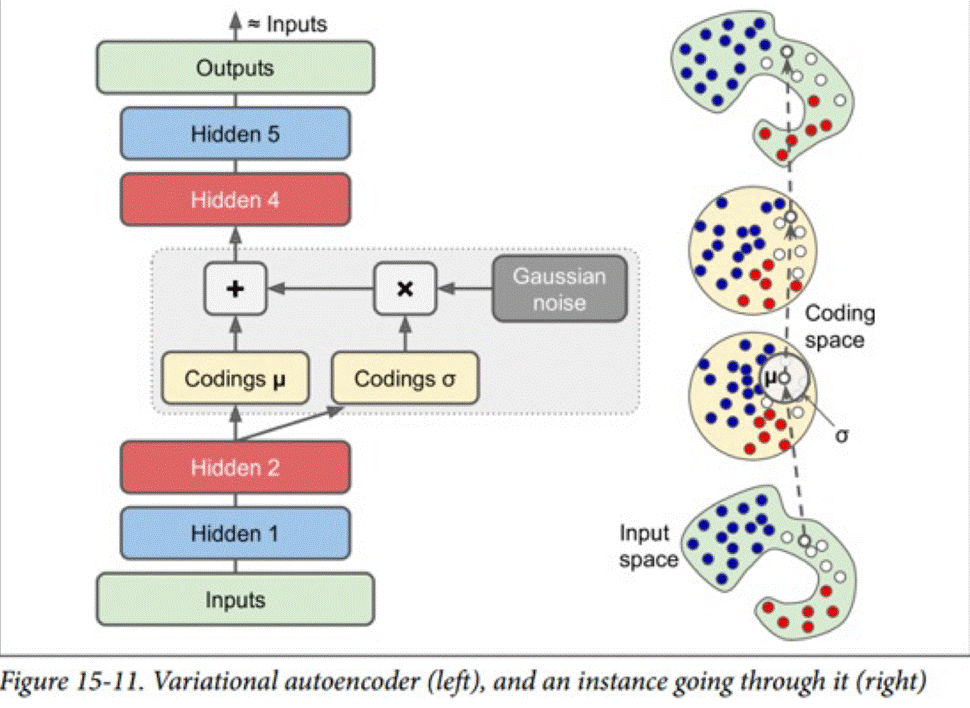
同样是通过将损失函数加入惩罚项,我们可以让编码层成为高斯分布(正态分布),这种编码器的优点在于,我们只需要在编码层提供高斯分布中的一个点,我们便能够解码生成一个类似的新实例。可以用来进行数据增强。
其他编码器


















 1591
1591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









