




 本文详细介绍了Linux CGroups(Control Groups)机制,包括其起源、主要功能和子系统,如CPU、内存限制等。通过配置内核启用CGroups,并展示了如何使用CPU子系统限制进程资源。文章还提出了一个控制系统设计思路,通过XML配置实现进程资源限制,以确保系统稳定性。
本文详细介绍了Linux CGroups(Control Groups)机制,包括其起源、主要功能和子系统,如CPU、内存限制等。通过配置内核启用CGroups,并展示了如何使用CPU子系统限制进程资源。文章还提出了一个控制系统设计思路,通过XML配置实现进程资源限制,以确保系统稳定性。
1 CGROUPS
1.1. CGROUPS介绍
Linux CGroups全称Linux Control Groups, 是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)。这个项目最早是由Google的工程师在2006年发起(主要是Paul Menage和Rohit Seth),最早的名称为进程容器(process containers)。在2007年时,因为在Linux内核中,容器(container)这个名词太过广泛,为避免混乱,被重命名为cgroup,并且被合并到2.6.24版的内核中去。然后,其它开始了他的发展。
Cgroups 是Linux内核支持的一个组件。可以为应用程序提供操作系统级的资源限制。
主要功能:
1.限制资源使用,比如内存使用上限以及文件系统的缓存限制。
2.优先级控制,CPU利用和磁盘IO吞吐。
3.一些审计或一些统计,主要目的是为了计费。
4.挂起进程,恢复执行进程。
1.2. 系统限制子系统
cgroup 子系统就是对系统任务限制的树状结构的控制系统,如下图,系统限制子系统。

cgroup目前包含的限制子系统有以下几个:
- cpu 子系统,主要限制进程的 cpu 使用率。
- cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
- memory 子系统,可以限制进程的 memory 使用量。
- blkio 子系统,可以限制进程的块设备 io。
- devices 子系统,可以控制进程能够访问某些设备。
- net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
- net_prio 子系统,这个子系统用来设计网络流量的优先级
- freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
- ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace
- hugetlb子系统, 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
- rdma 子系统,限制RDMA资源(Remote Direct Memory Access,远程直接数据存取)
子系统的树状结构特点就拿cpu子系统来举例,如下图cpu子系统结构:
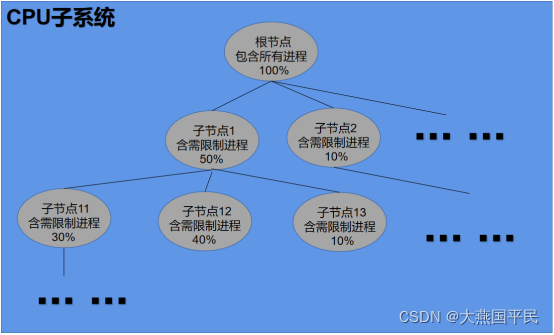
由上图我们清晰的看到cpu限制子系统的限制结构。按照这样的结构,只需要配置好对应的子系统的限制节点,将进程加入到对应的子节点就能将加入节点的所有进程都限制在对应的cpu限制。一个进程只能存在于一个节点,加入一个新的节点,进程就会从原来节点移除。其他子系统也是类似的配置和使用方式。
1.3. 检查CGROUP状态
我使用的是嵌入式系统(RV1126主控),一般流行的linux发行版本如ubuntu或者centos都是已经打开该功能的。cgroup自内核版本2.6.24就已经加入到内核中,默认可能是关闭的状态。我们先检查内核版本和当前系统是否已经开启了cgroup:

查看当前内核的版本为 4.19.111 是支持 cgroup的,查看运行/proc系统可以看到cgroup并没有运行。
这时候我们可以明确需要打开内核的cgroup支持即可。
1.4. 配置内核CGROUP
这里我以打开cpu子系统,进行cpu限制举例。
我们找到内核编译的deconfig 配置加入以下几个编译宏加入cgroup和cpu子系统模块到系统中:
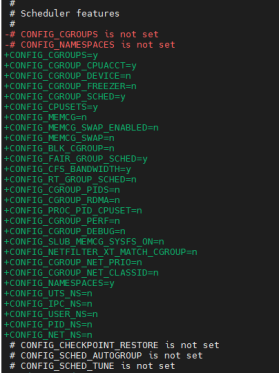
其中几个宏定义解释如下:
- CONFIG_CGROUPS:配置开启cgroup功能。
- CONFIG_CGROUP_CPUACCT:配置开启cpuacct子系统,开启cpu统计;
- CONFIG_CGROUP_SCHED:配置cgroup调度,让内核任务调度支持按照goup调度。
- CONFIG_CPUSETS:配置开启couset子系统,支持分配进程运行于哪个cpu核心。
- CONFIG_FAIR_GROUP_SCHED:开启cpuan按照任务组调度算法。
- CONFIG_CFS_BANDWIDTH:配置按照任务组调度算法支持百分比控制。
- CONFIG_NAMESPACES:用于每个namespcae的进程进行资源的隔离。
- 其他的根据宏定义的名字也能推测出来,不多做解释,只解释新增模块。
配置完毕后,我们编译内核烧录到板端,保证能够正常启动运行并进入系统。若不能进入系统出现kernel panic内核崩溃的话,要酌情关闭一些和系统冲突的模块。例如我在配置过程中发现 配置了 CONFIG_MEMCG=y 加入了内存管理子系统后,系统的NPU驱动就会崩溃。
成功配置后我们检查/proc 运行系统,可以查看到我们开启的所有子系统:

至此我们已经成功让系统支持了cgroup,接下来只要配置cgroup的使用即可。
1.5. 使用CGROUP的CPU子系统
使用cgroup的第一件事情是挂载cgroup文件系统,我们可以先检查是否已经自动挂载。

若没有挂载我们需要进行手动挂载,为了方便每次挂载,可以将以下脚本加入到inittab或者 rcS启动脚本中。
#!/bin/bash
cgroot="${1:-/sys/fs/cgroup}"
subsys="${2:-cpu cpuacct cpuset}" # 其他子系统在这里追加即可
mount -t tmpfs cgroup_root "${cgroot}"
for ss in $subsys; do
mkdir -p "$cgroot/$ss"
mount -t cgroup -o "$ss" "$ss" "$cgroot/$ss"
done
我们再次检查cgroup文件系统挂在情况,并进入cpu控制子系统:

我们可以看到子系统里面的很多文件参数,可以进行配置,部分参数的介绍如下:
| 参数名 | 说明 |
|---|---|
| cpu.cfs_period_us | 执行检测的周期,默认是100ms |
| cpu.cfs_quota_us | 在一个检测周期内,group节点内进程能使用cpu的最大时间,该值就是硬限,默认是-1,即不设置硬限 |
| cpu.shares | 顾名思义,shares=分享。它的工作原理非常类似于进程的nice值。shares就代表软限。 |
| cpu.state | group节点内进程的状态:一共运行了多少个周期;一共被throttle了多少次;一共被throttle了多少时间 |
| cpu.rt_period_us | 执行检测的周期,默认是1s |
| cpu.rt_runtime_us | 在一个检测周期内,能使用的cpu最大时间,只作用于rt任务 |
| cgroup.clone_children | 子节点创建时将继承父节点的配置 |
| cgroup.procs | 当前节点包含的进程列表 |
| tasks | 同cgroup.procs |
根节点的参数是无法更改的,我们需要先创建子节点。创建子节点的方式就是在根节点目录下新建一个文件夹,那么我们就会得到子节点,以及子节点的所有参数文件。

此时我们可以将想要限制的进程的pid 用echo的方式加入到task或cgroup.procs中,即可以对该进程按照当前节点的配置进行限制,以媒体应用mediad为例。

查看mediad当前进程的CPU使用情况。
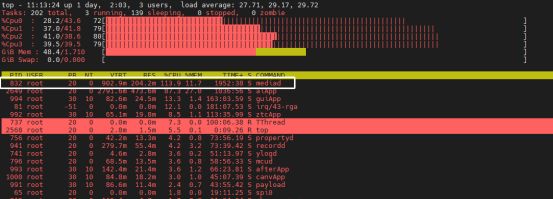
我们将mediad限制到单核的50%,我们只需要将 50%cpu.cfs_period_us结果echo到cpu.cfs_quota_us即可。

我们可以看到媒体应用的cpu占用马上即限制到50%,其他进程同理。
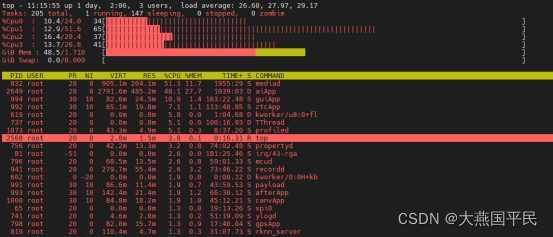
cpu.cfs_quota_us可用的最大值为 cpu核心数cpu.cfs_period_us 设置为 -1 即为不限制。子节点的cpu限制不能超过父节点,子节点使用的cpu资源是父节点提供的。
2. CGROUP控制系统设计
2.1. 控制系统目的
该控制系统为了用来限制目标进程的系统资源占用情况,达到指定的系统应用不会出现cpu超额占用影响到整个系统的稳定性。
2.2. 系统设计
系统启动完毕后,启动一个服务程序,挂载cgroup文件系统,然后读取XML配置,根据XML的配置,将对应的进程名的pid加入到cgroup管理中。达到限制的资源占用的目的。
XML也是树状结构和cgroup的子系统结构上非常的相似,因此可以使用XML来保存需要限制的进程,如图所示:
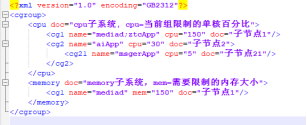
当前xml配置:
mediad和ztcApp一起分配150% cpu。
aiApp分配30% cpu。
msgerApp分配5% cpu。

















 1674
1674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









