



 本文介绍了全文检索的基本概念,包括索引的构建和搜索流程,并通过Lucene这一开源全文检索引擎工具包进行了实例演示。
本文介绍了全文检索的基本概念,包括索引的构建和搜索流程,并通过Lucene这一开源全文检索引擎工具包进行了实例演示。
什么是全文检索?全文检索(Full-text Search)是指先建立索引,再对索引进行搜索的过程称为全文检索。
那么什么是索引呢?
我们生活中的数据通常分为两种:结构化数据和非结构化数据。
结构化数据是指具有固定格式或者有限长度的数据,比如数据库;而非结构化数据是指指不定长或无固定格式的数据,像邮件,word文档等。我们对结构化数据比如数据库进行查询时,一般速度很快,但是像使用like查询采用顺序扫描法,一旦数据量大,效率也会变得很低下,非结构化数据更是如此。
所以将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定的结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对快速的目的。这部分从非结构化数据提取出来的信息,就称之为索引。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
全文检索可用于搜索引擎,站内搜索(比如淘宝京东关键字搜索商品),文件系统的搜索等。
Lucene是apache下的一个开源的全文检索引擎工具包(类库)。它的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。Lucene提供了完整的查询引擎和索引引擎,部分文本分析引擎。
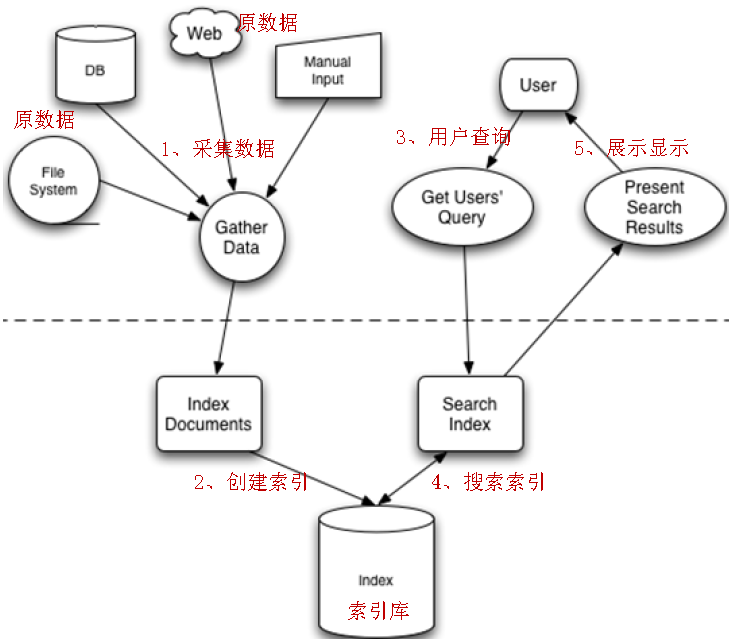
全文检索的流程分为两大部分:索引流程、搜索流程。
索引流程:即采集数据-->构建文档对象-->分析文档(分词)-->创建索引。
搜索流程:即用户通过搜索界面输入-->创建查询-->执行搜索,搜索器从索引库搜索-->渲染搜索结果。
Lucene创建索引的流程(dao层代码略)
public void testIndex() throws Exception {
// 1. 采集数据:(jdbc采集数据通过BookDao调用方法得到结果集)
BookDao dao = new BookDaoImpl();
List<Book> bookList = dao.queryBookList();
// 2. 遍历book结果集,组装Document数据列表
Document doc = null;
List<Document> docs = new ArrayList<>();
for (Book book : bookList) {
doc = new Document();
// 3. 构建Field域,说白了就是将要存储的数据字段需要用到new TextField对象三个参数的构造方法,
// book中有多个字段,所以创建多个Field对象。
// 参数一:域的名称,可随意起;参数二:域对应的值;参数三:是否存储
Field id = new TextField("id", book.getId().toString(), Store.YES);
Field name = new TextField("name", book.getName(), Store.YES);
Field price = new TextField("price", book.getPrice().toString(), Store.YES);
Field pic = new TextField("pic", book.getPic(), Store.YES);
Field description = new TextField("description", book.getDescription(), Store.YES);
// 4. 将Field域所有对象,添加到文档对象中。调用Document.add
doc.add(id);
doc.add(name);
doc.add(price);
doc.add(pic);
doc.add(description);
// 组装数据
docs.add(doc);
}
// 5. 创建一个标准分词器(Analyzer与StandardAnalyzer),对文档中的Field域进行分词
Analyzer analyzer = new StandardAnalyzer();
// 6. 指定索引储存目录,使用FSDirectory.open()方法。
FSDirectory directory = FSDirectory.open(new File("D:/Index"));
// 7. 创建IndexWriterConfig对象,直接new,用于接下来创建IndexWriter对象
// 参数一:版本号LATEST,使用当前jar包中,最新的;参数二:分词器
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
// 8. 创建IndexWriter对象,直接new
IndexWriter writer = new IndexWriter(directory, config);
// 9.添加文档对象到索引库输出对象中writer.addDocuments
writer.addDocuments(docs);
// 10. 释放资源IndexWriter.close();
writer.close();
}
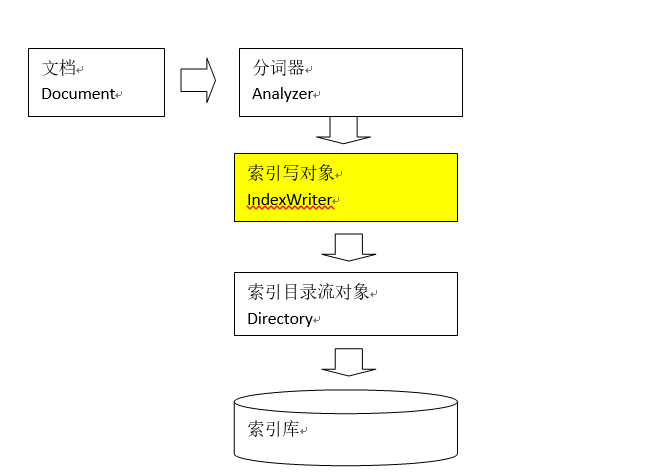
1. Document采集数据的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档(Document)中包括一个一个的域(Field)。
2. Analyzer分词器在对Document中的内容索引之前需要使用分词器(analyzer)进行分词,主要过程就是分词、过滤两步。
3. indexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
4. Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引),RAMDirectory(在内存存储索引)
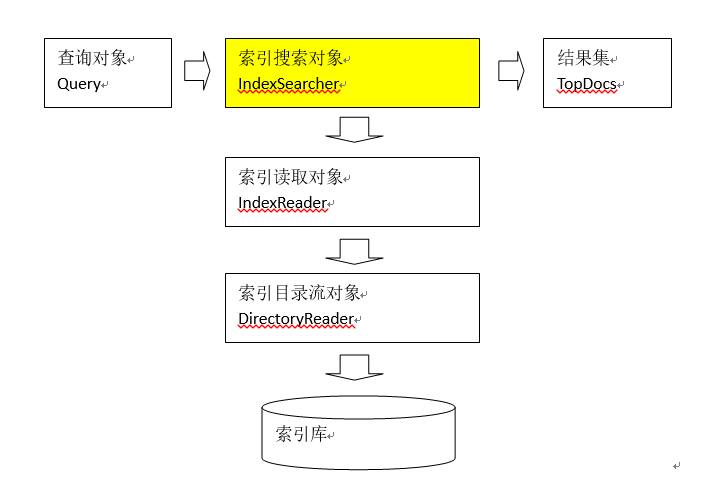
搜索流程
1 。 创建一个Directory对象,FSDirectory.open指定索引库存放的位置
2. 创建一个IndexReader对象,DirectoryReader.open需要指定Directory对象
3. 创建一个Indexsearcher对象,直接new,需要指定IndexReader对象
4. 创建一个TermQuery对象,直接new,指定查询的域和查询的关键词new Term(域名称,关键词)
5. 执行查询,IndexSearcher.search,需要指定TermQuery对象与查询排名靠多少名前的记录数,得到结果TopDocs
6. 遍历查询结果并输出,TopDocs.totalHits总记录数,topDocs.scoreDocs数据列表,通过scoreDoc.doc得到唯一id,再通过IndexSearcher.doc(id),得到文档对象Document再Document.get(域名称)得到结果
7. 关闭IndexReader对象
@Test
public void testQuery() throws Exception{
// 1. 创建一个Directory对象,FSDirectory.open指定索引库存放的位置
FSDirectory directory = FSDirectory.open(new File("D:/Index"));
// 2. 创建一个IndexReader对象,DirectoryReader.open需要指定Directory对象
IndexReader indexReader = DirectoryReader.open(directory);
// 3. 创建一个Indexsearcher对象,直接new,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 4. 创建一个TermQuery对象,直接new,指定查询的域和查询的关键词new Term(域名称,关键词)
TermQuery query = new TermQuery(new Term("name", "lucene"));
// 5.执行查询,IndexSearcher.search,需要指定TermQuery对象与查询排名靠多少名前的记录数,得到结果TopDocs
TopDocs docs = indexSearcher.search(query, 10);
// 6.遍历查询结果并输出,TopDocs.totalHits总记录数,topDocs.scoreDocs数据列表,
//通过scoreDoc.doc得到唯一id,再通过IndexSearcher.doc(id),得到文档对象Document,
//再Document.get(域名称)得到结果
System.out.println("查询总记录数为:" + docs.totalHits);
for (ScoreDoc scoreDoc : docs.scoreDocs) {
//得到文档id
int id = scoreDoc.doc;
//得到文档对象
Document doc = indexSearcher.doc(id);
System.out.println("id:" + doc.get("id"));
System.out.println("name:" + doc.get("name"));
System.out.println("price:" + doc.get("price"));
System.out.println("pic:" + doc.get("pic"));
//System.out.println("description:" + doc.get("description"));
}
// 7. 关闭IndexReader对象
indexReader.close();
}

















 5514
5514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









