




 本文介绍了如何使用Python的Scrapy框架爬取虎扑论坛的30支球队新闻。首先,讲解了Scrapy的安装和新建项目过程,接着在items.py中定义爬取目标,然后在spiders目录下创建爬虫,实现爬取和解析数据的功能。最后,通过Item Pipeline处理和存储爬取的内容。
本文介绍了如何使用Python的Scrapy框架爬取虎扑论坛的30支球队新闻。首先,讲解了Scrapy的安装和新建项目过程,接着在items.py中定义爬取目标,然后在spiders目录下创建爬虫,实现爬取和解析数据的功能。最后,通过Item Pipeline处理和存储爬取的内容。
目录
三、制作爬虫 (spiders/itcastSpider.py)
用python爬虫scrapy框架爬取虎扑论坛的30支球队新闻
Scrapy 框架
-
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
-
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
-
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Windows 安装方式
- Python 2 / 3
- 升级pip版本:
pip install --upgrade pip - 通过pip 安装 Scrapy 框架
pip install Scrapy
一. 新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject HupuSpider- 其中, HupuSpider为项目名称(自定义),可以看到 将会创建一个 HupuSpider文件夹,目录结构大致如下:
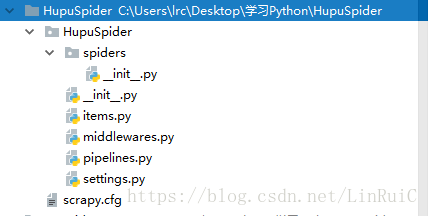
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
二、明确目标(mySpider/items.py)
我们打算抓取:https://voice.hupu.com/nba 网站里的30支球队新闻内容以及新闻配图。
打开mySpider目录下的items.py
Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item(可以理解成类似于ORM的映射关系)。
接下来,创建一个HupuSpiderItem类,和构建item模型(model)。
class HupuspiderItem(scrapy.Item): # 球队名称 teamname = scrapy.Field() # 球队url teamurl = scrapy.Field() # 新闻标题 newstitle=scrapy.Field() # 新闻链接 newsurl=scrapy.Field() # 新闻内容 content=scrapy.Field() # 新闻配图url imageurl=scrapy.Field()三、制作爬虫 (spiders/itcastSpider.py)
爬虫功能要分两步:
1. 爬数据
- 在当前目录下输入命令,将在
mySpider/spider目录下创建一个名为nba_news的爬虫,并指定爬取域的范围:scrapy genspider nba_news "hupu.com"
- 打开 mySpider/spider目录里的 nba_news
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 201
201




 到【灌水乐园】发言
到【灌水乐园】发言







