




 本文探讨了如何利用Python进行文件读写操作,包括字符和字节处理,以及如何进行JSON数据的序列化与反序列化。还介绍了时间模块的实用技巧,如日期时间处理和随机数生成。
本文探讨了如何利用Python进行文件读写操作,包括字符和字节处理,以及如何进行JSON数据的序列化与反序列化。还介绍了时间模块的实用技巧,如日期时间处理和随机数生成。
活动地址:优快云21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您:
想系统/深入学习某技术知识点…
一个人摸索学习很难坚持,想组团高效学习…
想写博客但无从下手,急需写作干货注入能量…
热爱写作,愿意让自己成为更好的人…
…
欢迎参与优快云学习挑战赛,成为更好的自己,请参考活动中各位优质专栏博主的免费高质量专栏资源(这部分优质资源是活动限时免费开放喔~),按照自身的学习领域和学习进度学习并记录自己的学习过程。您可以从以下3个方面任选其一着手(不强制),或者按照自己的理解发布专栏学习作品,参考如下:
**
学习计划
1,学习目标
提示:可以添加学习目标
例如: 一周掌握 Python 入门知识
2,学习内容
提示:可以添加要学的内容
例如:
A,掌握 Python 基本语法
B,掌握 Python 列表、字典、元组等集合类型的用法
C,掌握 Python 函数
D,掌握 Python 常用模块
E, 掌握 Python 模块与包
F,掌握 Python 类与对象
3,学习时间
每天拿出来两个小时
4,学习产出
优快云技术博客 每天一篇
学习日记
day04 Python的基础语法——文件操作
1.文件读操作
'''
s = "苑浩"
ret1 = s.encode("utf8") # 编码:将字符串转为字节数据.默认utf8
print(ret1)
s1 = b"hello world"
print(s1,type(s1)) # b'hello world' <class 'bytes'>
ret2 = ret1.decode("utf8")
print(ret2)
'''
# (1)打开文件: f = open(文件路径,mode="r")
f = open("自嘲诗.txt",mode="r")
# f = open("自嘲诗.txt",mode="rb") # 需要encoding参数
# (2)读所有数据: read()
# data = f.read()
# print(data)
# print(data.decode("GBK"))
# (3)读取几个字符
# data = f.read(2) # 本是
# print(data)
# (4)循环读文件
for line in f:
print(line,end="")
2.文件写操作
# ********************** 写字符 **********************
# f = open("自嘲诗2.txt","w",encoding="utf8") # 覆盖写
# f = open("自嘲诗2.txt", "a", encoding="utf8") # 追加写
# f.write("本是后山人!\n")
# f.writelines(["偶作钱塘可\n", "醉舞经阁半卷书\n", "坐井说天阔\n"])
# ********************** 写字节 **********************
# f = open("自嘲诗2.txt","wb") # 覆盖写
# f = open("a.txt", "ab",) # 追加写
# f.write("本是后山人!\n".encode())
# f.close()
3.文件拷贝
# f_read = open("自嘲诗2.txt", encoding="utf8")
# f_write = open("自嘲诗3.txt", mode="w", encoding="utf8")
#
# for line in f_read:
# # 方式1
# # new_line = line.replace("\n", "。\n")
# # print(new_line, end="")
#
# # 方式2
# # print(repr(line.strip()+"。\n"))
# new_line = line.strip() + "。\n"
# f_write.write(new_line)
# 爬取图片
f_read2 = open("meinv.jpg", mode="rb")
f_write2 = open("meinv2.jpg", mode="wb")
for line in f_read2:
f_write2.write(line)
4.JSON序列化
students_dict = {
"1001": {"name": "yuan", "scores": {"chinese": 90, "math": 80, "english": 100}},
"1002": {"name": "rain", "scores": {"chinese": 100, "math": 100, "english": 100}},
}
# 纯文本处理数据方式
# f = open("data.txt","w")
# data = str(students_dict)
# f.write(data)
# f.close()
# f = open("data.txt", "r")
# data = f.read()
#
# print(data["1001"]["name"])
################################# json序列化 #######################################
import json
# 序列化: 通过某种方式把数据结构或对象写入到磁盘文件中或通过网络传到其他节点的过程。
# data1 = (True, None, 123, 'yuan')
# ret1 = json.dumps(data1)
# print(ret1, type(ret1)) # [true, null, 123, "yuan"] <class 'str'>
# print(repr(ret1)) # '[true, null, 123, "yuan"]'
#
# data2 = {"name": 'yuan', "age": 22, "isMarried": False}
#
# ret2 = json.dumps(data2)
# print(repr(ret2)) # '{"name": "yuan", "age": 22, "isMarried": false}'
#
# f = open("data.json", "w")
# f.write(ret2)
# f.close()
# 反序列化:把磁盘中对象或者把网络节点中传输的数据恢复为python的数据对象的过程。
# f = open("data.json")
# data = f.read()
# print(data, type(data))
# 反序列化
data_dict = json.loads('{"name": "yuan", "age": 22, "isMarried": false}')
print(data_dict, type(data_dict))
print(data_dict.get("name"))
# 补充
data_str = '{"name":"yuan","is_married":false,"scores":[100,43,67]}'
js_data = json.loads(data_str)
print(js_data, type(js_data))
res = {"state": True, "err": None}
res_json = json.dumps(res)
print(repr(res_json))
5.时间模块
import time
# time.sleep(10)
'''
"2012-12-12 13:23:15"
"2012-12-12 22:22:20"
"1970-1-1 0:0:0" 0
"1970-1-1 0:0:1" 1
"1970-1-1 1:0:0" 3600
"1970-1-2 0:0:0" 3600*24
"1970-1-3 0:0:0" 3600*24*2
'''
# c1 = time.time() # 当前时间戳
# print(c1)
# print("hello world")
# time.sleep(3)
# c2 = time.time() # 当前时间戳
# print(c2)
# print(c2 - c1)
import datetime
'''
四类: date time datetime timedelta
'''
# 构建一个日期对象
dt = datetime.date(2012, 12, 12)
print(dt.year)
print(dt.month)
print(dt.day)
print(dt) # 2012-12-12
ret = dt.strftime("%Y/%m/%d")
print(ret) # 格式化字符串
# 构建当前日期对象
td = datetime.date.today()
print(td) # 2022-01-15
# datetime类
# 构建日期对象
dt = datetime.datetime(2012, 11, 10, 9, 8, 7)
print(dt.year)
print(dt.month)
print(dt.day)
print(dt.hour)
print(dt) # 2012-11-10 09:08:07
# ret1 = dt.strftime("%Y/%m/%d %H-%M-%S")
ret1 = dt.strftime("%Y/%m/%d %X")
print(ret1) # 2012/11/10 09:08:07
# 构建当前日期对象
now = datetime.datetime.now()
print(now)
# 关于日期比较
print(now > dt)
# timedelta
td = datetime.timedelta(days=3)
print(type(td))
print(now - td)
print((now+td).weekday()+1)
# 通过按着格式“1998年12月10日 星期五 13时45分”显示当前时刻三天后的时间
6.随机数模块
import random
print(random.random()) # 0-1随机浮点数
print(random.randint(1, 3)) # 范围整型
print(random.randint(0, 9)) #
print(random.randrange(1, 3)) # 范围整型
print(random.choice(["a", "b", "c"])) # 多个元素选一个
print(random.sample(["a", "b", "c"], 2)) # 多个元素选多个
l = [1, 2, 3, 4, 5, 6]
random.shuffle(l)
print(l)
# 构建5位验证码
print(ord("a"))
print(ord("b"))
print(ord("z"))
print(chr(97)) # a
print(chr(122)) # z
def get_random_str():
ret = []
for i in range(5):
random_num = str(random.randint(0, 9))
random_lower = chr(random.randint(97, 122))
random_upper = chr(random.randint(65, 90))
random_char = random.choice([random_num, random_upper, random_lower])
ret.append(random_char)
print(ret)
print("".join(ret))
return "".join(ret)
7.sys模块
import sys
# print(sys.platform)
# if sys.platform == "win32":
# pass
# sys.exit() # 强制程序退出
# sys.path : 导入包的路径列表
# sys.argv
# print("请登录")
# name = input("用户名:")
# pwd = input("密码:")
#
# if name == "yuan" and pwd == "123":
# print("登录成功")
# print("sys.argv:", sys.argv)
# user_index = sys.argv.index("-u") + 1
# user = sys.argv[user_index]
# pwd_index = sys.argv.index("-p") + 1
# pwd = sys.argv[pwd_index]
# if user == "yuan" and pwd == "123":
# print("登录成功")
print(chr)
8.os模块
import os
# print(os.getcwd()) # E:\s32\day04
# os.chdir("E:\s32\day03")
# print(os.getcwd())
# print(os.listdir())
# print(os.path.abspath(os.pardir))
# os.makedirs("wk01/代码",exist_ok=True)
# os.remove("a.txt")
# os.rename("meinv.jpg", "meinv3.jpg")
# data = os.stat("data.txt")
# print(data)
# print(data.st_size)
# print(os.sep)
print(__file__)
print(os.path.abspath(__file__))
print(os.path.abspath("data.json"))
a = os.path.abspath(__file__)
ret = os.path.split(a)
print(ret) # ('E:\\s32\\day04', '09 os模块.py')
print(os.path.basename(a))
print(os.path.dirname(os.path.dirname(a)))
a = os.path.abspath(__file__)
path = os.path.join(os.path.dirname(a),"new","data.txt")
print("path:",path)
with open(path) as f:
print(f.read())
print(os.path.getsize(path))
使用vscode作为python编码的ide中遇到的几个问题:
1.运行代码的时候总是默认打开Windows系统自带的cmd或者powershell窗口,而不是下面vscode自带的运行窗口
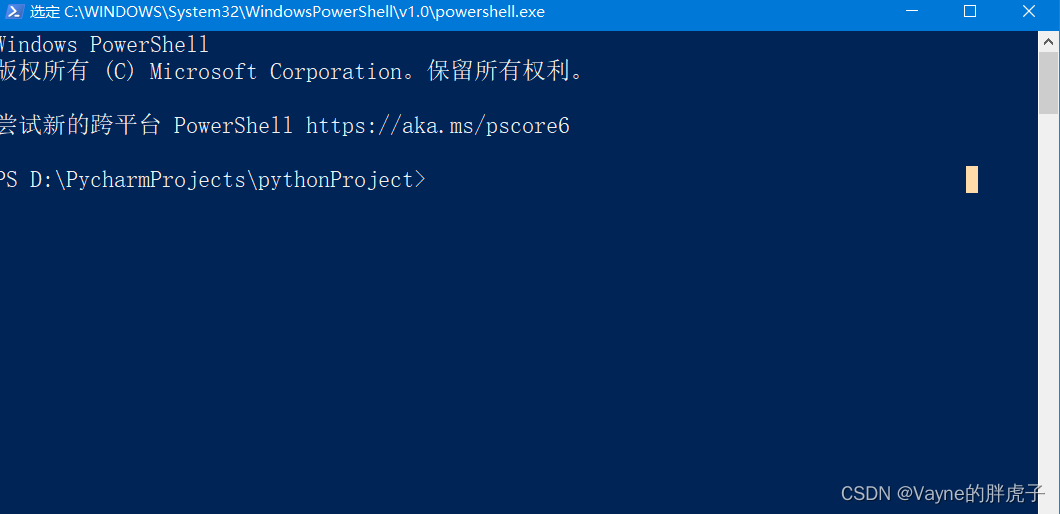
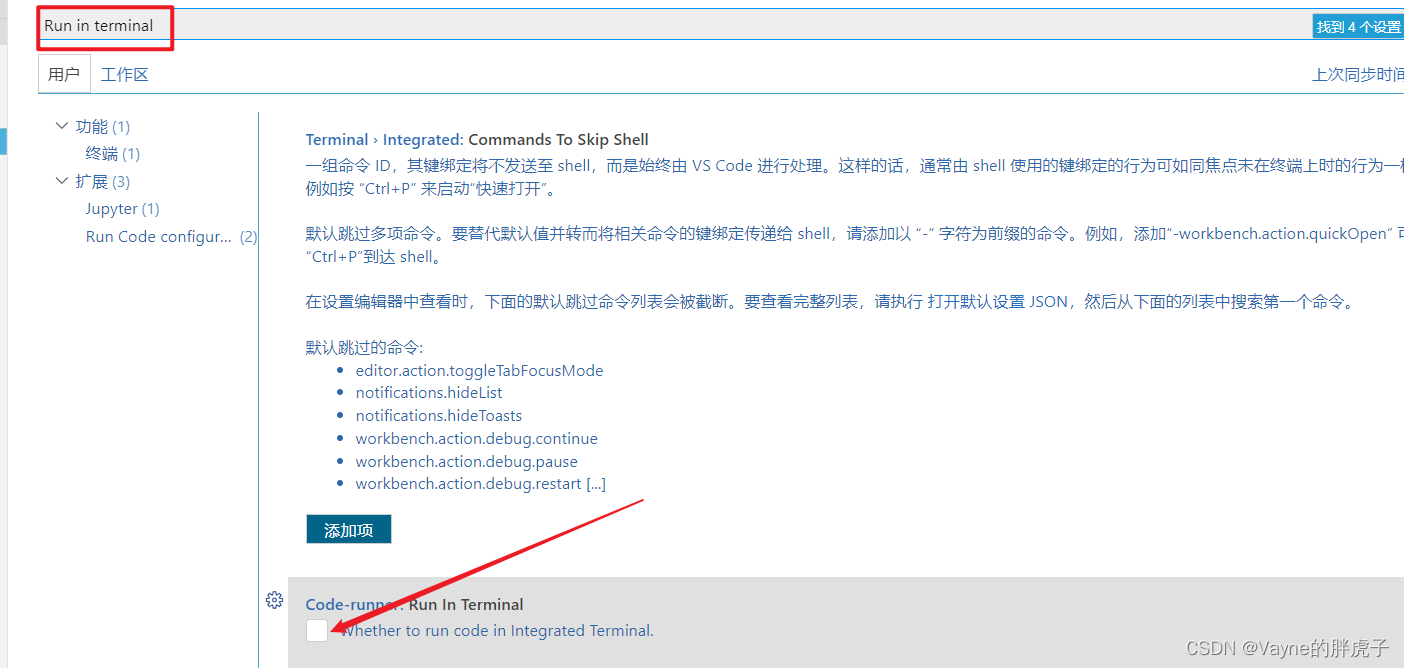
解决方法:
1.打开左下角的设置图标;
2.输入Run In Terminal,取消勾选第一个选项;
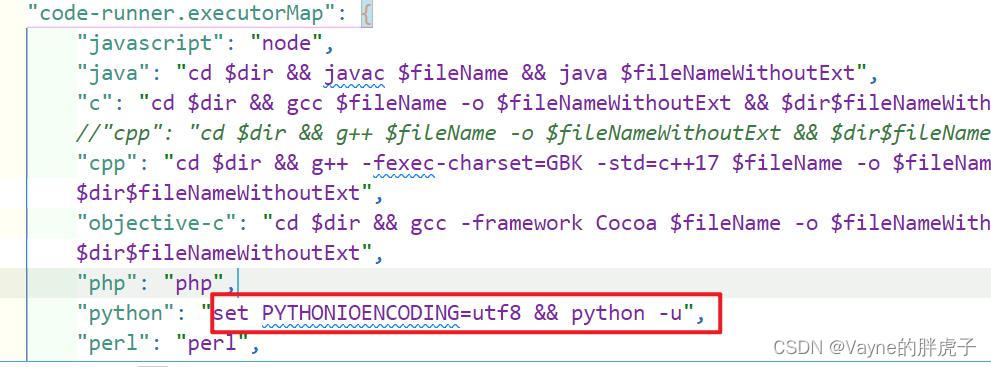
2.控制台输出中文乱码:

解决方法:
1. ctrl + shift + P 打开settings.json
2. 在python运行命令加入编码参数:


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









