






 谷歌提出的Federated Learning是一种在保持数据分散的情况下进行深度网络训练的方法。FedAvg算法是其核心,通过加权平均不同用户的本地模型更新来聚合全局模型。研究发现,使用相同初始化并平均聚合模型能取得最佳效果。该算法允许在不集中数据的情况下进行模型优化,保护了用户数据的隐私。
谷歌提出的Federated Learning是一种在保持数据分散的情况下进行深度网络训练的方法。FedAvg算法是其核心,通过加权平均不同用户的本地模型更新来聚合全局模型。研究发现,使用相同初始化并平均聚合模型能取得最佳效果。该算法允许在不集中数据的情况下进行模型优化,保护了用户数据的隐私。
【论文阅读】Communication-Efficient Learning of Deep Networks from Decentralized Data
谷歌第一次提出Federated Learning的概念,同时提出FedAvg聚合算法。
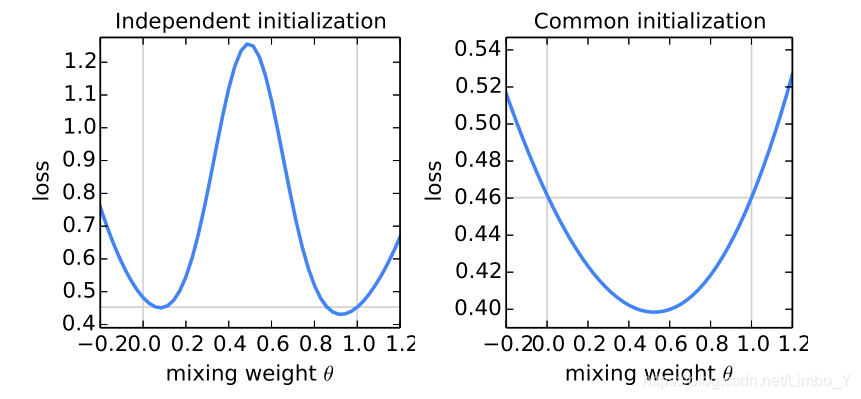
探索聚合方式:考虑两个模型www和w′w'w′,使用SGD优化,根据公式θw+(1−θ)w′\theta w+(1-\theta) w^{\prime}θw+(1−θ)w′加权平均计算www和w′w'w′的平均模型,θ∈[−0.2,1.2]\theta \in [-0.2, 1.2]θ∈[−0.2,1.2]。左图两个模型使用不同的随机种子初始化,右图使用相同的随机种子初始化。竖线与曲线的交点分别表示两个模型www和w′w'w′的loss(对应θ=0\theta = 0θ=0和θ=1\theta =1θ=1),横线表示了www或w′w'w′更优的loss。
结论:使用相同初始化,且加权平均聚合的效果最好(0.5w+0.5w′0.5 w+0.5 w^{\prime}0.5w+0.5w′)。
核心算法 FedAvg:

算法解释:
Input 输入:
KKK个用户设备,用kkk作为索引;BBB表示用户设备本地批量大小;EEE表示用户设备本地迭代轮次;η\etaη表示本地学习率;CCC表示每次选取的用户比率
Server executes 服务器端:
初始化模型参数w0w_{0}w0
在t=1,2,...t=1, 2, ...t=1,2,...循环:
从总共KKK个用户设备中,按照比率CCC选取m=max(C∗K,1)m = max(C*K, 1)m=max(C∗K,1)个设备
StS_{t}St为mmm个用户设备的合集
对每个用户设备k∈Stk \in S_{t}k∈St并行操作:
wt+1k=ClientUpdate(k,wt)w_{t+1}^{k} = ClientUpdate(k, w_{t})wt+1k=ClientUpdate(k,wt)
加权平均聚合KKK个用户设备的模型,wt+1←∑k=1Knknwt+1kw_{t+1} \leftarrow \sum_{k=1}^{K} \frac{n_{k}}{n} w_{t+1}^{k}wt+1←∑k=1Knnkwt+1k
ClientUpdate 用户设备本地:
把用户的数据Pk\mathcal{P}_{k}Pk按照本地批量大小BBB划分为B\mathcal{B}B
迭代训练EEE轮:
对于每个小批量b∈Bb \in \mathcal{B}b∈B
w←w−η∇ℓ(w;b)w \leftarrow w-\eta \nabla \ell(w ; b)w←w−η∇ℓ(w;b)
返回www给服务器

















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









