




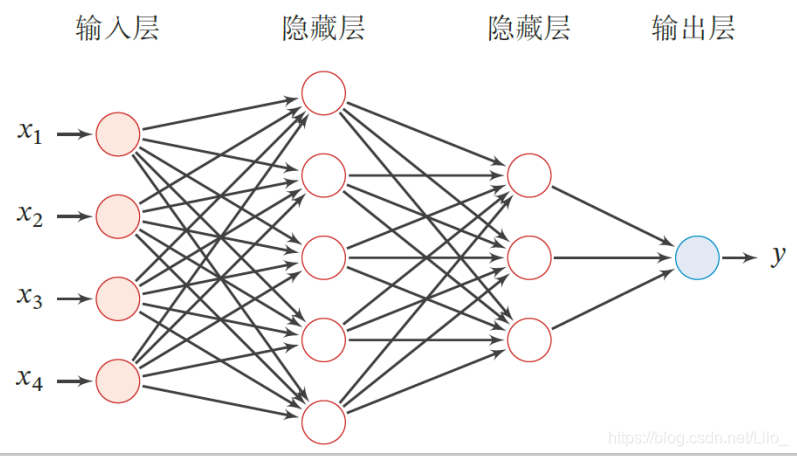
前馈神经网络(Feedforward Neural Network, FNN)
◼ 第0层为输入层,最后一层为输出层,其他中间层称为隐藏层
◼ 信号从输入层向输出层单向传播,整个网络中无反馈,可用一个有向无环图表示
一、线性回归 Linear Regression
(一)《动手学深度学习》实例
线性回归的从零实现[源码]
# 线性回归的从零实现
import torch
import torch.nn as nn
import numpy as np
import random
from matplotlib import pyplot as plt
from IPython import display
# 生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2,-3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0,0.01,size=labels.size()),dtype = torch.float32)
# 读取数据
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples)) # 创建一个整数列表
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batch
yield features.index_select(0, j), labels.index_select(0, j)
# 初始化模型参数
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
# 定义模型
def linearreg(X,w,b):
return torch.mm(X,w)+b # 矩阵乘法
# 定义损失函数 - 平方损失
def squared_loss(y_hat,y):
return (y_hat - y.view(y_hat.size()))**2/2 # 注意这里返回的是向量, 且pytorch里的MSELoss并没有除以 2
# 定义优化算法 - 小批量随机梯度下降算法
def SGD(params,lr,batch_size):
for param in params:
param.data -= lr*param.grad/batch_size # 注意这里更改param时用的param.data
# 训练模型
batch_size = 10
num_epochs = 50
lr = 0.003
net = linearreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X,w,b),y).sum()
l.backward()
SGD([w,b],lr,batch_size)
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch+1,train_l.mean().item()))
# 输出结果
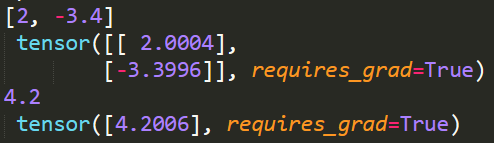
print(true_w, '\n', w)
print(true_b, '\n', b)
线性回归的从零实现[补充]
1. yield的使用
(yield相当于return一个值,并且记住这个返回的位置,下次迭代从这个位置后开始继续向下执行。)
参考:yield使用详解【非常容易理解!】
线性回归的简洁实现[源码]
# 线性回归的简洁实现
import torch
import torch.nn as nn
import numpy as np
import random
from matplotlib import pyplot as plt
from IPython import display
# 生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2,-3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0,0.01,size=labels.size()),dtype = torch.float32)
# 读取数据
import torch.utils.data as Data
batch_size = 10
dataset = Data.TensorDataset(features,labels) # 将训练数据的特征和标签组合
data_iter = Data.DataLoader(dataset,batch_size,shuffle=True) # 随机读取小批量
# 定义模型(用class搭建模型)
class LinearNet(nn.Module):
def __init__(self,n_feature):
super(LinearNet,self).__init__()
self.linear = nn.Linear(n_feature,1)
def forward(self,x):
y = self.linear(x)
return y
net = LinearNet(num_inputs)
# 初始化模型参数
from torch.nn import init
init.normal_(net.linear.weight, mean=0, std=0.01)
init.constant_(net.linear.bias,val=0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









