




1、第一个C++程序
同c语言一样,c++的第一个程序也是打印”hello world“,但写法就有所差异:
#include <iostream>
using namespace std;
int main()
{
cout<<"hello world"<<endl;
return 0;
}
#include <stdio.h>
int main()
{
printf("hello world/n");
return 0;
}
1.1 cout、cin、endl
cout是标准输出流对象
cout是用于打印的工具,<<表示的是流向左,我们打印的内容是hello world。
cout<<hello world表示的意思就是,将我们想打印的内容流向cout,借助这个工具,将内容输出,显示于屏幕上。
endl
紧接于后面的是<<endl,从上面我们已经清楚<<表示的就是一个流向,endl同c语言中的\n一样,具有换行作用,以及还有刷新缓存区,那就需要将换行的这个空间打印出来。
cin是标准输入流对象
与cout相近的则是cin,即担任输入的工具(通过键盘输入),因为输入的内容需要存到一个空间中,所以先建一个变量(int) num
int num;
cin>>num
我们发现>>是指向num,因为我们从键盘上输入的值是要存入这个空间的,所以指向num
那如果将cin、cout、endl结合使用呢?
int main()
{
int num;
cin>>num;//借助cin输入内容,存于num中
cout<<num<<endl;//将num中的内容,借助cout打印出来
return 0;
}
通过观察,可以发现,c++在打印的时候不需要写打印类型%d,输入的时候也无需&num。
可得出C++的输入输出可以自动识别变量类型
而c++在输入或打印多个变量的时候,同样可以用简洁的方式表示:
int main()
{
int n1,n2,n3;
cin>>n1>>n2>>n3;//可以在键盘上挨着输入三个值,存放于对于变量中
cout<<n1<<n2<<n3<<endl;//依次输出
return 0;
}
1.2 头文件引用和名字空间
通过上述的比较,发现:
除了:
int main()
{
return 0;
}
这一基本模板完全相同,其他地方都有着很大的差别。
如#include<stdio.h>和< iostream >
stdio: 标准的输入输出。.h:头文件
iostream(i-input;o-output;stream;流):: 输入输出流。
printf的使用需要引入头文件,而cin和cout以及endl也需要头文件。
iostream就是C++中的一个头文件,之所以必须使用头文件,这就好比于我要使用一个工具,那我就得有一个工具箱,而这工具箱中包含的不只一件工具。
而上述代码中还存在一个比c多出的一串代码:
using namespace std;
翻译过来就是使用名字空间std
名字空间有何作用?引入一个例子
一个年级有三个名字一样的人,年级主任要喊其中一个人时,就很容易出现问题:到底喊的是谁?这时候就出现了名字冲突问题。但假如我们指定了那个班级的xx,这时候就很容易区别谁是谁了。
同理在C++中,变量、函数、类都是大量存在,如果他们都同时存在于全局作用域中,那么名字会发生冲突,为了避免这种情况,引入关键字namespace,将cin、cout、endl划分于一个名为std的C++标准库的名字空间中,这就等同于上面的划分班级一样。除了C++自己的名字空间,用户自身也可以定义一个名字空间。
从上述代码中也可以发现,这就意味着后续我们可以任意使用std中的任意定义,这是一种粗暴的方式,但往往我们只使用部分,如下:
#include<iostream>
using namespace std;
int main()
{
std::cout<<"hello world"<<std::endl;
return 0;
}
这样就指明了哪个工具属于哪个班级了。
2、数据类型
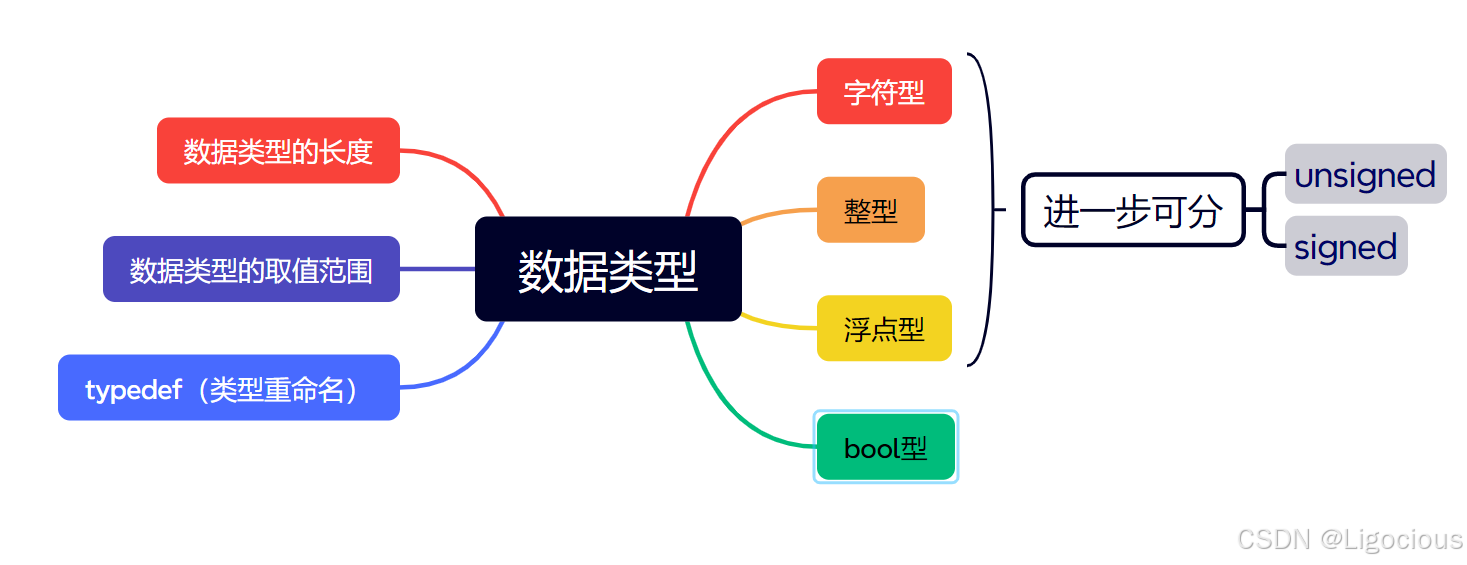
2.1 各种类型
字符型:char
即通通过键盘输入的字符:如a,b,c或则# ¥ *等都是字符,值得注意的是它们都需要用单引号括起来:‘a’,'b’等表示,然后存储到变量中。
如果是若干个字符组成起来,就构成了字符串,但字符串是没有类型的,它们需要用双引号括起来,它的存储就涉及到数组了。
char ch='a';//字符
char str[]="abc";//字符串
事实上,字符无法在内存中直接存储的,我们知道电脑采用的是二进制存储,因此每一个字符都有自己对应的整数表示,我们将这种整数称之为ASCLL码值
这就意味着,对于一个字符型数据,我们既可以通过它的符号打印出它的ASCLL码值,也可以通过它的符号打印出它对应的符号。
char ch='a';
cout<<(int)ch;
int num=65;
cout<<(char)65;
char类型长度:
什么是长度:每一种数据类型都有自己对应的长度,使用不同数据类型创建的变量长度都不同,这会导致存储数据的范围不同。
长度的计算:sizeof是一个关键字也是一个操作符,可以通关它来计算长度,它的返回值是size_t ,即无符号整型,很好理解,长度不可能为负,单位为字节。
char a;//变量创建
sizeof(char);
sizeof char;
sizeof(a);//表达式写法
长度的单位: 1byte(字节)=8个bit(比特)
char的长度: 1byte
char的取值范围:-128~127
(一个比特位可以存储一个二进制位)
char还可以分为unsigned char(非负)和signed char(有正负),长度都为1byte。
取值范围分别为0 ~ 255 和 -128 ~ 127。
为什么无符号和有符号是这样取范围的?
上面有提及一个比特位可以存储二进制位,对于无符号型,所有的bit位都可以存储二进制,而对于有符号型,它还有一个比特位,不是存储二进制位的,而是表示符号位,符号位决定正负,因此可以看见无符号型的最大值等于有符号整型最小值绝对值+最大值,由此可以计算其他数据类型
整型
short:短整型,长度为2byte
int :整型,长度4byte
long:长整型,长度:sizeof(long)>=sizeof(int) 8/4>=4。
long long :更长整型,长度为8
进一步还可以分为无符号型和有符号型,对于它们的长度和取值范围可以自己计算。
浮点型
单精度浮点型:float(长度为4字节)
双精度浮点型:double,long double(长度分别为8字节,16字节)
还可以进一步分为:无符号和有符号型。
bool型
这种类型的变量是专门表示对与错,即false和true。
bool a=false;
bool b=true;
if(a)
cout<<"hello world"<<endl;//可执行
if(b)
cout<<"hellow word"<<endl;//不可执行
事实上,在c和c++中,还有其他的方式表示真和假,比如0表示假,非0表示真。
int a = 0;
cin>>a;
if(a)
cout<<"hello world"<<endl;
2.2 typedef类型重命名
作用:如果遇到复杂的数据类型的时候,如:unsigned long double,对于这种类型我们可以通过typedef给它重新命名为更简单的方式如:
typedef unsigned long double uld;
//语法结构:typedef 原来的类型名 新的类型名
3、变量和常量
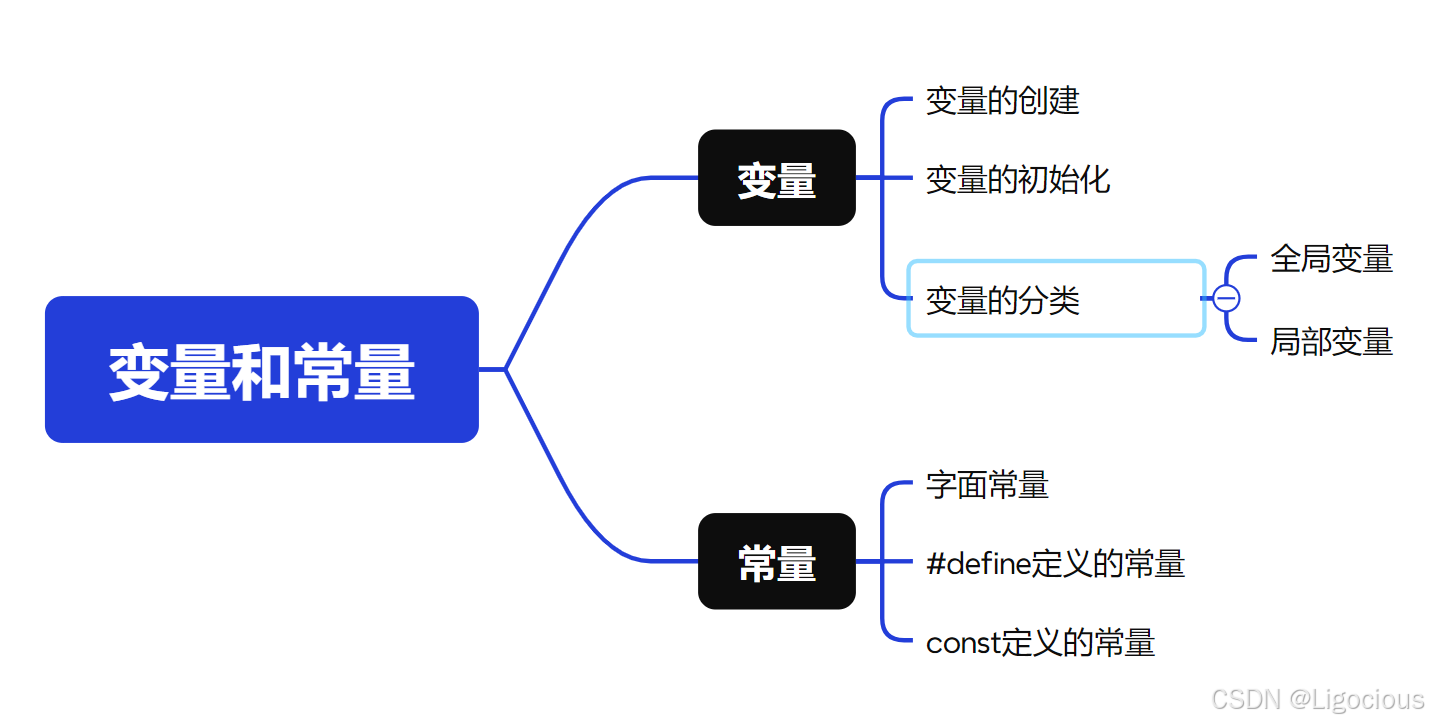
变量就是要变的量,常量就是不变的量。
3.1 变量的创建
前面已经了解了基本的数据类型,那么数据类型到底用来做什么呢?
即,用于变量的创建。
//语法结构:
//数据类型名 自定义的变量名;
//eg:
int num;
char ch;
变量的创建本质上是向内存中申请一个空间,数据类型决定这个空间存放什么样类型的数据。
当然变量的命名也不是随便的,也是有要求的,如下:
1、变量名只能由数字、字母、下划线组成。
2、变量名开头不能是数字,可以是下划线和字母。
3、变量名不能和关键字相一致,如if,int ,typedef啥的。
4、变量名最好是有意义,这便于代码的理解,如num表示数字。
5、变量名最好是用小写表示,而常量采用大写,这有利于区分二者。
3.2 变量的初始化
初始化即是在变量的创建的时候就给变量一个值如下:
int num = 0;
不同于赋值,赋值是创建以后,在进行赋值
int num;
num = 0;
3.3 变量的分类
我们创建的变量都是有自己的使用范围,范围之外使用的时候,编译器就会报错。
而变量作用的范围可以分为:
全局变量:大括号外定义的变量,在整个工程中,也是有办法使用的。
局部变量:大括号内定义的变量。
int a=5;
int b;
int main()
{
int a=10;
{
int b = 20;
cout<<a//可以打印,因为a是可以在整个main函数中使用。
}
cout<<b;//无法打印,b只在包含它的大括号中才可以使用
return 0;
}
提出疑问:打印a的时候,是打印的5还是10?
事实上,当局部变量和全局变量同时使用的时候,并且名字相同,这时候,局部优先,因此结果是10。
那如果想要显示的是全局变量的初始的值呢?
cout<<::a<<endl;//在a的前面加上 :: 就可以显示全局变量初始的值了。
如果一个变量在创建的时候,没有初始化或没有赋值,就直接打印,编译器要么报错,要么就生成一个随机值,但对于全局变量而言,它是不需要初始化的,即创建的时候,如果没有自定义初始化一个值,它就会默认初始化为0。局部变量就没有此操作。
3.4 常量
1、#define定义的常量。
——语法结构:
#define 常量名 常量值
#define MAX 100
#define MIN 0;
注意:
- 常量值可以任何类型的。
- 常量名最好采用大写,有区分于变量名
- 在使用的时候,本质上就是替换,如用MAX 代替100以后,在使用MAX打印的时候,编译器会重新替换成常量的值。
2、const定义的常量
——语法结构
const 数据类型 常量名=常量值;
const double PAI = 3.14;
对于const定义的常量也可以理解为const修饰的变量,常变量。
通过语法结构,可见它的定义于变量创建的语法结构一致,只是多加了一个const。
相比于#define定义的常量,它的可读性更高。
常量在实际运用中的好处在于,如果代码中都需要使用一个常量(我们将所有的常量值都用一个常量名替代),在后期维护测试或想要修改的时候,就不用挨着去改,只用在常量定义的代码中,将常量值修改即可。
4、算术操作符
4.1 算术操作符
在代码中会涉及到有关计算方面,这就涉及到有关算术的操作符,以下是一组用于计算的操作符:

它们都是双目操作符,所谓双目操作符就是有两个操作数,如下:
int a = 1;
int b = 2;
int c =a+b;
c=a-b;
c=a*b;
c=a/b;
c=a%b;
//计算c的值时,a和b就是两个操作数,将他们计算的值赋值给c
//不同于数学中的计算,我们习惯于a+b=c,而不是c=a+b;
//代码中的=表示赋值,数学表示=表示等于,如果相准确的表示等于,应该是==。
+:两个操作数之和。
-:两数之差,左边减去右边
*和/:分别是乘号和除号
%:取模,即取两数相除的余数,如7%2=3……1,取 1.
注意:
1、被除数不能为0;
2、取模的两个操作数都为整数,同时负数也是可以进行取模操作,运算逻辑是一样的,主要看的是第一个操作数,如果第一个操作数为负号,,那结果一定为负;为正,那就为正。
4.2浮点数的除法
#include<iostream>
using namesoace std;
int main()
{
int a = 7/2;
cout<<a<<endl;
float b=7/2;
cout<<b<<endl;
//结果是多少?
return 0;
}
事实上两个变量最终显示的值都为3,它们进行的都是整型的计算。
如何实现浮点型计算?
只要其中的任意一个操作数用浮点型表示,那么b中计算的结果就为3.5,而a本身就是整型,还是为3.
除了除法浮点数的计算采用此方式,在乘法中也是可以的。
float a =1.0*7/2;
//结果也是3.5
数值溢出的问题
我们都知道每一种数据类型都有自己取值范围,而在算术操作符计算中难免会出现数值溢出的问题,我们以char类型来说明:
char的取值范围是:-128~127。
char a ='Z'//ASCLL:90
char b=a+'Z'//90+90=180
cout<<(int)b<<endl;
最终的结果是-76,这是为什么呢?
事实上对于char类型数据,当它加到127以后在加1,它就会变成-128,
而对于-128在减去1就会变成127,这就意味着最大值和最小值是相连的,形成一个环形,使得数据无论怎样变化都在这个范围内。
至于为什么,这就涉及c语言的数据的存储的相关知识了。
5、赋值操作符
在变量创建时,给变量一个值,此时的操作叫做初始化,如果变量创建以后没有初始化,而在后续给变量一个值,此时就叫做赋值。
int a =1;//初始化
int b;
b=0;//赋值
=:表示赋值操作符,而在数学中表示的是等号,在c++中==才表示等号。
5.1连续赋值
int a =1;
int b =2;
int c =3;
c = b = a+3;//连续赋值是从左往右
//将a+3的值赋值给b,b原来的值发生改变,再将b的新值赋给c。
cout<<a<<b<<c<<endl;
1 4 4
连续赋值的代码不好理解,建议拆解来写。
b=a+3;
c=b;
//这样代码就更加明了
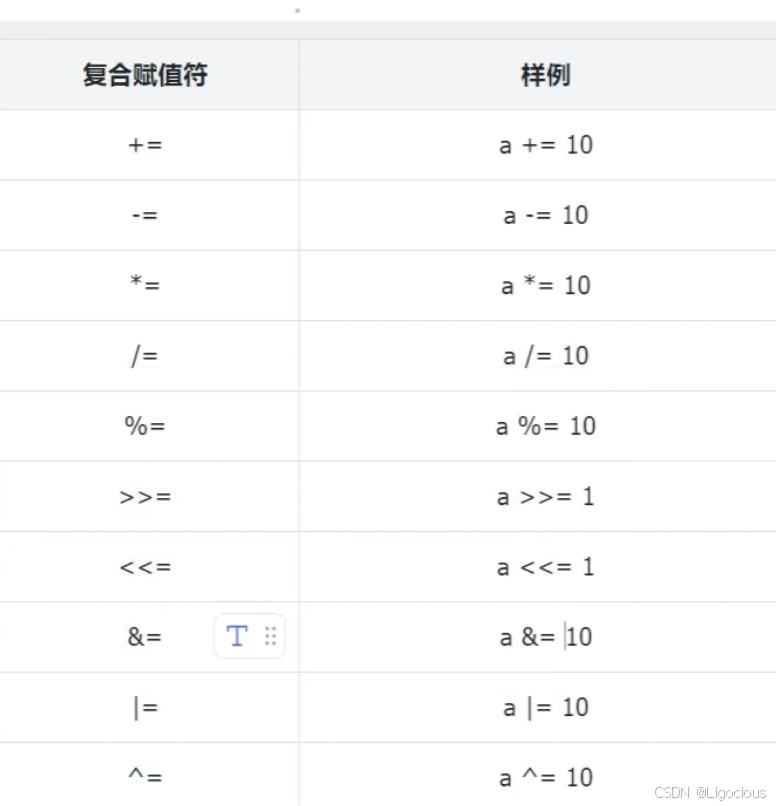
5.2复合赋值
int a=0;
a=a+1;
//计算方式是将a原来的值+1,赋值给a,使得a得到一个新的值,除了加号,还有其他符号
a=a-1;
a=a*2;
除了上述方式,还有其他方式表达:
a+=1;//a=a+1
a-=1;//a=a-1
上述就是的操作符就是复合赋值符,还有其他的:
6.类型转换
在使用C/C++写代码的过程中,不同类型的数据进行混合计算的时候,或者赋值时等号两边的类型不统一的时候,都会发生类型转换,这时就需要根据类型的转换规则转换成合适的类型。
6.1不同类型数据的混合计算和赋值等号两边类型不统一
char a='a';
int b=10;
char c =a+b;
char型的a与int型的b相加的时候,a就会整型提升,转换为对于的ASCLL码值与整型的b相加,由于相加之和是放在一个字符型c中,这些整数会转换成ASCLL码值对应的字符。
整型提升: 当char、short、int类型的数据混合计算的时候,char和short的类型都要转换成整型,提升的意思就是扩大变量原来的空间。
有提升就有截断,上述代码中将int类型的数据存到char类型时,就发生了截断,这是由于char相比于int是较小类型,大类型转换为小类型就会发生截断,保留低位数据给较小的类型
算术转换: 当多个不同类型的数据进行算术操作的时候,需要进行类型转换,转换成统一类型才能进行计算。
对于多个不同类型数据混合计算时,到底统一成哪一种类型,这里有一个先后顺序:

优先级是从上到下的,这就意味着当7和5混合计算的时候,7要转换成5类型。
6.2强制类型转化:
//(类型名)表达式
int a =90;
char s=(char)a;
cout<<(char)a<<endl;
强制类型转换,就是将一种数据类型强制转换成另外一种我们目标类型,但只是暂时的,对实际变量的值构不成影响。
7.单目操作符
这里只讲++和–以及+和-
7.1 ++和- -
++和–分别表示自增和自减,自增和自减的值都是1,如:
int a=0;
a++;//1
int b=0;
b--;//1
上述的操作符都是写在变量的前面,陈为后置++、- -。
还有前置++、- -
如:
int a=0;
++a;//1
int b=0;
--b;//1
前置和后置有什么区别吗?有的。
int a=1;
int b=5;
a=b++;
cout<<a<<b<<endl;
//结果:5 6
a=++b;
cout<<a<<b<<endl;
//结果:6 6
解释:
在a=b++中,是后置++,这就使得先将b值赋给a,b本身在进行+1;
在a=++b中,是前置++,这就是使得b先进行+1,在将新的值赋给a,最终a为6.
同理- -也是如此。
7.2 +和-
表示数的正负的,如+5,+可以省略表示正的5,-5中的负号,表示这个数是个负数,不可以省略。除了表示在具体的数据上,还可以用在一个变量前面:
int a =5;
int b=-a;

















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









