







file是一个类,使用file(‘file_name’, ‘r+’)这种方式打开文件,返回一个file对象,以写模式打开文件不存在则会被创建。但是更推荐使用内置函数open()来打开一个文件 .
首先open是内置函数,使用方式是open(‘file_name’, mode, buffering),返回值也是一个file对象,同样,以写模式打开文件如果不存在也会被创建一个新的。
f=open(‘/tmp/hello’,‘w’)
#open(路径+文件名,读写模式)
#读写模式:r只读,r+读写,w新建(会覆盖原有文件),a追加,b二进制文件.常用模式
如:‘rb’,‘wb’,'r+b’等等
读写模式的类型有:
rU 或 Ua 以读方式打开, 同时提供通用换行符支持 (PEP 278)
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
注意:
1、使用’W’,文件若存在,首先要清空,然后(重新)创建,
2、使用’a’模式 ,把所有要写入文件的数据都追加到文件的末尾,即使你使用了seek()指向文件的其他地方,如果文件不存在,将自动被创建。
f.read([size]) size未指定则返回整个文件,如果文件大小>2倍内存则有问题.f.read()读到文件尾时返回""(空字串)
file.readline() 返回一行
file.readline([size]) 返回包含size行的列表,size 未指定则返回全部行
for line in f:
print line #通过迭代器访问
f.write(“hello\n”) #如果要写入字符串以外的数据,先将他转换为字符串.
f.tell() 返回一个整数,表示当前文件指针的位置(就是到文件头的比特数).
f.seek(偏移量,[起始位置])
用来移动文件指针
偏移量:单位:比特,可正可负
起始位置:0-文件头,默认值;1-当前位置;2-文件尾
f.close() 关闭文件
要进行读文件操作,只需要把模式换成’r’就可以,也可以把模式为空不写参数,也是读的意思,因为程序默认是为’r’的。
>>>f = open(‘a.txt’, ‘r’)
>>>f.read(5)
‘hello’
read( )是读文件的方法,括号内填入要读取的字符数,这里填写的字符数是5,如果填写的是1那么输出的就应该是‘h’。
打开文件文件读取还有一些常用到的技巧方法,像下边这两种:
1、read( ):表示读取全部内容
2、readline( ):表示逐行读取
一、用python写一个列举当前目录以及所有子目录下的文件,并打印出绝对路径
#!/usr/bin/env python
import os
for root,dirs,files in os.walk(‘/tmp’):
for name in files:
print (**os.path.join**(root,name))
os.walk()
原型为:os.walk(top, topdown=True, οnerrοr=None, followlinks=False)
我们一般只使用第一个参数。(topdown指明遍历的顺序)
该方法对于每个目录返回一个三元组,(dirpath, dirnames, filenames)。
第一个是路径,第二个是路径下面的目录,第三个是路径下面的非目录(对于windows来说也就是文件)
os.listdir(path)
其参数含义如下。path 要获得内容目录的路径
二、写程序打印三角形
#!/usr/bin/env python
input = int(raw_input(‘input number:’))
for i in range(input):
for j in range(i):
print '\*',
print '\\n'
三、猜数器,程序随机生成一个个位数字,然后等待用户输入,输入数字和生成数字相同则视为成功。成功则打印三角形。失败则重新输入(提示:随机数函数:random)
#!/usr/bin/env python
import random
while True:
input = int(raw\_input('input number:'))
random\_num = **random.randint**(1, 10)
print input,random\_num
if input == random\_num:
for i in **range**(input):
for j in range(i):
print '\*',
print '\\n'
else:
print 'please input number again'
四、请按照这样的日期格式(xxxx-xx-xx)每日生成一个文件,例如今天生成的文件为2013-09-23.log, 并且把磁盘的使用情况写到到这个文件中。
#!/usr/bin/env python
#!coding=utf-8
import time
import os
new_time = time.strftime(‘%Y-%m-%d’)
disk_status = os.popen(‘df -h’).readlines()
str1 = ‘’.join(disk_status)
f = file(new_time+‘.log’,‘w’)
f.write(‘%s’ % str1)
f.flush()
f.close()
五、统计出每个IP的访问量有多少?(从日志文件中查找)
#!/usr/bin/env python
#!coding=utf-8
list = []
f = file(‘/tmp/1.log’)
str1 = f.readlines()
f.close()
for i in str1:
ip = **i.split()\[0\]**
**list.append(ip)**
list_num = set(list)
for j in list_num:
num = list.count(j)
print '%s : %s' %(j,num)
1. 写个程序,接受用户输入数字,并进行校验,非数字给出错误提示,然后重新等待用户输入。
2. 根据用户输入数字,输出从0到该数字之间所有的素数。(只能被1和自身整除的数为素数)
#!/usr/bin/env python
#coding=utf-8
import tab
import sys
while True:
try:
n = int(raw\_input('请输入数字:').strip())
for i in range(2, n + 1):
for x in range(2, i):
if i % x == 0:
break
else:
print i
except ValueError:
print('你输入的不是数字,请重新输入:')
except KeyboardInterrupt:
sys.exit('\\n')
python练习 抓取web页面
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f=open(webpage)
lines=f.readlines()
f.close
print firstNonBlank(lines), #调用函数
lines.reverse()
print firstNonBlank(lines),
def download(url= ‘http://search.51job.com/jobsearch/advance_search.php’,process=firstLast):
try:
retval = urlretrieve(url) \[0\]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == ‘__main__’:
download()
Python中的sys.argv[]用法练习
#!/usr/bin/python
# -*- coding:utf-8 -*-
import sys
def readFile(filename):
f = file(filename)
while True:
fileContext = f.readline()
if len(fileContext) ==0:
break;
print fileContext
f.close()
if len(sys.argv) < 2:
print "No function be setted."
sys.exit()
if sys.argv[1].startswith(“-”):
**option = sys.argv\[1\]\[1:\]**
if option == 'version':
print "Version1.2"
elif option == 'help':
print "enter an filename to see the context of it!"
else:
print "Unknown function!"
sys.exit()
else:
for **filename in sys.argv\[1:\]:**
readFile(filename)
python迭代查找目录下文件
#两种方法
#!/usr/bin/env python
import os
dir=‘/root/sh’
‘’’
def fr(dir):
filelist=os.listdir(dir)
for i in filelist:
fullfile=**os.path.join**(dir,i)
if not **os.path.isdir**(fullfile):
if i == "1.txt":
#print fullfile
**os.remove**(fullfile)
else:
fr(fullfile)
‘’’
‘’’
def fw()dir:
for root,dirs,files in os.walk(dir):
for f in files:
if f == "1.txt":
#os.remove(os.path.join(root,f))
print os.path.join(root,f)
‘’’
一、ps 可以查看进程的内存占用大小,写一个脚本计算一下所有进程所占用内存大小的和。
(提示,使用ps aux 列出所有进程,过滤出RSS那列,然后求和)
#!/usr/bin/env python
#!coding=utf-8
import os
list = []
sum = 0
str1 = os.popen(‘ps aux’,‘r’).readlines()
for i in str1:
str2 = i.split()
new\_rss = str2\[5\]
list.append(new\_rss)
for i in list[1:-1]:
num = int(i)
**sum = sum + num**
print ‘%s:%s’ %(list[0],sum)
写一个脚本,判断本机的80端口是否开启着,如果开启着什么都不做,如果发现端口不存在,那么重启一下httpd服务,并发邮件通知你自己。脚本写好后,可以每一分钟执行一次,也可以写一个死循环的脚本,30s检测一次。
#!/usr/bin/env python
#!coding=utf-8
import os
import time
import sys
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
def sendsimplemail (warning):
msg = **MIMEText**(warning)
msg\['Subject'\] = 'python first mail'
msg\['From'\] = 'root@localhost'
try:
smtp = smtplib.SMTP()
smtp.connect(r'smtp.126.com')
smtp.login('要发送的邮箱名', '密码')
smtp.sendmail('要发送的邮箱名', \['要发送的邮箱名'\], msg.as\_string())
smtp.close()
except Exception, e:
print e
while True:
http\_status = os.popen('netstat -tulnp | grep httpd','r').readlines()
try:
if http\_status == \[\]:
os.system('service httpd start')
new\_http\_status = os.popen('netstat -tulnp | grep httpd','r').readlines()
str1 = ''.join(new\_http\_status)
is\_80 = str1.split()\[3\].split(':')\[-1\]
if is\_80 != '80':
print 'httpd 启动失败'
else:
print 'httpd 启动成功'
sendsimplemail(warning = "This is a warning!!!")#调用函数
else:
print 'httpd正常'
**time.sleep(5)**
except KeyboardInterrupt:
sys.exit('\\n')
#!/usr/bin/python
#-*- coding:utf-8 -*-
#输入这一条就可以在Python脚本里面使用汉语注释!此脚本可以直接复制使用;
while True: #进入死循环
input = raw\_input('Please input your username:')
#交互式输入用户信息,输入input信息;
if input == "wenlong":
#如果input等于wenlong则进入此循环(如果用户输入wenlong)
password = raw\_input('Please input your pass:')
#交互式信息输入,输入password信息;
p = '123'
#设置变量P赋值为123
while password != p:
#如果输入的password 不等于p(123), 则进此入循环
password = raw\_input('Please input your pass again:')
#交互式信息输入,输入password信息;
if password == p:
#如果password等于p(123),则进入此循环
print 'welcome to select system!' #输出提示信息;
while True:
#进入循环;
match = 0
#设置变量match等于0;
input = raw\_input("Please input the name whom you want to search :")
#交互式信息输入,输入input信息;
while not input.strip():
#判断input值是否为空,如果input输出为空,则进入循环;
input = raw\_input("Please input the name whom you want to search :")
#交互式信息输入,输入input信息;
name\_file = file('search\_name.txt')
#设置变量name_file,file(‘search_name.txt’)是调用名为search_name.txt的文档
while True:
#进入循环;
line = name\_file.readline() #以行的形式,读取search\_name.txt文档信息;
if len(line) == 0: #当len(name\_file.readline() )为0时,表示读完了文件,len(name\_file.readline() )为每一行的字符长度,空行的内容为\\n也是有两个字符。len为0时进入循环;
break #执行到这里跳出循环;
if input in line: #如果输入的input信息可以匹配到文件的某一行,进入循环;
print 'Match item: %s' %line #输出匹配到的行信息;
match = 1 #给变量match赋值为1
if match == 0 : #如果match等于0,则进入 ;
print 'No match item found!' #输出提示信息;
else: print "Sorry ,user %s not found " %input #如果输入的用户不是wenlong,则输出信息没有这个用户;
#!/usr/bin/python
while True:
input = raw\_input('Please input your username:')
if input == "wenlong":
password = raw\_input('Please input your pass:')
p = '123'
while password != p:
password = raw\_input('Please input your pass again:')
if password == p:
print 'welcome to select system!'
while True:
match = 0
input = raw\_input("Please input the name whom you want to search :")
while not input.strip():
print 'No match item found!'
input = raw\_input("Please input the name whom you want to search :")
name\_file = file('search\_name.txt')
while True:
line = name\_file.readline()
if len(line) == 0:
break
if input in line:
print 'Match item: ' , line
match = 1
if match == 0 :
print 'No match item found!'
else: print "Sorry ,user %s not found " %input
Python监控CPU情况
1、实现原理:通过SNMP协议获取系统信息,再进行相应的计算和格式化,最后输出结果
2、特别注意:被监控的机器上需要支持snmp。yum install -y net-snmp*安装
“”"
#!/usr/bin/python
import os
def getAllitems(host, oid):
sn1 = os.popen('snmpwalk -v 2c -c public ' + host + ' ' + oid + '|grep Raw|grep Cpu|grep -v Kernel').read().split('\\n')\[:-1\]
return sn1
def getDate(host):
items = getAllitems(host, '.1.3.6.1.4.1.2021.11')
date = \[\]
rate = \[\]
cpu\_total = 0
#us = us+ni, sy = sy + irq + sirq
for item in items:
float\_item = float(item.split(' ')\[3\])
cpu\_total += float\_item
if item == items\[0\]:
date.append(float(item.split(' ')\[3\]) + float(items\[1\].split(' ')\[3\]))
elif item == item\[2\]:
date.append(float(item.split(' ')\[3\] + items\[5\].split(' ')\[3\] + items\[6\].split(' ')\[3\]))
else:
date.append(float\_item)
#calculate cpu usage percentage
for item in date:
rate.append((item/cpu\_total)\*100)
mean = \['%us','%ni','%sy','%id','%wa','%cpu\_irq','%cpu\_sIRQ'\]
#calculate cpu usage percentage
result = map(None,rate,mean)
return result
if __name__ == ‘__main__’:
hosts = \['192.168.10.1','192.168.10.2'\]
for host in hosts:
print '==========' + host + '=========='
result = getDate(host)
print 'Cpu(s)',
#print result
for i in range(5):
print ' %.2f%s' % (result\[i\]\[0\],result\[i\]\[1\]),
print
print
Python监控系统负载
1、实现原理:通过SNMP协议获取系统信息,再进行相应的计算和格式化,最后输出结果
2、特别注意:被监控的机器上需要支持snmp。yum install -y net-snmp*安装
“”"
#!/usr/bin/python
import os
def getAllitems(host, oid):
sn1 = os.popen('snmpwalk -v 2c -c public ' + host + ' ' + oid).read().split('\\n')
return sn1
def getload(host,loid):
load\_oids = '1.3.6.1.4.1.2021.10.1.3.' + str(loid)
return getAllitems(host,load\_oids)\[0\].split(':')\[3\]
if __name__ == ‘__main__’:
hosts = \['192.168.10.1','192.168.10.2'\]
#check\_system\_load
print '==============System Load=============='
for host in hosts:
load1 = getload(host, 1)
load10 = getload(host, 2)
load15 = getload(host, 3)
print '%s load(1min): %s ,load(10min): %s ,load(15min): %s' % (host,load1,load10,load15)
Python监控网卡流量
1、实现原理:通过SNMP协议获取系统信息,再进行相应的计算和格式化,最后输出结果
2、特别注意:被监控的机器上需要支持snmp。yum install -y net-snmp*安装
“”"
#!/usr/bin/python
import re
import os
#get SNMP-MIB2 of the devices
def getAllitems(host,oid):
sn1 = os.popen('snmpwalk -v 2c -c public ' + host + ' ' + oid).read().split('\\n')\[:-1\]
return sn1
#get network device
def getDevices(host):
device\_mib = getAllitems(host,'RFC1213-MIB::ifDescr')
device\_list = \[\]
for item in device\_mib:
if re.search('eth',item):
device\_list.append(item.split(':')\[3\].strip())
return device\_list
#get network date
def getDate(host,oid):
date\_mib = getAllitems(host,oid)\[1:\]
date = \[\]
for item in date\_mib:
byte = float(item.split(':')\[3\].strip())
date.append(str(round(byte/1024,2)) + ' KB')
return date
if __name__ == ‘__main__’:
hosts = \['192.168.10.1','192.168.10.2'\]
for host in hosts:
device\_list = getDevices(host)
inside = getDate(host,'IF-MIB::ifInOctets')
outside = getDate(host,'IF-MIB::ifOutOctets')
print '==========' + host + '=========='
for i in range(len(inside)):
print '%s : RX: %-15s TX: %s ' % (device\_list\[i\], inside\[i\], outside\[i\])
print
Python监控磁盘
1、实现原理:通过SNMP协议获取系统信息,再进行相应的计算和格式化,最后输出结果
2、特别注意:被监控的机器上需要支持snmp。yum install -y net-snmp*安装
“”"
#!/usr/bin/python
import re
import os
def getAllitems(host,oid):
sn1 = os.popen('snmpwalk -v 2c -c public ' + host + ' ' + oid).read().split('\\n')\[:-1\]
return sn1
def getDate(source,newitem):
for item in source\[5:\]:
newitem.append(item.split(':')\[3\].strip())
return newitem
def getRealDate(item1,item2,listname):
for i in range(len(item1)):
listname.append(int(item1\[i\])\*int(item2\[i\])/1024)
return listname
def caculateDiskUsedRate(host):
hrStorageDescr = getAllitems(host, 'HOST-RESOURCES-MIB::hrStorageDescr')
hrStorageUsed = getAllitems(host, 'HOST-RESOURCES-MIB::hrStorageUsed')
hrStorageSize = getAllitems(host, 'HOST-RESOURCES-MIB::hrStorageSize')
hrStorageAllocationUnits = getAllitems(host, 'HOST-RESOURCES-MIB::hrStorageAllocationUnits')
disk\_list = \[\]
hrsused = \[\]
hrsize = \[\]
hrsaunits = \[\]
#get disk\_list
for item in hrStorageDescr:
if re.search('/',item):
disk\_list.append(item.split(':')\[3\])
#print disk\_list
getDate(hrStorageUsed,hrsused)
getDate(hrStorageSize,hrsize)
#print getDate(hrStorageAllocationUnits,hrsaunits)
#get hrstorageAllocationUnits
for item in hrStorageAllocationUnits\[5:\]:
hrsaunits.append(item.split(':')\[3\].strip().split(' ')\[0\])
#caculate the result
#disk\_used = hrStorageUsed \* hrStorageAllocationUnits /1024 (KB)
disk\_used = \[\]
total\_size = \[\]
disk\_used = getRealDate(hrsused,hrsaunits,disk\_used)
total\_size = getRealDate(hrsize,hrsaunits,total\_size)
diskused\_rate = \[\]
for i in range(len(disk\_used)):
diskused\_rate.append(str(round((float(disk\_used\[i\])/float(total\_size\[i\])\*100), 2)) + '%')
return diskused\_rate,disk\_list
if __name__ == ‘__main__’:
hosts = \['192.168.10.1','192.168.10.2'\]
for host in hosts:
result = caculateDiskUsedRate(host)
diskused\_rate = result\[0\]
partition = result\[1\]
print "==========",host,'=========='
for i in range(len(diskused\_rate)):
print '%-20s used: %s' % (partition\[i\],diskused\_rate\[i\])
print
Python监控内存(swap)的使用率
1、实现原理:通过SNMP协议获取系统信息,再进行相应的计算和格式化,最后输出结果
2、特别注意:被监控的机器上需要支持snmp。yum install -y net-snmp*安装
‘’’
#!/usr/bin/python
import os
def getAllitems(host, oid):
sn1 = os.popen('snmpwalk -v 2c -c public ' + host + ' ' + oid).read().split('\\n')\[:-1\]
return sn1
def getSwapTotal(host):
swap\_total = getAllitems(host, 'UCD-SNMP-MIB::memTotalSwap.0')\[0\].split(' ')\[3\]
return swap\_total
def getSwapUsed(host):
swap\_avail = getAllitems(host, 'UCD-SNMP-MIB::memAvailSwap.0')\[0\].split(' ')\[3\]
swap\_total = getSwapTotal(host)
swap\_used = str(round(((float(swap\_total)-float(swap\_avail))/float(swap\_total))\*100 ,2)) + '%'
return swap\_used
def getMemTotal(host):
mem\_total = getAllitems(host, 'UCD-SNMP-MIB::memTotalReal.0')\[0\].split(' ')\[3\]
return mem\_total
def getMemUsed(host):
mem\_total = getMemTotal(host)
mem\_avail = getAllitems(host, 'UCD-SNMP-MIB::memAvailReal.0')\[0\].split(' ')\[3\]
mem\_used = str(round(((float(mem\_total)-float(mem\_avail))/float(mem\_total))\*100 ,2)) + '%'
return mem\_used
if __name__ == ‘__main__’:
hosts = \['192.168.10.1','192.168.10.2'\]
print "Monitoring Memory Usage"
for host in hosts:
mem\_used = getMemUsed(host)
swap\_used = getSwapUsed(host)
print '==========' + host + '=========='
print 'Mem\_Used = %-15s Swap\_Used = %-15s' % (mem\_used, swap\_used)
print
Python运维脚本 生成随机密码
#!/usr/bin/env python
# -*- coding=utf-8 -*-
#Using GPL v2.7
#Author: leexide@126.com
import random, string #导入random和string模块
def GenPassword(length):
#随机出数字的个数
numOfNum = **random.randint**(1,length-1)
numOfLetter = length - numOfNum
#选中numOfNum个数字
slcNum = \[**random.choice**(string.digits) **for i in range**(numOfNum)\]
#选中numOfLetter个字母
slcLetter = \[random.choice(string.ascii\_letters) for i in range(numOfLetter)\]
#打乱组合
slcChar = slcNum + slcLetter
**random.shuffle**(slcChar)
#生成随机密码
getPwd = ''.join(\[i for i in slcChar\])
return getPwd
if __name__ == ‘__main__’:
print GenPassword(6)
利用random生成6位数字加字母随机验证码
import random
li = []
for i in range(6):
r = **random.randrange**(0, 5)
if r == 2 or r == 4:
num = random.randrange(0, 9)
li.append(str(num))
else:
temp = random.randrange(65, 91)
c = chr(temp)
li.append(c)
result = “”.join(li) # 使用join时元素必须是字符串
print(result)
输出
335HQS
VS6RN5
…
random.random()用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成随机数
n: a <= n <= b。如果 a <b, 则 b <= n <= a。
print random.uniform(10, 20)
print random.uniform(20, 10)
#----
#18.7356606526
#12.5798298022
random.randint 用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,Python生成随机数
print random.randint(12, 20) #生成的随机数n: 12 <= n <= 20
print random.randint(20, 20) #结果永远是20
#print random.randint(20, 10) #该语句是错误的。
下限必须小于上限。
random.randrange 从指定范围内,按指定基数递增的集合中
random.randrange的函数原型为:random.randrange([start], stop[, step]),从指定范围内,按指定基数递增的集合中 获取一个随机数。
如:
random.randrange(10, 100, 2),结果相当于从[10, 12, 14, 16, … 96, 98]序列中获取一个随机数。
random.randrange(10, 100, 2)在结果上与 random.choice(range(10, 100, 2) 等效。
随机整数:
>>> import random
>>> random.randint(0,99)
21
随机选取0到100间的偶数:
>>> import random
>>> random.randrange(0, 101, 2)
42
随机浮点数:
>>> import random
>>> random.random()
0.85415370477785668
>>> random.uniform(1, 10)
5.4221167969800881
随机字符:
random.choice从序列中获取一个随机元素。
其函数原型为:random.choice(sequence)。参数sequence表示一个有序类型。
这里要说明 一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。
list, tuple, 字符串都属于sequence。
print random.choice(“学习Python”)
print random.choice([“JGood”, “is”, “a”, “handsome”, “boy”])
print random.choice((“Tuple”, “List”, “Dict”))
>>> import random
>>> random.choice(‘abcdefg&#%^*f’)
‘d’
多个字符中选取特定数量的字符:
random.sample的函数原型为:random.sample(sequence, k),从指定序列中随机获取指定长度的片断。
sample函数不会修改原有序列。
>>> import random
random.sample(‘abcdefghij’,3)
[‘a’, ‘d’, ‘b’]
多个字符中选取特定数量的字符组成新字符串:
>>> import random
>>> import string
>>> string.join(random.sample([‘a’,‘b’,‘c’,‘d’,‘e’,‘f’,‘g’,‘h’,‘i’,‘j’], 3)).r
eplace(" “,”")
‘fih’
随机选取字符串:
>>> import random
>>> random.choice ( [‘apple’, ‘pear’, ‘peach’, ‘orange’, ‘lemon’] )
‘lemon’
洗牌:
random.shuffle的函数原型为:random.shuffle(x[, random]),用于将一个列表中的元素打乱 .
>>> import random
>>> items = [1, 2, 3, 4, 5, 6]
>>> random.shuffle(items)
>>> items
[3, 2, 5, 6, 4, 1]
1、random.random
random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
2、random.uniform
random.uniform(a, b),用于生成一个指定范围内的随机符点数,
两个参数其中一个是上限,一个是下限。
如果a < b,则生成的随机数n: b>= n >= a。
如果 a >b,则生成的随机数n: a>= n >= b。
print random.uniform(10, 20)
print random.uniform(20, 10)
# 14.73
# 18.579
3、random.randint
random.randint(a, b),用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b
print random.randint(1, 10)
4、random.randrange
random.randrange([start], stop[, step]),从指定范围内,按指定基数递增的集合中 获取一个随机数。
如:random.randrange(10, 100, 2),结果相当于从[10, 12, 14, 16, … 96, 98]序列中获取一个随机数。
5、random.choice
random.choice从序列中获取一个随机元素。其函数原型为:random.choice(sequence)。参数sequence表示一个有序类型。
这里要说明 一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。list, tuple, 字符串都属于sequence。
print random.choice(“Python”)
print random.choice([“JGood”, “is”, “a”, “handsome”, “boy”])
print random.choice((“Tuple”, “List”, “Dict”))
6、random.shuffle
random.shuffle(x[, random]),用于将一个列表中的元素打乱。
如:
p = [“Python”, “is”, “powerful”, “simple”, “and so on…”]
random.shuffle§
print p
# [‘powerful’, ‘simple’, ‘is’, ‘Python’, ‘and so on…’]
7、random.sample
random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列。
例如:
list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10,11,12]
slice = random.sample(list, 6) # 从list中随机获取6个元素,作为一个片断返回
print slice
print list # 原有序列并没有改变
1.生成随机整数:
random.randint(a,b)
random.randint(a,b) #返回一个随机整数,范围是a <=x <= b
>>> random.randint(888,999)
897
>>> random.randint(888,999)
989
>>> random.randint(888,999)
995
random.randrange(start, stop[, step]) #返回指定范围的整数
>>> random.randrange(2,20,2)
6
>>> random.randrange(2,20,2)
4
>>> random.randrange(2,20,2)
14
2.浮点数
random.random() #返回一个浮点数,范围是0.0 到1.0
>>> random.random()
0.22197993728352594
>>> random.random()
0.8683996624230081
>>> random.random()
0.29398514954873434
random.uniform(a,b)#返回一个指定范围的浮点数
>>> random.uniform(1, 10)
3.0691737651343636
>>> random.uniform(1, 10)
9.142357395475619
>>> random.uniform(1, 10)
6.927435868405478
3.随机序列
random.choice()#从非空序列中返回一个随机元素
>>> name
[‘du’, ‘diao’, ‘han’, ‘jiang’, ‘xue’]
>>> random.choice(name)
‘xue’
>>> random.choice(name)
‘xue’
>>> random.choice(name)
‘du’
>>> random.choice(name)
‘du’
>>> random.choice(name)
‘du’
>>> random.choice(name)
‘jiang’
#随机返回指定长度的子序列
>>> random.sample(name,2)
[‘xue’, ‘du’]
>>> random.sample(name,2)
[‘diao’, ‘jiang’]
>>> random.sample(name,2)
[‘xue’, ‘du’]
生成指定长度的随机密码:
[root@zhu ~]# python jiang.py
GrDUytJE
[root@zhu ~]# python jiang.py
8XaCoUTz
[root@zhu ~]# cat jiang.py
import random,string
chars=string.ascii_letters+string.digits
print ‘’.join([random.choice(chars) for i in range(8)])
#!/usr/bin/env python
import random
import string
import sys
similar_char = ‘0OoiI1LpP’
upper = ‘’.join(set(string.uppercase) - set(similar_char))
lower = ‘’.join(set(string.lowercase) - set(similar_char))
symbols = ‘!#$%&\*+,-./:;=?@^_`~’
numbers = ‘123456789’
group = (upper, lower, symbols, numbers)
def getpass(lenth=8):
pw = \[random.choice(i) for i in group\]
con = ''.join(group)
for i in range(lenth-len(pw)):
**pw.append(random.choice(con))**
random.shuffle(pw)
return ''.join(pw)
genpass = getpass(int(sys.argv[1]))
print genpass
#!/usr/bin/env python
import random
import string
def GenPassword(length):
chars=string.ascii\_letters+string.digits
return ''.join(\[random.choice(chars) for i in range(length)\])
if __name__==“__main__”:
for i in range(10):
print GenPassword(15)
#-*- coding:utf-8 -*-
‘’’
简短地生成随机密码,包括大小写字母、数字,可以指定密码长度
‘’’
#生成随机密码
from random import choice
import string
#python3中为string.ascii_letters,而python2下则可以使用string.letters和string.ascii_letters
def GenPassword(length=8,chars=string.ascii_letters+string.digits):
return ''.join(\[choice(chars) for i in range(length)\])
if __name__==“__main__”:
#生成10个随机密码
for i in range(10):
#密码的长度为8
print(GenPassword(8))
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#导入random和string模块
import random, string
def GenPassword(length):
#随机出数字的个数
numOfNum = random.randint(1,length-1)
numOfLetter = length - numOfNum
#选中numOfNum个数字
slcNum = \[random.choice(string.digits) for i in range(numOfNum)\]
#选中numOfLetter个字母
slcLetter = \[random.choice(string.ascii\_letters) for i in range(numOfLetter)\]
#打乱这个组合
slcChar = slcNum + slcLetter
random.shuffle(slcChar)
#生成密码
genPwd = ''.join(\[i for i in slcChar\])
return genPwd
if __name__ == ‘__main__’:
print GenPassword(6)
round取相邻整数
print(round(1.4))
print(round(1.8))
输出:
1
2
查看各个进程读写的磁盘IO
#!/usr/bin/env python
# -*- coding=utf-8 -*-
import sys
import os
import time
import signal
import re
class DiskIO:
def __init__(self, pname=None, pid=None, reads=0, writes=0):
self.pname = pname
self.pid = pid
self.reads = 0
self.writes = 0
def main():
argc = len(sys.argv)
if argc != 1:
print "usage: please run this script like \[./diskio.py\]"
sys.exit(0)
if os.getuid() != 0:
print "Error: This script must be run as root"
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
os.system(‘echo 1 > /proc/sys/vm/block_dump’)
print “TASK PID READ WRITE”
while True:
**os.system**('dmesg -c > /tmp/diskio.log')
l = \[\]
f = open('/tmp/diskio.log', 'r')
line = f.readline()
while line:
m = re.match(\\
'^(\\S+)\\((\\d+)\\): (READ|WRITE) block (\\d+) on (\\S+)', line)
if m != None:
if not l:
l.append(DiskIO(m.group(1), m.group(2)))
line = f.readline()
continue
found = False
for item in l:
if item.pid == m.group(2):
found = True
if m.group(3) == "READ":
item.reads = item.reads + 1
elif m.group(3) == "WRITE":
item.writes = item.writes + 1
if not found:
l.append(DiskIO(m.group(1), m.group(2)))
line = f.readline()
time.sleep(1)
for item in l:
print "%-10s %10s %10d %10d" % \\
(item.pname, item.pid, item.reads, item.writes)
def signal_handler(signal, frame):
os.system(‘echo 0 > /proc/sys/vm/block_dump’)
sys.exit(0)
if __name__==“__main__”:
main()
Python自动化运维之简易ssh自动登录
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pexpect
import sys
ssh = pexpect.spawn('ssh root@192.168.20.103 ')
fout = file(‘sshlog.txt’, ‘w’)
ssh.logfile = fout
ssh.expect(“root@192.168.20.103’s password:”)
ssh.sendline(“yzg1314520”)
ssh.expect(‘#’)
ssh.sendline(‘ls /home’)
ssh.expect(‘#’)
Python运维-获取当前操作系统的各种信息
#通过Python的psutil模块,获取当前系统的各种信息(比如内存,cpu,磁盘,登录用户等),并将信息进行备份
# coding=utf-8
# 获取系统基本信息
import sys
import psutil
import time
import os
#获取当前时间
time_str = time.strftime( “%Y-%m-%d”, time.localtime( ) )
file_name = “./” + time_str + “.log”
if os.path.exists ( file_name ) == False :
os.mknod( file_name )
handle = open ( file_name , “w” )
else :
handle = open ( file_name , “a” )
#获取命令行参数的个数
if len( sys.argv ) == 1 :
print_type = 1
else :
print_type = 2
def isset ( list_arr , name ) :
if name in list\_arr :
return True
else :
return False
print_str = “”;
#获取系统内存使用情况
if ( print_type == 1 ) or isset( sys.argv,“mem” ) :
memory_convent = 1024 * 1024
mem = psutil.virtual_memory()
print_str += " 内存状态如下:\n"
print_str = print_str + " 系统的内存容量为: “+str( mem.total/( memory_convent ) ) + " MB\n”
print_str = print_str + " 系统的内存以使用容量为: “+str( mem.used/( memory_convent ) ) + " MB\n”
print_str = print_str + " 系统可用的内存容量为: "+str( mem.total/( memory_convent ) - mem.used/( 1024*1024 )) + “MB\n”
print_str = print_str + " 内存的buffer容量为: “+str( mem.buffers/( memory_convent ) ) + " MB\n”
print_str = print_str + " 内存的cache容量为:" +str( mem.cached/( memory_convent ) ) + " MB\n"
#获取cpu的相关信息
if ( print_type == 1 ) or isset( sys.argv,“cpu” ) :
print_str += " CPU状态如下:\n"
cpu_status = psutil.cpu_times()
print_str = print_str + " user = " + str( cpu_status.user ) + “\n”
print_str = print_str + " nice = " + str( cpu_status.nice ) + “\n”
print_str = print_str + " system = " + str( cpu_status.system ) + “\n”
print_str = print_str + " idle = " + str ( cpu_status.idle ) + “\n”
print_str = print_str + " iowait = " + str ( cpu_status.iowait ) + “\n”
print_str = print_str + " irq = " + str( cpu_status.irq ) + “\n”
print_str = print_str + " softirq = " + str ( cpu_status.softirq ) + “\n”
print_str = print_str + " steal = " + str ( cpu_status.steal ) + “\n”
print_str = print_str + " guest = " + str ( cpu_status.guest ) + “\n”
#查看硬盘基本信息
if ( print_type == 1 ) or isset ( sys.argv,“disk” ) :
print_str += " 硬盘信息如下:\n"
disk_status = psutil.disk_partitions()
for item in disk_status :
print\_str = print\_str + " "+ str( item ) + "\\n"
#查看当前登录的用户信息
if ( print_type == 1 ) or isset ( sys.argv,“user” ) :
print_str += " 登录用户信息如下:\n "
user_status = psutil.users()
for item in user_status :
print\_str = print\_str + " "+ str( item ) + "\\n"
print_str += “---------------------------------------------------------------\n”
print ( print_str )
handle.write( print_str )
handle.close()
Python自动化运维学习笔记
psutil 跨平台的PS查看工具
执行pip install psutil 即可,或者编译安装都行。
# 输出内存使用情况(以字节为单位)
import psutil
mem = psutil.virtual_memory()
print mem.total,mem.used,mem
print psutil.swap_memory() # 输出获取SWAP分区信息
# 输出CPU使用情况
cpu = psutil.cpu_stats()
printcpu.interrupts,cpu.ctx_switches
psutil.cpu_times(percpu=True) # 输出每个核心的详细CPU信息
psutil.cpu_times().user # 获取CPU的单项数据 [用户态CPU的数据]
psutil.cpu_count() # 获取CPU逻辑核心数,默认logical=True
psutil.cpu_count(logical=False) # 获取CPU物理核心数
# 输出磁盘信息
psutil.disk_partitions() # 列出全部的分区信息
psutil.disk_usage(‘/’) # 显示出指定的挂载点情况【字节为单位】
psutil.disk_io_counters() # 磁盘总的IO个数
psutil.disk_io_counters(perdisk=True) # 获取单个分区IO个数
# 输出网卡信息
psutil.net_io_counter() 获取网络总的IO,默认参数pernic=False
psutil.net_io_counter(pernic=Ture)获取网络各个网卡的IO
# 获取进程信息
psutil.pids() # 列出所有进程的pid号
p = psutil.Process(2047)
p.name() 列出进程名称
p.exe() 列出进程bin路径
p.cwd() 列出进程工作目录的绝对路径
p.status()进程当前状态[sleep等状态]
p.create_time() 进程创建的时间 [时间戳格式]
p.uids()
p.gids()
p.cputimes() 【进程的CPU时间,包括用户态、内核态】
p.cpu_affinity() # 显示CPU亲缘关系
p.memory_percent() 进程内存利用率
p.meminfo() 进程的RSS、VMS信息
p.io_counters() 进程IO信息,包括读写IO数及字节数
p.connections() 返回打开进程socket的namedutples列表
p.num_threads() 进程打开的线程数
#下面的例子中,Popen类的作用是获取用户启动的应用程序进程信息,以便跟踪程序进程的执行情况
import psutil
from subprocess import PIPE
p =psutil.Popen([“/usr/bin/python” ,“-c”,“print ‘helloworld’”],stdout=PIPE)
p.name()
p.username()
p.communicate()
p.cpu_times()
# 其它
psutil.users() # 显示当前登录的用户,和Linux的who命令差不多
# 获取开机时间
psutil.boot_time() 结果是个UNIX时间戳,下面我们来转换它为标准时间格式,如下:
datetime.datetime.fromtimestamp(psutil.boot_time()) # 得出的结果不是str格式,继续进行转换 datetime.datetime.fromtimestamp(psutil.boot_time()).strftime(‘%Y-%m-%d%H:%M:%S’)
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
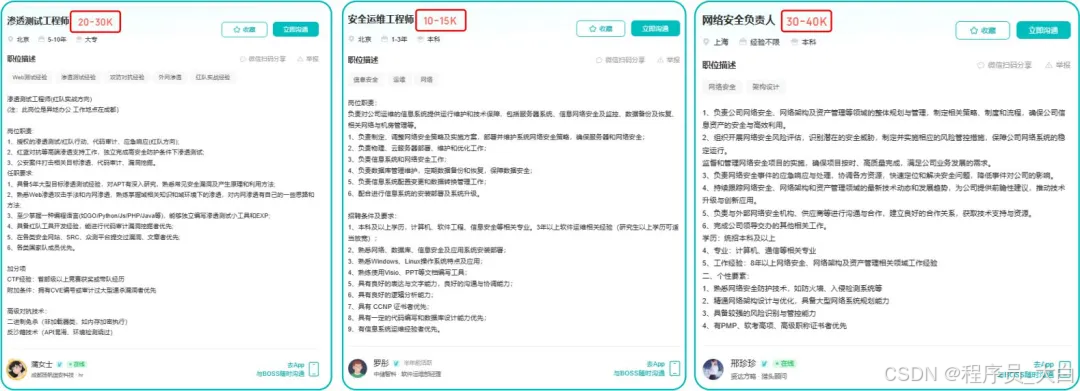
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
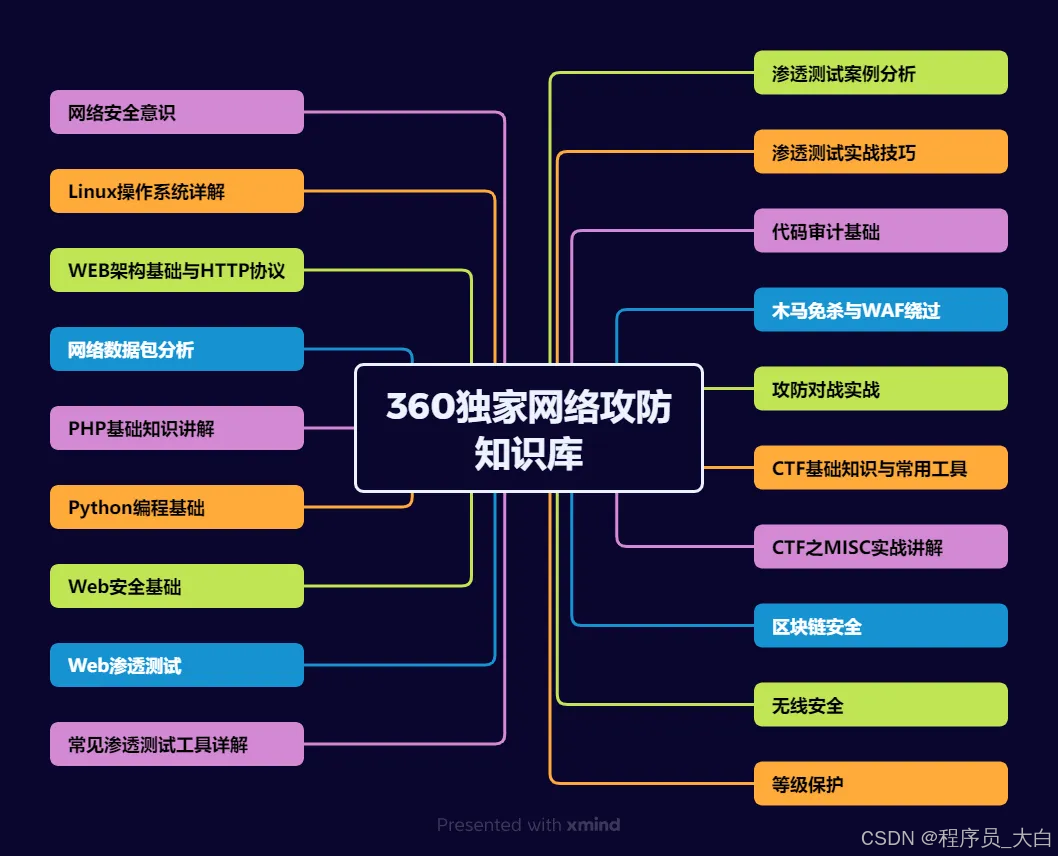
运维转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









