







01
**
LORA 微调、P-tuning 微调
**
规模预训练模型进行参数高效微调的方法有两类:LORA 微调、P-tuning 微调。
**LORA(Language-oriented Reinforcement Adapter)**是一种为自然语言处理(NLP)设计的强化学习算法,它旨在通过适应环境来改进模型的性能。在NLP领域,微调(Fine-tuning)是一种常用的技术,用于使用特定任务的数据集来调整一个预训练的模型,使其能够更好地执行特定任务。
**P-tuning(Prompt Tuning)**是一种新的模型微调方法,它通过修改输入提示(prompt)来调整模型对特定任务的适应性,而不是直接调整模型的权重。这种方法的主要思想是利用预训练语言模型的可塑性,通过设计不同的提示来引导模型生成或预测任务相关的输出。
02
**
两种微调的优缺点
**
✍P-tunig的优点
**1. 简单高效:**P-tuning通常比传统的权重微调更简单,因为它不需要调整模型的权重,只需要设计不同的提示。这使得P-tuning更容易实现和实验。
**2. 可扩展性:**P-tuning可以通过设计更多的提示来提高模型的性能,而传统的权重微调可能受到模型容量和计算资源的限制。
**3. 泛化能力:**P-tuning可以通过设计通用的提示来提高模型的泛化能力,使得模型能够更好地适应不同的任务和数据集。
✍P-tuning的缺点
**1. 提示设计:**P-tuning的成功很大程度上取决于提示的设计。设计有效的提示需要深入理解任务和语言模型的工作原理,这可能需要大量的实验和调整。
**2. 提示效率:**P-tuning的性能可能受到提示效率的影响。一些提示可能比其他提示更有效,这需要额外的实验来确定最佳提示。
**3. 模型依赖性:**P-tuning依赖于预训练的语言模型。如果预训练模型存在偏差或局限性,那么P-tuning的效果可能会受到影响。
✍****传统的权重微调的优点
**1. 直接优化:**传统的权重微调直接优化模型的权重,这使得模型能够更精确地适应特定任务。
**2. 可控性:**传统的权重微调允许研究人员更精确地控制模型的行为和性能。
✍传统的权重微调的缺点
**1. 计算成本:**传统的权重微调通常需要大量的计算资源,因为它涉及到调整模型的所有权重。
**2. 模型容量限制:**传统的权重微调可能受到模型容量和计算资源的限制,这可能限制了模型的性能和可扩展性。
**3. 泛化能力:**传统的权重微调可能更专注于特定任务,这可能会影响模型的泛化能力。
03
**
训练模型
**
这里我们以LORA微调为例,来训练模型。
在训练前,我们先来让认识一下微调的参数。
**参数路径:**ChatGLM3/finetune_demo/configs/lora.yaml
`data_config: train_file: train.json # 训练数据集文件路径 val_file: dev.json # 验证数据集文件路径 test_file: dev.json # 测试数据集文件路径 num_proc: 16 # 数据处理进程数 max_input_length: 256 # 输入序列的最大长度 max_output_length: 2000 # 输出序列的最大长度 training_args: # 参见 `transformers.Seq2SeqTrainingArguments` 的文档 output_dir: ./output # 模型输出目录 max_steps: 500 # 训练的最大步数 # 根据数据集调整学习率 learning_rate: 5e-5 # 学习率 # 数据加载设置 per_device_train_batch_size: 4 # 每个设备的训练批次大小 dataloader_num_workers: 16 # 数据加载工作进程数 remove_unused_columns: false # 是否移除未使用的列 # 检查点保存设置 save_strategy: steps # 保存策略,按步数 save_steps: 500 # 保存模型的步数间隔 # 日志记录设置 log_level: info # 日志级别 logging_strategy: steps # 日志记录策略,按步数 logging_steps: 10 # 记录日志的步数间隔 # 评估设置 per_device_eval_batch_size: 16 # 每个设备的评估批次大小 evaluation_strategy: steps # 评估策略,按步数 eval_steps: 500 # 评估模型的步数间隔 # 优化器设置 # adam_epsilon: 1e-6 # Adam优化器的epsilon值 # 若要检测nan或inf值,取消注释以下行 # debug: underflow_overflow # 调试选项,检查数值溢出或下溢 predict_with_generate: true # 是否在预测时生成输出 # 参见 `transformers.GenerationConfig` 的文档 generation_config: max_new_tokens: 512 # 生成新标记的最大数量 # 如果使用deepspeed,请设置绝对路径 #deepspeed: ds_zero_2.json # DeepSpeed配置文件路径 # 如果使用CPU进行训练,设置为true use_cpu: false # 是否使用CPU进行训练 peft_config: peft_type: LORA # PEFT (Parameter-Efficient Fine-Tuning) 类型 task_type: CAUSAL_LM # 任务类型,因果语言模型 r: 8 # LORA适配器的秩 lora_alpha: 32 # LORA适配器的alpha值 lora_dropout: 0.1 # LORA适配器的dropout比例`
在了解微调参数了以后我们就可以正式训练模型了:
✍1.准备测试数据
准备训练数据:train.json
准备验证数据:dev.json
测试数据的格式要求:
{"messages": [{"role": "system", "content": "你是一名软件测试工程师。你的任务是根据需求内容生成测试用例。请注意一定要严谨,要针对指定的需求内容生成测试用例,为了避免重复不要创造需求或者创作多余的测试用例。"}, {"role": "user", "content": "完整需求内容为:{"用户可以点击商品图片或名称,将其添加到购物车中"}, {"role": "assistant", "content": "[{'testpoint': '点击图片添加商品到购物车 ', 'operation': '1、点击商品图片', 'expectedresult': '商品成功添加到购物车 '}]"}]}
✍2.启动训练
2.1打开服务器,进入虚拟环境:source myenv/bin/activate
2.2确认transformers的版本是4.40.0;如果不是,删除重新安装对应版本
查看版本:pip list
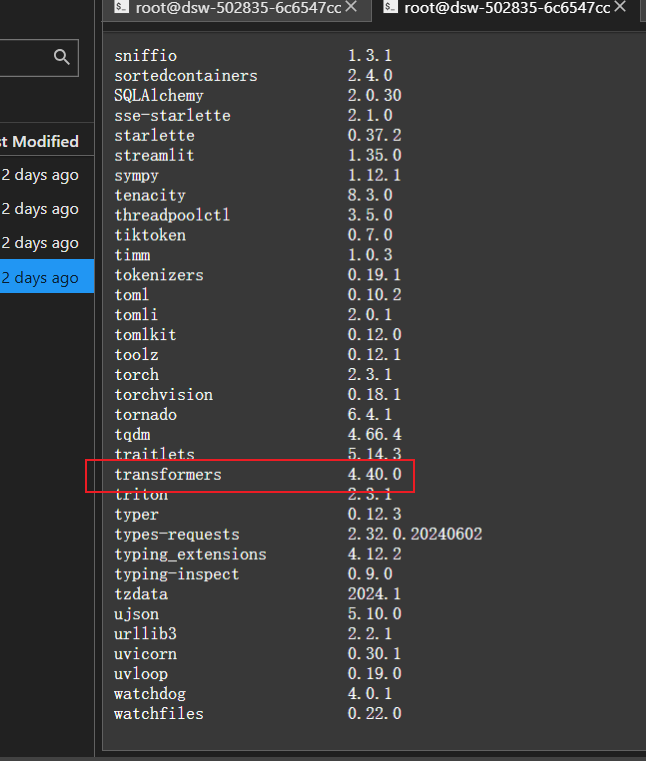
卸载老版本:pip uninstall transformers
安装指定版本:pip install transformers==4.40.0
2.3更新最新版本:pip install —upgrade accelerate(两个-)
2.4把chatglm3-6b复制一份到:/mnt/workspace/ChatGLM3
找到chatglm3-6路径:find -name chatglm3-6b
复制:cp -r ./mnt/systemDisk/.cache/modelscope/ZhipuAI/chatglm3-6b /mnt/workspace/ChatGLM3/
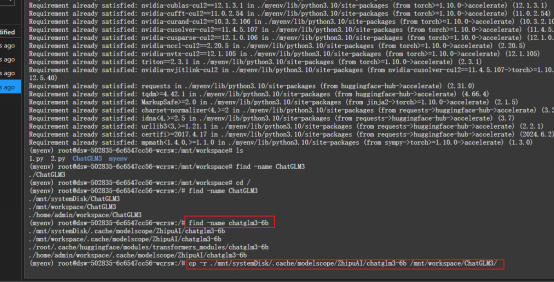
2.5在/mnt/workspace/chatGLM3/finetune demo/日录下创建data目录
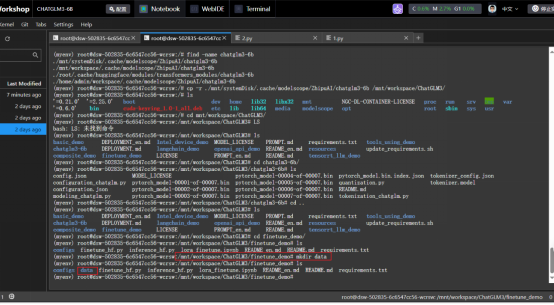
2.6将准备的训练数据集整理成train.json和dev.json 两份数据集
2.7数据集上传到data目录
2.8将/mnt/workspace/chatGLM3/finetune demo目录下finetune hf.py文件源码的第530行eval dataset=val dataset.select(list(range(50)))代码中的iist(range(50))改为你实际dev.json 中的数据条数总数,比如我的只有7条,我就应该改为eval dataset=val dataset.select(list(range(7)))
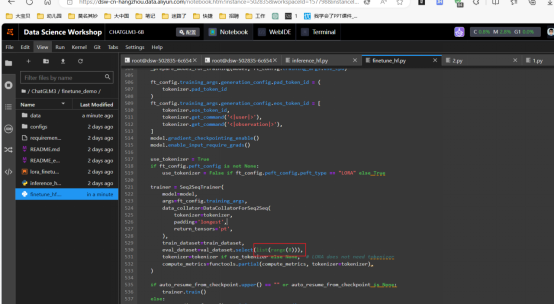
2.9训练模型:python finetune_hf.py /mnt/workspace/ChatGLM3/finetune_demo/data /mnt/workspace/ChatGLM3/chatglm3-6b /mnt/workspace/ChatGLM3/finetune_demo/configs/lora.yaml
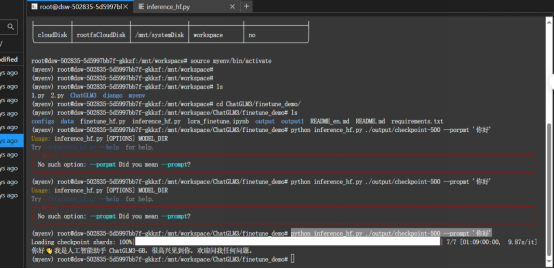
✍3.训练结束查看****效果
python inference_hf.py ./output/checkpoint-500 --prompt ‘你好’
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









