






一、SpringBoot项目报错
先展示一下项目报错



主要的报错有三个
- java.lang.IllegalStateException: Failed to load property source from 'file:/D:/zhuomian/%E。。。
- Caused by: org.yaml.snakeyaml.error.YAMLException: java.nio.charset.MalformedInputException: Input length = 1
- Caused by: java.nio.charset.MalformedInputException: Input length = 1
最直接的原因应该是最后一个,有时候会变成Input length = 2
这个报错原因大概意思就是,编译的时候有的字符无法识别。
二、解决
正常情况,编译的时候,按照代码文件编码的方式解码就能获得正确的代码内容。就不会报这个错了。既然如此,那就是代码文件的编码方式和编译器的解码方式不一致导致的该问题。
1.编码格式
编码格式不是说我们代码中的使用的是中文还是英文,我们写的代码内容都是普通的文本格式。但是代码文件不会以文本格式保存代码,而是通过特定的编码方式保存成二进制数据。常用的编码格式是UTF-8或GBK,大概说一下区别
- UTF-8:能将几乎所有语言都编码成二进制数据,也是最常用的编码方式
- GBK:主要能编码中英文、数字等数据,主要特点就是能编码中文。
1.1 IDEA中查看文件的编码方式
我的IEDA是2023版的,不同版本可以在网上查一下
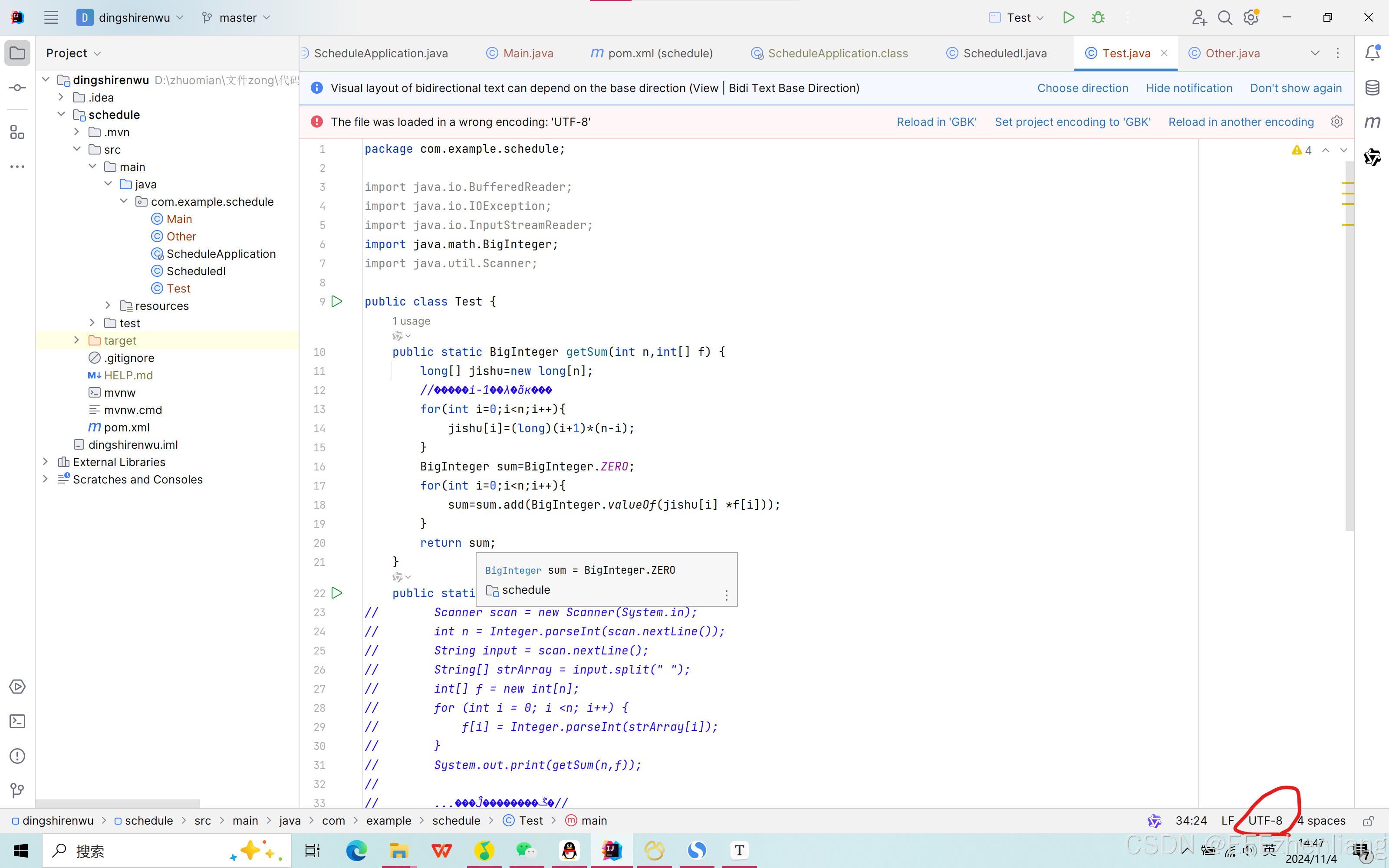
在右下角就可以查看或修改。
1.2 修改文件的编码方式
首先文件的编码格式最好不要直接修改。
原因: 不同编码方式不仅能编码的内容可能不同,将文本转换成二进制数据的方式也可能不同。
例如:UTF-8中汉字会被存储成2到4个字节,而GBK中汉字则会被固定存储为2个字节。
解决: 可以先将文件内容剪切或复制成纯文本,在将其放进一个空的其他编码方式的文件中,纯文本就会自动根据对应的编码方式保存起来。
IDEA中修改文件的编码方式
IDEA则提供了便捷的操作界面。
- 第一步,点击上一个图片的编码方式按钮(上图是UTF-8),会出现一个编码方式列表
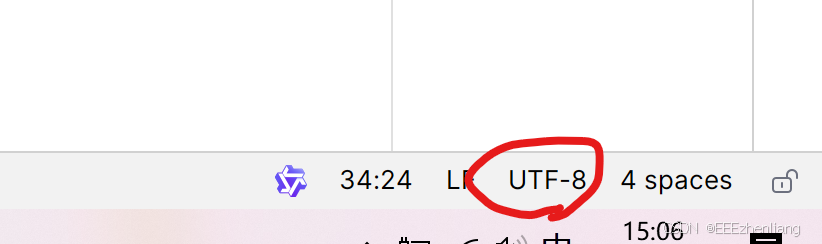
- 第二步,点击出现的编码方式列表中想变成的那个
会出现一个窗口
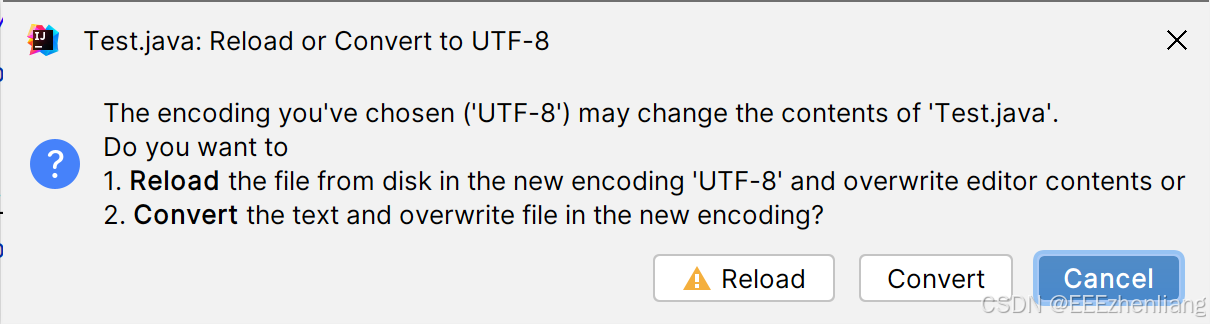
- 第三步,根据需要进行选择
- Reload:代表直接修改编码方式,可能会将内容变成乱码
点击之后会出现一个新窗口,可以选择坚持修改或者取消
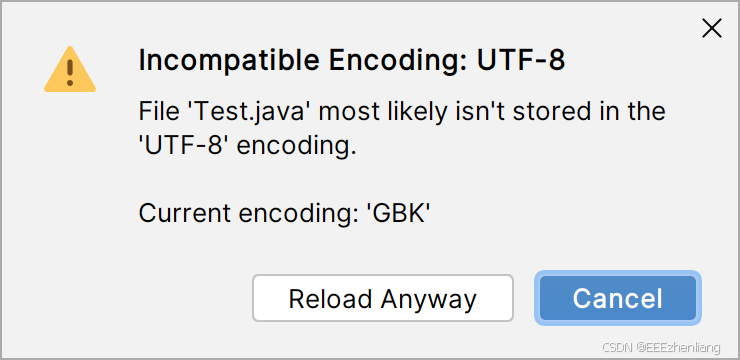
- Convert:代表先复制为纯文本,再根据文本内容转换编码方式,不会有乱码风险
- Cancel:取消
- Reload:代表直接修改编码方式,可能会将内容变成乱码
另一种修改方式
还有一种修改编码方式的方法就是:File --> Settings --> Editor —>File Encodings
这个下面解码方式中会详细讲解
2.IDEA中编译器的解码方式
点击左上角
然后依次选择:File --> Settings --> Editor —>File Encodings
就会出现如下界面
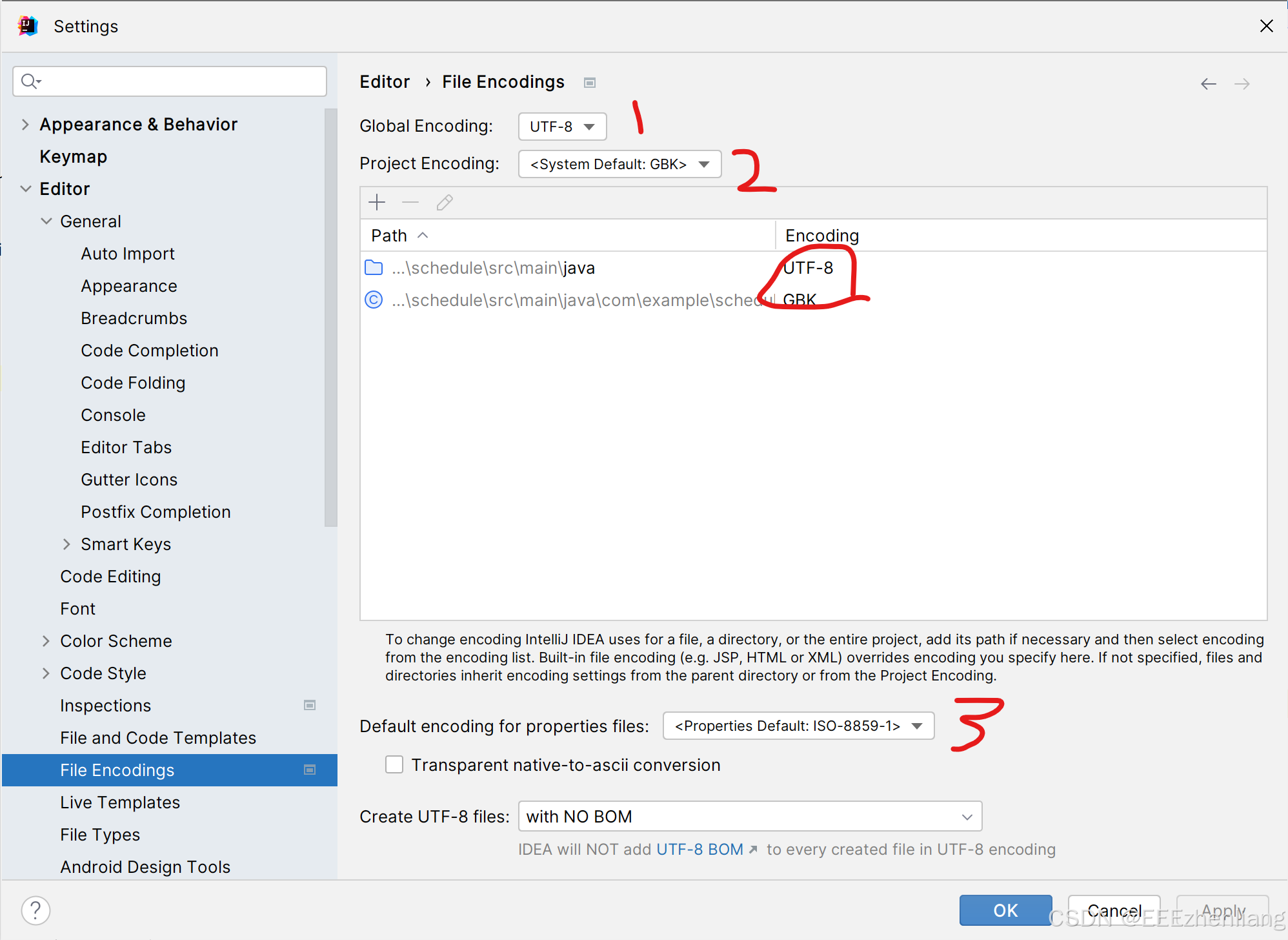
- 1代表全局编码方式,指定所有项目的文件的编码和解码方式
- 2代表项目编码方式,会有默认值,指定本项目的编码和解码方式。(2的优先级比1高,2生效则1不生效)
- 画圈的地方则是所有项目文件的编码方式(优先级比2高),有的时候相同编码方式的文件会归为一行,这里也可以修改文件的编码方式
- 3代表properties文件的编码和解码方式,这个学过spring类的项目的朋友应该知道,如果项目里面没有就不用管了。
**注意:**修改之后不要忘记点Apply
3.解决
这个报错出现的原因就是,某些文件的编码方式和解码方式不同。
很多人就会比较奇怪,编码方式和解码方式不是同时指定的吗?其实有的文件会例外(感觉是idea的bug)
如yml文件好像只能指定编码方式,解码方式则会使用2(即项目的编码方式)
因此,尽量保证所有文件的编码方式和2相同(建议都改成utf-8,因为可编译内容很全,gbk能编译的utf-8都能编译)。
**注意:**修改之后记得手动删除target文件或通过maven的clean删除编译后的文件(建议使用maven的clean),之后运行就没问题了。


















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











