









有感于市面面上太多挂着AI一词,就开始各种包装和营销做一些AI不相关的事情,因此写一篇AI相关名称和原理的文章,我将用通俗易懂的语言串联一些AI相关的概念和原理。
AI时代,杜绝只会用AI玩个简单图和视频,却完全不懂原理的情况。
希望为所有对AI感兴趣的朋友,无论是技术人、互联网人,还是普通读者,理清AI相关来龙去脉,让你不再轻易被表象迷惑。
放心,我会尽量用通俗的语言,漫谈形式来介绍。

对于技术人员来说,掌握这些原理能帮助他们更好地应用AI并深入学习。而普通读者则可以了解AI的工作原理,尤其是生成式GPT的运作方式,毕竟大多数人主要接触的是AI的应用层。
我们从火爆的AI代表之一ChatGPT说起。这一生成式模型自发布以来,迅速推动了行业的迭代升级,涉及文本、图像、音视频、逻辑推理和私有模型训练,也解决很多繁琐的流程和智能化的判断和推理的改变。
那么,ChatGPT、生成式模型是如何工作的呢?普通人要知道吗,我们又如何将需求传达给大模型,最终得到所需的结果?
首先,先来说下机器学习,通俗理解机器就是让机器来学习然后告知结果,有点白话是吧,其实最底层原理就是这样,让机器来学习过往数据和经验,并通过大量数据来持续改进相关误差(调参),最终在新的情况下做出决策判断或者预测。
那么,ChatGPT、机器学习与生成式模型之间有什么关系呢?
ChatGPT是基于生成式模型的一种应用,而生成式模型是机器学习的一种方法,专注于生成数据(例如文本、图像和视频)。
因此,ChatGPT实际上是利用机器学习技术提供自然语言处理服务的一款应用。
知道了大概几个概念,那ChatGPT的怎么工作的?
机器学习内部细分领域众多,ChatGPT使用了多种机器学习相关技术,尤其是深度神经网络。提到深度学习,就不得不介绍Transformer架构模型,它在大模型中被广泛应用,ChatGPT正是基于这一架构。
Transformer最早在2017年的论文《Attention is All You Need》中提出,结构如下所示:
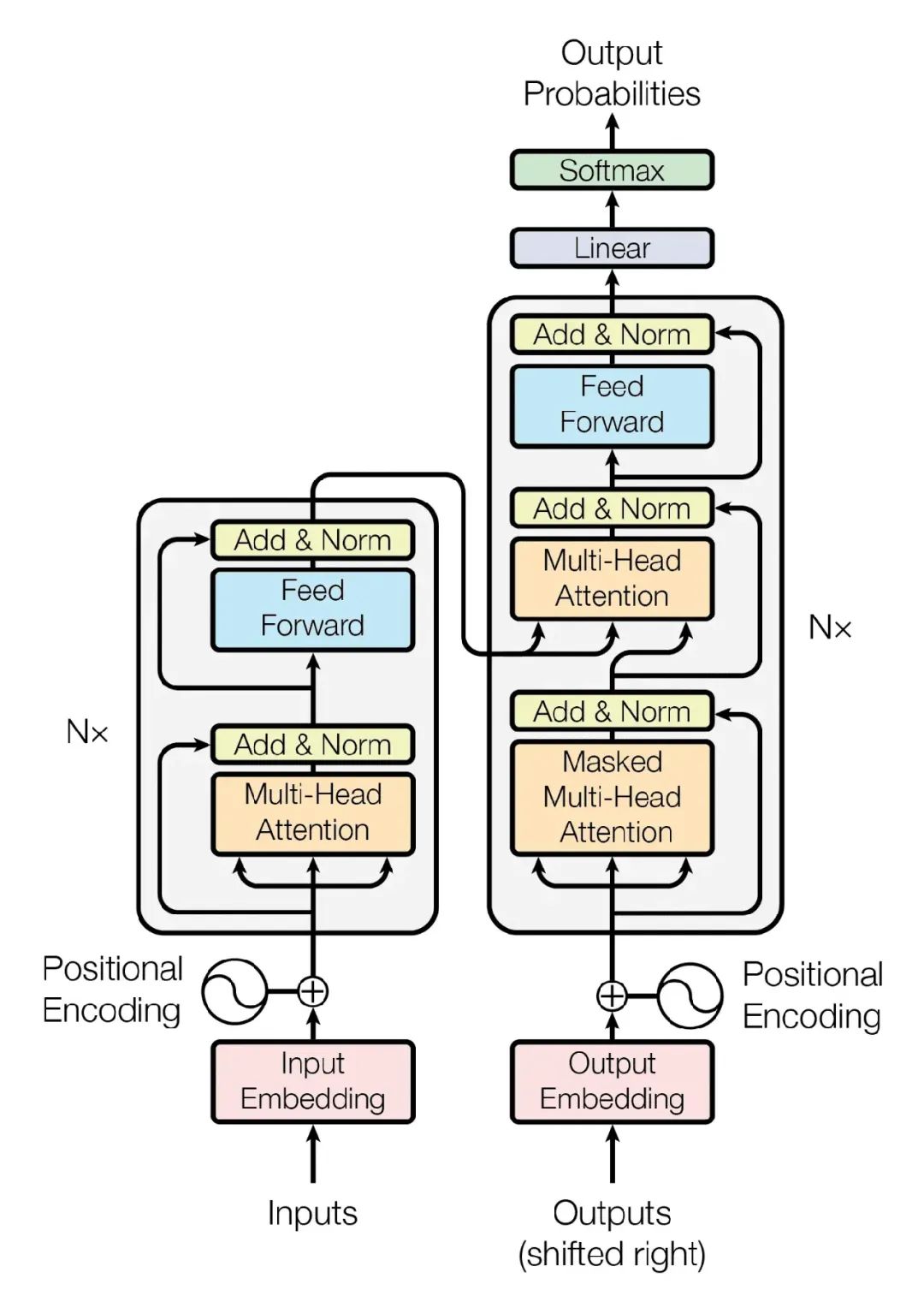
我们大概了解下这个架构构成的核心模块即可,可以看到有模型的输入和输出、位置编码、编码器和解码器、多头注意力机制,内部一些子的链接层先不用关注,可以理解为Transformer也是一个复杂的深度学习模型,通过这个架构来把我们前面提到的当问chatgpt一些问题时chatgpt告诉你想要的结果。
我们稍微说下核心的模块,用通俗语言来介绍下:
先说编码和解码这个比较好理解,就是我们输入问题,收集到解码器处理,然后把相关结果通过解码器来输出。但这里面会有着复杂的处理。
当开始输入的数据会先到词向量层(Input Embedding)这一步是把每个单词转变为计算机能理解和后续可计算的形式来存储。
想象一下,把每个词都会进行拆分,变为一个个特定的编码,然后通过向量层来存储,向量层会把词义、语法直接关联关系,通过向量方式来存储,这样计算机就能处理它们。目的是把词直接的相似在多维度上方便进行计算和区分。通俗来理解就是向量可以存储很多词义对应的特征数据。
再往上可以看到,位置编码(Positional Encoding)因为 Transformer 同时处理整句话,而不是一个个词,所以需要告诉计算机每个词在句子中的位置。通过向量计算方式进行每个词关联权重。
到了编码器内部就会使用,自注意力机制(Self-Attention)这是 Transformer 的核心部分。它允许模型在分析一个词时,关注句子中所有其他词。
例如,在句子“饭在桌上”中,当它分析“饭”时,能知道“桌”是哪个词。可以理解为,通过这种方式帮助模型理解上下文和词之间的关系。
还有一个前置神经网络(Feed-Forward Neural Network)在自注意力机制处理后,数据会经过一个简单的神经网络。这个步骤就像是给模型一个思考和优化时间,让它在理解后进一步处理信息向后传递,图上可以看到自注意力机制模块时间是有多个的并行来处理。
在往后,可以看到解码器(Decoder)核心层,这个除了接受编码层传递过来的数据,还会把之前已经生成的文本进行输入来接收(图右侧部分)目的是什么?为了保持之前对话连贯性和合理性。
右侧的界面器里也包括位置编码、多头自注意力机制来处理对应的词关联关系,产生相关的结果不一样的是使用了带掩码的自注意力机制,目的是预测结果的输出。
其他和左侧一样也有前置神经网络,都是为了把预备的结果更加顺畅,在往后输出部门跟左侧有一定的形似。
为什么有时结果会一本正经的胡说八道?
到最后结果的输出,还会经历Linear、SoftMax会把转换的词汇表按照概率来进行组装,如果某个词概率高,很可能就会被选中。
比如输出的词有,北方人喜欢的主食是:米饭(50%)、馒头(20%)、面条(30%),那米饭这个词就会被最终组装并输出来。北方人喜欢的主食是米饭,而其实北方更多是面食为主。
可想而知,如果给大模型大量错误的数据,他是完全可以正儿八经的胡说八道的,这个也是在ChatGPT早期有大量胡说的例子。
也是我经常说的为什么用AI,一定要在自己熟悉的赛道和行业里结合来使用,否则错误的指导和信息你根本无法判断。
PS: 也欢迎大家评论和交流~ 更多文章也可关注微信公号:良技漫谈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









