




详细内容见:
1 注意力机制:
- 简单通俗描述计算过程:Q,K,V(query,key,value); 我们首先需要计算一下 Q 和 K的距离(相似度),可以使用向量点积,余弦相似性,或者 MLP,计算结果进行softmax处理,一是归一化处理,二是突出高权重K,然后根据最新处理的K 值与对应 V 值,加权求和即是 attention 值
- 举例:
- 1 我喜欢吃苹果,也喜欢吃香蕉,不喜欢吃榴莲”(3 个短语,对应 3 个信息单元)
- 2 我最喜欢吃什么水果?” 这个问题(Q):
- 3 生成 K 和 V:K1=“苹果”,V1=“喜欢吃”;K2=“香蕉”,V2=“喜欢吃”;K3=“榴莲”,V3=“不喜欢吃”;
- 4 Q=“最喜欢的水果”,和 K 匹配:Q vs K1(苹果):相关(喜欢),权重 3;Q vs K2(香蕉):相关(喜欢),权重 3;Q vs K3(榴莲):无关(不喜欢),权重 0;
- 5 加权合并 V:重点提取 “喜欢吃苹果” 和 “喜欢吃香蕉”,最终输出 “你最喜欢吃苹果和香蕉”。
2 自注意力机制:
- 没有外来的 Q,自己这段信息分成多个部分,不同部分和其他部分充当 Q,K,V
- 举例:
- 1 “小明去超市买了牛奶,他喝完后觉得很好喝”(输入文本的 6 个词:小明、去、超市、买了、牛奶、他、喝完、觉得、很好喝)。
- 2 写 “他” 这个词时,你得知道 “他” 指的是谁 —— 这就是自注意力机制在工作
- 3 每个词都当 “提问者(Q)”:“他” 这个词会生成一个 Q(查询):“他指的是谁?”同时,每个词也都当 “被查者(K/V)”:所有词都会生成自己的 K(标签)和 V(内容):
- 小明:K=“人名 - 小明”,V=“句子主语,去超市的人”;
- 去:K=“动作 - 去”,V=“前往某地”;
- 超市:K=“地点 - 超市”,V=“购物的地方”;
- 他:K=“代词 - 他”,V=“指代前文的人”;
- 4 Q "他"去匹配所有词的 K:Q(“我指的是谁?”) vs K(小明);Q vs K(去 / 超市 / 牛奶);Q vs K(他自己);
- 5 加权提取 V 的信息:重点提取 “小明” 的 V,其他词的 V 几乎忽略;最终 “他” 就明确了:这就是自注意力通过 “内部查询” 找到的关联。
- 举例:
3 多头注意力机制:
- 把自注意力机制复制多份(“多个头”),每个头专注于找文本中不同维度的关联(比如一个头找指代关系、一个头找动作和对象、一个头找因果关系),最后把所有头的结果合并,让理解更全面。
- 举例:
- 1 “小明在超市买了牛奶,他喝完后觉得很甜,于是又买了一箱”(核心关联有 3 个:“他” 指代 “小明”、“喝” 的对象是 “牛奶”、“又买” 的原因是 “很甜”)。
- 2 所有头共享输入文本的 Q、K、V(但会各自做微小的 “参数调整”,让每个头的关注点不同)—— 相当于 3 个小组都拿到同一份报告, but 各自的分析侧重点预设不同。
- 3 头 1(负责 “指代关系”):重点找 “谁指谁”:以 “他” 为 Q(“我指谁?”),匹配所有 K,最终锁定 “小明” 的 V,得出结论:“他 = 小明”;
- 头 2(负责 “动作 - 对象关系”):重点找 “动作对应什么东西”以 “喝” 为 Q(“我针对的对象是什么?”),匹配所有 K,锁定 “牛奶” 的 V,得出结论:“喝的是牛奶”;
- 头 3(负责 “因果关系”):重点找 “为什么做这个动作”以 “又买” 为 Q(“我发生的原因是什么?”),匹配所有 K,锁定 “很甜” 的 V,得出结论:“又买是因为牛奶甜”。
- 4 把 3 个小组的结论合并:“小明在超市买了牛奶,小明喝完牛奶后觉得很甜,因为牛奶甜所以小明又买了一箱”—— 比单个头只找一种关联,理解更完整、更精准。
- 5 注意:头的数量要能被维度整除
- 6 分头是对每一个 Q,K,V 的向量化结果进行分头,也就是一段话分成几段儿
- 举例:
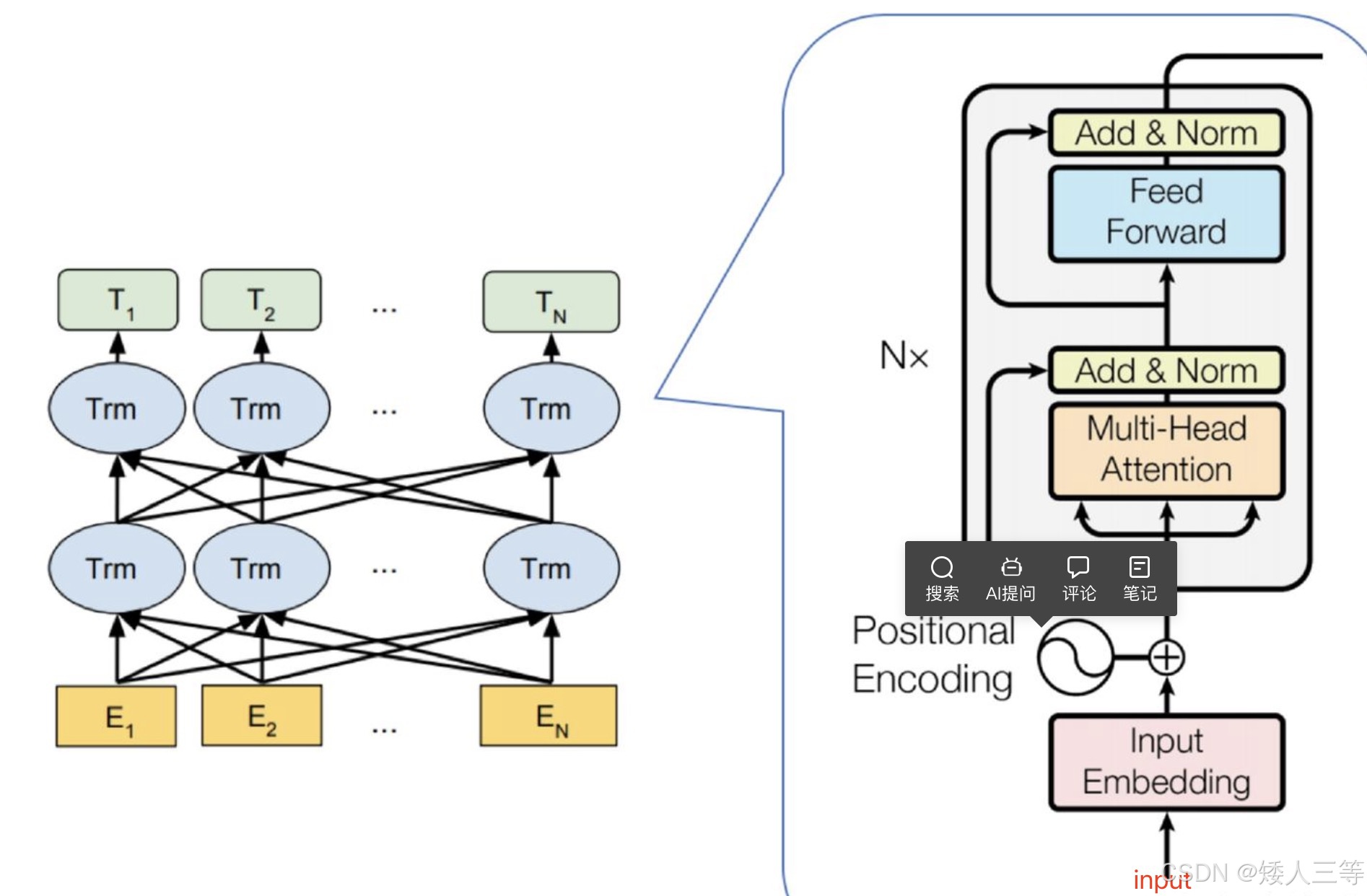
4 transform:
- 左侧 Encode:理解输入内容(能看到全文),只执行一次,可以看成是专属"词典"
- 1 输入数据(编码:见基础知识)+位置信息(PE编码用的正弦余弦距离),Sin| Cos(pos / 10000 * (2 i * d))
- 奇数用Cos,偶数用 Sin,pos 是分词位置顺序,i 是分词向量的向量值顺序,d 是向量长度
- 好处就是:可以应对未出现过更长的句子; 每个分词都有独一无二的位置信息
- 2 多头注意力机制(多头就是自注意力并行):输入信息和位置信息输入后,通过 attention 机制进一步提取更多的信息
- 3 Add 和 Norm:
- Add:此时的 Add 是一个残差连接,即 输出 = 原始输入 + 多头(原始输入)
- 1 防止过度加工,保留初始信息,防止多头处理效果差导致预训练越差;
- 2 训练随着层数增加,调整参数的信息会越传递越弱,残差连接可以保持"信号"强度
- Norm: 标准化处理(归一化属于标准化的一种),防止数值过大或者过小导致的梯度爆炸/消失; 标准化后数值小,可以加速收敛
- 爆炸就是"信号"越来越大,防止消息就是越来越弱
- Add:此时的 Add 是一个残差连接,即 输出 = 原始输入 + 多头(原始输入)
- 4 Feed Forword: 两层全连接层,一层有激活函数,一层没有,公式max(0,XW1+b1)W2+b2
- 第一层:使用全连接层提高维度放大输入数据中的有效部分,然后使用Relu 函数 max() 进一步扩大有效和无效数据的差异
- 第二层:再通过全连接层把维度降低,留下有效部分
- 1 输入数据(编码:见基础知识)+位置信息(PE编码用的正弦余弦距离),Sin| Cos(pos / 10000 * (2 i * d))
- 右侧 Dncode:生成输出(不能看到全文),以翻译任务为例
- 1 输入数据的形式: 翻译的正确"答案"和同等大小的"答案贴纸"(Mask 矩阵)乘积作为输入,这是为了确保不能提前看到答案,一开始预测的时候只能看到初始信息,其他的都被掩盖了,然后预测出第一个信息后,预测第二个信息时候,就已经能获取到初始信息+预测信息 1 了,来预测信息 2,以此类推预测得到全部结果,注意,这个过程是在一个矩阵内一次生成的!
- 2 谁来预测?不是预训练模型,预训练模型属于成品模型,此处是搭建好 Decode 框架(比如前馈,Add 和归一化等层)后,随机或者自定义参数,输入数据直接预测,根据不断训练得到最优参数
- 3 第一个多头输入数据: 翻译答案的 Embedding 结果+位置信息Embedding 结果生成Q,K,V 矩阵
- 4 第一个多头: QK 矩阵乘以"答案贴纸"(Mask 矩阵),再乘以 V,加权求和,再进行 software,多头结果拼接到一起就是最终的多头结果, 此时多头的作用,仅仅是获取了初步翻译结果词语之间的顺序,和中文答案没有任何对应关系,因为还没查"词典"
- 5 第一个 Add 和 Norm: 与 encoder 那个一毛一样
- 6 第二个多头输入数据:此时上面5 中的输入作为 Q(类似于"我要查字典"),encode输出作为 K,V(字典内索性和详细信息)
- 7 第二个多头:同样的方法计算多头结果,此时已经获取到了词典信息,正确率会提升不少
- 8 第二个Add 和 Norm: 与第一个处理方法一样
- 9 Feed Forword处理是一致的
- 10 第三个Add 和 Norm:同上
- 线性函数:把docode生成的矩阵转化成每个词表中对应的"分数",搭建 “语义特征” 到 “具体词汇” 的桥梁 —— 把抽象的语义,映射到每个具体词的 “匹配度打分"
- softmax: 做一个 “归一化转换”,让所有分数变成 0~1 之间的概率,且所有词的概率加起来等于 1;
5 bert:双向编码的预训练语言模型
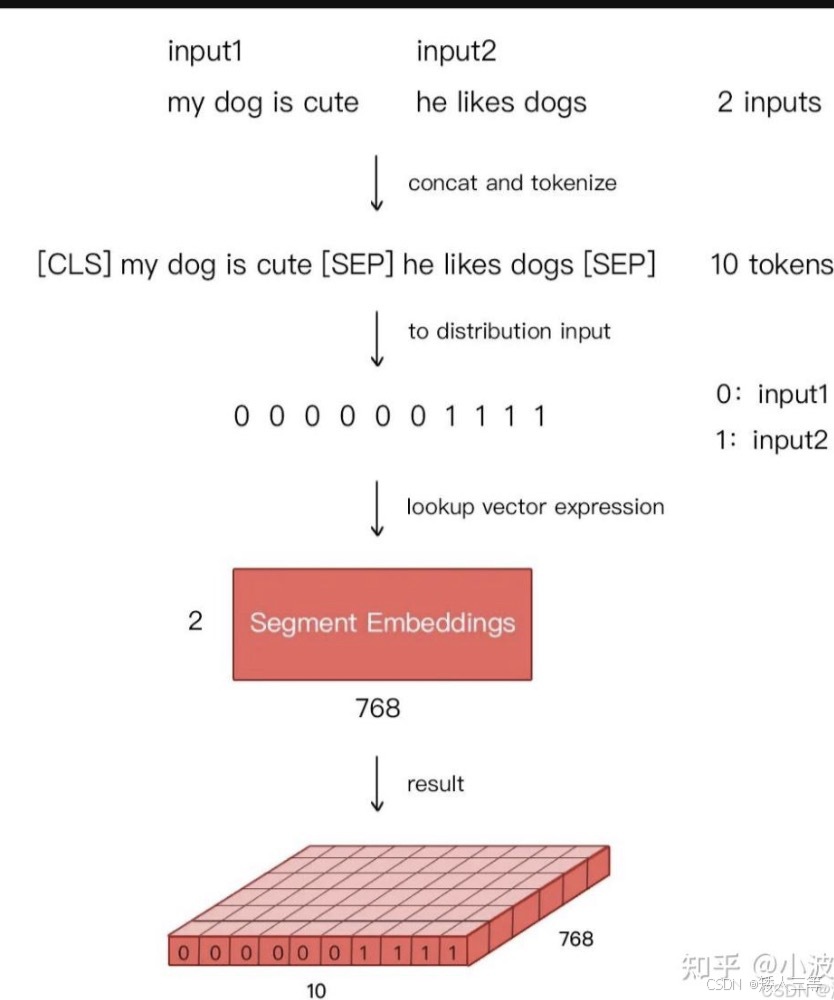
- 1 预训练阶段:用大量的无监督文本通过自监督(无需人工标注)训练的方式( MLP 和 NSP)训练
- 输入:与 transform 类似,也是词Embedding+位置 Embedding 向量对应相加作为输入A,如果是句子对的情况还需要加上归属标记向量
- 但是句子开头有标识符Embeding [CLS]和句子末尾的[SEP]作为输入 B,A 和 B 构成了输入,注意,是拼接不是对应相加, 其中位置向量不是正余弦位置了,和 CLS 和 SEP 一样,都是从初始随机变量随机训练"可学习"的
- transform 因为是单向的所以在输入的时候使用了 mask 矩阵,而bert 是不需要的,但是两个模型都是有"答案"对比的,不然无法反向传播进行训练
- MLM:先从输入中随机抽取 15%,准备进行处理,在这 15% 中,80% 概率直接 mask,10% 替换其他单词,10% 不动
- 10% 概率直接替换成其他单词,这有助于模型学习理解上下文的重要性,而不仅仅是依赖于[MASK]标记
- 10% 概率原封不动; 这有助于模型在微调阶段更好地处理未遮蔽的单词
- NSP:语料库中随机抽取两个句子,判断是不是上下文;
- 在BERT的后续版本中,Next Sentence Prediction(NSP)任务被废弃了。因为研究人员发现这个任务对下游任务的性能提升有限
- 举例:
每个token的输入 = 自身向量(可学习) + 位置向量(可学习) + 句子归属向量(固定0/1) [CLS] → 自身向量(初始随机:[0.2, -0.1, 0.3]) + 位置向量(第1位:[0.5, 0.02, -0.1]) + 句子归属向量(句1:[0, 0, 0]) = 最终输入向量:[0.7, -0.08, 0.2] 👉 不是固定值,训练中会变 "我" → 自身向量(初始随机:[0.8, 0.4, -0.2]) + 位置向量(第2位:[0.4, 0.05, -0.05]) + 句子归属向量(句1:[0, 0, 0]) = 最终输入向量:[1.2, 0.45, -0.25] ...(中间"爱""吃""苹果"同理,都是各自向量相加,归属向量全为0)... [SEP] → 自身向量(初始随机:[-0.3, 0.6, 0.2]) + 位置向量(第6位:[0.1, 0.01, -0.15]) + 句子归属向量(句1:[0, 0, 0]) = 最终输入向量:[-0.2, 0.61, 0.05] "它" → 自身向量(初始随机:[0.1, -0.3, 0.7]) + 位置向量(第7位:[0.08, 0.005, -0.18]) + 句子归属向量(句2:[1, 1, 1]) 👉 句2专属标记,和句1区分 = 最终输入向量:[1.18, -0.295, 0.52] ...(中间"很""甜"同理,归属向量全为1)... [SEP] → 自身向量(初始随机:[-0.3, 0.6, 0.2]) + 位置向量(第10位:[0.02, 0, -0.2]) + 句子归属向量(句2:[1, 1, 1]) = 最终输入向量:[0.72, 1.6, 1.0] - 2 微调阶段:BERT首先使用预训练的参数初始化模型,所有参数都使用下游任务的标签数据进行微调,每个不同的下游任务都有单独的微调模型
- bert 的主干就是多个 transform 的 encode 叠加,为了深入理解语义,但是具体任务使用还是需要在输出层(主干部分微调)进行微调处理
- 微调任务包含:
- 基于句子对的分类任务:核心共性:输入是 “句 1 + 句 2”,用 [CLS] 汇总全局语义,输出层做分类 / 回归,复用句对归属标记(0/1)
- MNLI:自然语言推理) 输出层:线性层 + Softmax(三分类:蕴含 / 矛盾 / 中立);目的:判断句 2 是否能从句 1 推出。
- QQP(Quora 问答匹配):输出层:线性层 + Softmax(二分类:两问题是否语义相同);目的:判断两个问题是否是同一问题的不同表述。
- QNLI(问答自然语言推理)输出层:线性层 + Softmax(二分类:段落句子是否能回答问题);目的:筛选能回答问题的句子。
- STS-B(语义文本相似度):输出层:线性层(回归任务,输出 0~5 的相似度分数);目的:量化两句话的语义相似程度。
- MRPC(微软同义句匹配):输出层:线性层 + Softmax(二分类:是否同义);目的:判断两句话是否语义等价。
- RTE(文本蕴含识别):输出层:线性层 + Softmax(二分类:蕴含 / 不蕴含);目的:简化版 MNLI,只判断是否蕴含。
- SWAG(情境推理)输出层:线性层 + Softmax(四分类:从 4 个候选后半句选最连贯的);目的:判断哪个候选句能承接前半句的情境。
- 基于单个句子的分类任务:核心共性:输入是单句,不用句对标记(全标 0),[CLS] 汇总语义,输出层分类。
- SST-2(情感分类):输出层:线性层 + Softmax(二分类:正面 / 负面);目的:判断句子情感倾向。
- ColA(语言可接受性判断):输出层:线性层 + Softmax(二分类:句子是否语法 / 语义通顺);目的:判断句子是否是自然语言(比如 “我吃饭” 可接受,“饭吃我” 不可接受)。
- 问答任务:核心:输入是 “问题 + 原文段落”,输出层预测答案的 “起始 / 结束位置”,不做分类做定位。
- SQuAD:输出层:两个独立线性层(一个预测答案起始位置,一个预测结束位置);
- 目的:从原文中找到问题的答案片段(比如问题 “李白生于哪年?”,原文 “李白生于 701 年”,预测起始 = 3,结束 = 5)。
- SQuAD:输出层:两个独立线性层(一个预测答案起始位置,一个预测结束位置);
- 命名实体识别NER:核心:输入是单句,输出层对 “每个词” 做分类(不是 [CLS] 汇总),识别实体类型。
- CoNLL-2003 NER:输出层:给每个 token 配一个线性层 + Softmax(多分类:PER 人 / ORG 机构 / LOC 地点 / O 非实体);
- 目的:给每个词打实体标签(比如 “李白(PER)生于 701 年,是唐代(ORG)诗人”)。
- CoNLL-2003 NER:输出层:给每个 token 配一个线性层 + Softmax(多分类:PER 人 / ORG 机构 / LOC 地点 / O 非实体);
- 基于句子对的分类任务:核心共性:输入是 “句 1 + 句 2”,用 [CLS] 汇总全局语义,输出层做分类 / 回归,复用句对归属标记(0/1)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











