




 提出一种新的生成模型估计过程,通过两个模型的对抗训练来捕捉数据分布:生成模型G和判别模型D。G的目标是产生难以区分的真实样本,而D则试图准确地区分真实数据与G产生的样本。
提出一种新的生成模型估计过程,通过两个模型的对抗训练来捕捉数据分布:生成模型G和判别模型D。G的目标是产生难以区分的真实样本,而D则试图准确地区分真实数据与G产生的样本。
(NIPS 2014) Generative Adversarial Nets
Paper: https://papers.nips.cc/paper/5423-generative-adversarial-nets
Code: http://www.github.com/goodfeli/adversarial
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G.
The training procedure for G is to maximize the probability of D making a mistake.
This framework corresponds to a minimax two-player game.
Introduction
Deep generative models have had less of an impact, due to the difficulty of approximating many intractable probabilistic computations that arise in maximum likelihood estimation and related strategies, and due to difficulty of leveraging the benefits of piecewise linear units in the generative context.
We propose a new generative model estimation procedure that sidesteps these difficulties.
The generative model can be thought of as analogous to a team of counterfeiters, trying to produce fake currency and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency.
we can train both models using only the highly successful backpropagation and dropout algorithms [17] and sample from the generative model using only forward propagation. No approximate inference or Markov chains are necessary.
Related work
Adversarial nets
D and G play the following two-player minimax game with value function V(G,D) :
Optimizing D to completion in the inner loop of training is computationally prohibitive, and on finite datasets would result in overfitting. Instead, we alternate between k steps of optimizing D and one step of optimizing G.
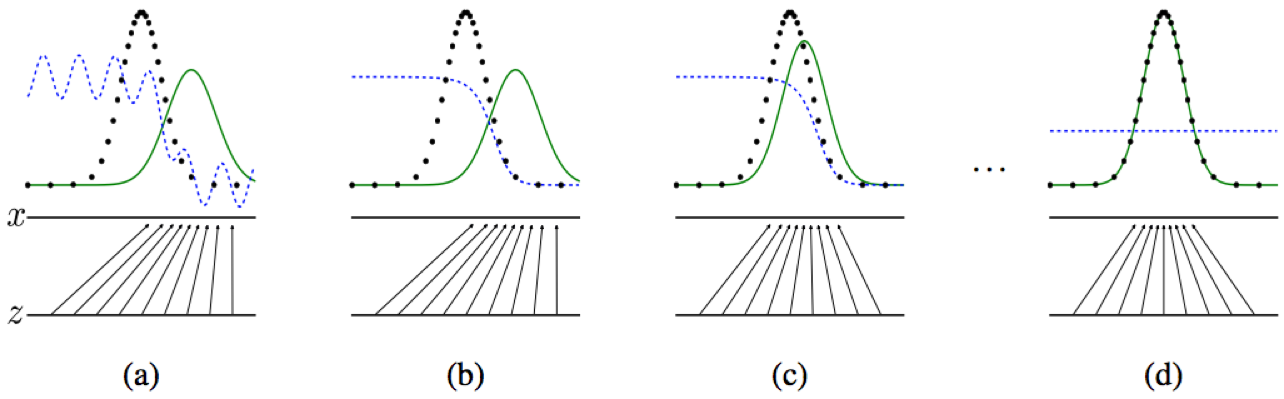
Figure 1: Generative adversarial nets are trained by simultaneously updating the discriminative distribution (D, blue, dashed line) so that it discriminates between samples from the data generating distribution (black, dotted line) px from those of the generative distribution pg (G) (green, solid line).
The lower horizontal line is the domain from which z is sampled, in this case uniformly.
The horizontal line above is part of the domain of
The upward arrows show how the mapping x=G(z) imposes the non-uniform distribution pg on transformed samples.
G contracts in regions of high density and expands in regions of low density of pg .
(a) Poorly fit model
(b) After updating D
(c) After updating G
(d) Mixed strategy equilibrium
Theoretical Results
Global Optimality of pg=pdata
Convergence of Algorithm 1
Experiments
We trained adversarial nets an a range of datasets including MNIST[23], the Toronto Face Database (TFD) [28], and CIFAR-10 [21].


















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









