### PSPNet 语义分割网络架构
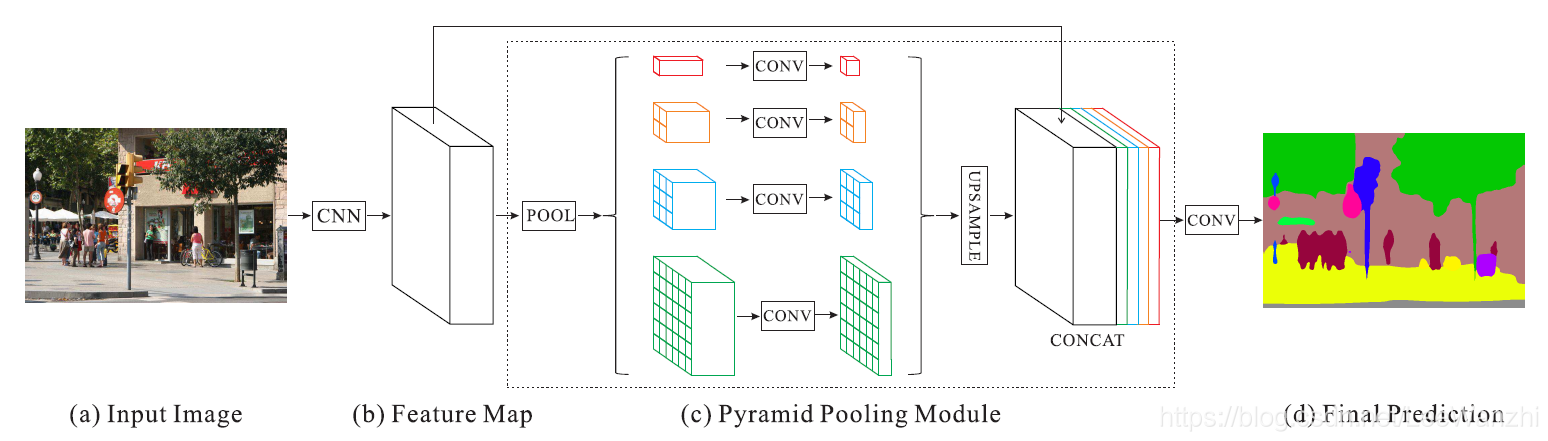
PSPNet(Pyramid Scene Parsing Network)是一种先进的图像语义分割模型,其设计旨在解决传统卷积神经网络在处理多尺度物体时遇到的挑战。该网络引入了一个独特的组件——金字塔池化模块(Pyramid Pooling Module),使得模型能够在多个尺度上捕捉全局上下文信息。
#### 架构详解
1. **基础骨干网络**
骨干网络通常采用预训练的深度卷积神经网络,如ResNet系列。这些网络负责提取输入图像的基础特征[^2]。
2. **金字塔池化模块 (PPM)**
PPM 是 PSPNet 的核心创新之一。它通过对特征图应用不同大小的感受野来聚合多层次的信息。具体来说,PPM 将特征图划分为若干子区域并执行最大池化操作,随后将得到的结果重新组合成完整的特征表示。这种机制有助于增强对大范围背景的理解以及改善边界细节的表现力[^3]。
3. **融合层**
经过 PPM 处理后的特征会被与原始分辨率下的低级特征相结合,形成最终用于分类预测的高维特征向量。这一过程确保了局部纹理和整体布局都能被充分考虑进去。
4. **输出分支**
最终,经过一系列卷积运算后产生的特征映射会通过一个 softmax 层转换为像素级别的类别概率分布,进而完成整个语义分割任务。
```python
import torch.nn as nn
from torchvision.models import resnet50, ResNet50_Weights
class PSPModule(nn.Module):
def __init__(self, features, out_features=1024, sizes=(1, 2, 3, 6)):
super().__init__()
self.stages = []
self.stages = nn.ModuleList([self._make_stage(features, size) for size in sizes])
self.bottleneck = nn.Conv2d(features * 2, out_features, kernel_size=1)
self.relu = nn.ReLU()
def _make_stage(self, features, size):
prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
conv = nn.Conv2d(features, features, kernel_size=1, bias=False)
return nn.Sequential(prior, conv)
def forward(self, feats):
h, w = feats.size(2), feats.size(3)
priors = [F.interpolate(input=stage(feats), size=(h, w), mode='bilinear', align_corners=True) for stage in self.stages] + [feats]
bottle = self.bottleneck(torch.cat(priors, 1))
return self.relu(bottle)
class PSPUpsample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.PReLU()
)
def forward(self, x):
h, w = 2 * x.size(2), 2 * x.size(3)
p = F.interpolate(input=x, size=(h, w), mode='bilinear', align_corners=True)
return self.conv(p)
class PSPNet(nn.Module):
def __init__(self, n_classes=21, sizes=(1, 2, 3, 6), psp_size=2048, deep_features_size=1024, backend='resnet50'):
super().__init__()
backbone = resnet50(weights=ResNet50_Weights.IMAGENET1K_V1).features[:-1]
self.feats = nn.Sequential(*list(backbone.children())[:7]) # Extracts up to layer 7 of the pretrained model.
self.psp = PSPModule(psp_size, 1024, sizes)
self.drop_1 = nn.Dropout2d(p=0.3)
self.up_1 = PSPUpsample(1024, 256)
self.up_2 = PSPUpsample(256, 64)
self.up_3 = PSPUpsample(64, 64)
self.final = nn.Sequential(
nn.Conv2d(64, n_classes, kernel_size=1),
nn.LogSoftmax(dim=1)
)
self.classifier = nn.Linear(deep_features_size, n_classes)
def forward(self, x):
f = self.feats(x)
p = self.psp(f)
p = self.drop_1(p)
u1 = self.up_1(p)
u2 = self.up_2(u1)
u3 = self.up_3(u2)
return self.final(u3)
```










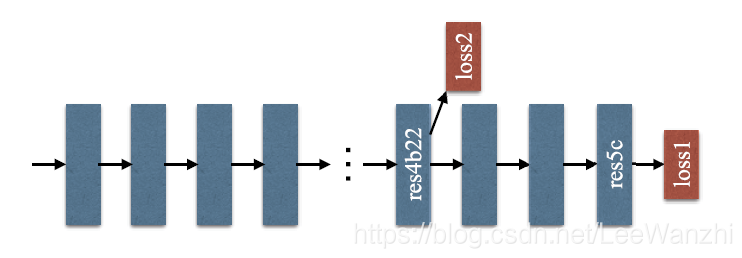
 本文探讨了如何通过采用多尺度池化策略和金字塔池化结构来解决图像分类中常见的问题,如上下文语义关系理解不足、相似类混淆及不显眼类别的识别。此外,针对ResNet网络,引入了辅助损失层以简化优化过程,提高模型性能。
本文探讨了如何通过采用多尺度池化策略和金字塔池化结构来解决图像分类中常见的问题,如上下文语义关系理解不足、相似类混淆及不显眼类别的识别。此外,针对ResNet网络,引入了辅助损失层以简化优化过程,提高模型性能。

















 2339
2339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









