





文章目录
前言
Redis 中的 string 类型是最基本的数据类型之一,尽管它看似简单,底层的实现却非常巧妙和高效。为了更好地处理不同长度的字符串并优化内存和性能,Redis 使用了多种数据结构和编码方案。这篇文章将详细解析 Redis 中 string 底层的实现机制,重点关注 SDS(Simple Dynamic String),以及 Redis 针对字符串的不同编码策略。
string 的编码方式
在 Redis 中,字符串的底层存储方式并不是一成不变的,而是根据字符串的实际情况动态选择不同的编码。主要有以下三种编码:
- 整数编码(int):当字符串可以被解析为整数时,Redis 会将其以整数的形式存储。
- embstr 编码:用于存储较短的字符串(小于 44 44 44 字节)。
- raw 编码:用于存储较长的字符串(大于 44 44 44 字节)。
这些编码的选择由 Redis 自动完成,用户不需要手动干预。接下来我们将深入了解这些编码方式的底层结构和工作原理。
SDS(Simple Dynamic String)
Redis 的字符串并不是直接使用 C 语言的 char* 类型,而是使用了 SDS(简单动态字符串) 来管理字符串。SDS 是对传统 C 字符串的增强版本,它具有动态扩展、二进制安全等特性。
SDS 的数据结构
SDS 的底层结构如下所示:
struct sdshdr {
int len; // 当前字符串的长度
int free; // 剩余的空闲空间
char buf[]; // 实际存储字符串的字符数组,末尾以 '\0' 结束
};
- len:表示当前字符串的长度。
- free:表示预留的空闲空间,可以用来追加字符串。
- buf[]:实际存储字符串内容的字符数组,并且末尾带有
\0,这使 SDS 兼容 C 语言的字符串操作。
例如,如果我们存储字符串 "Hello",此时 SDS 的状态可能是:
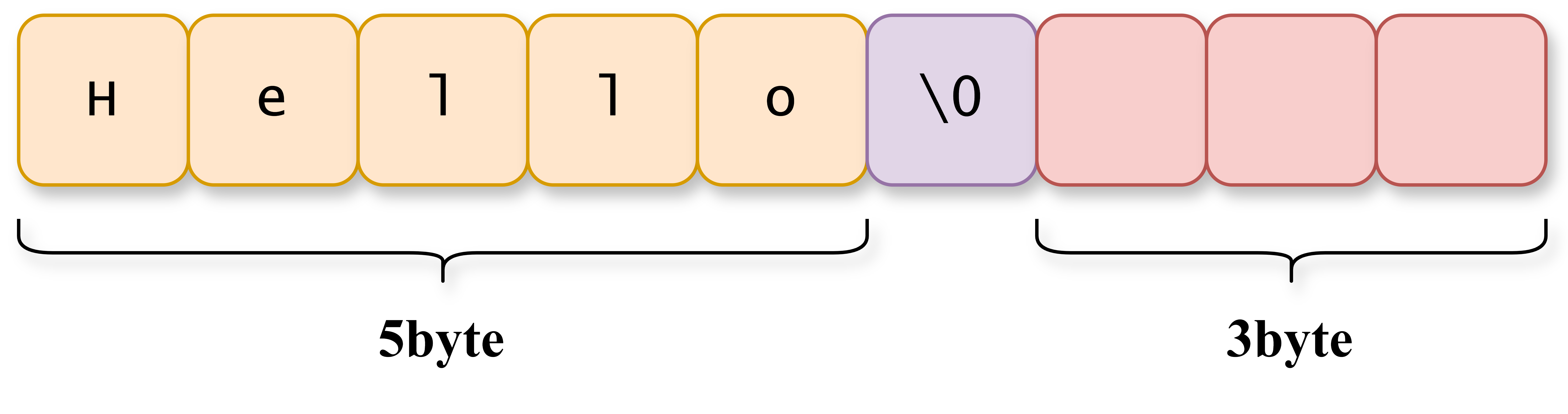
- len = 5,表示当前字符串的长度为 5 5 5 字节。
- free = 3,表示有 3 3 3 字节的预留空间用于追加操作。
- buf =
"Hello\0",实际存储内容为"Hello",并以\0结束。
SDS 的动态扩展机制
SDS 最具特色的功能之一是其动态扩展机制。每当追加字符串导致当前 free 空间不足时,SDS 会自动扩展内存。它通过一种 空间预分配策略 来减少频繁的内存分配,优化性能。
内存扩展的步骤:
Step1:首先计算追加操作后字符串的总长度。
Step2:根据当前字符串长度决定扩展策略:
- 如果字符串长度小于 1MB,则采用 加倍扩展 策略,新分配的内存大小为当前字符串长度的 2 2 2 倍。
- 如果字符串长度超过 1MB,则每次额外分配
1MB的空间。
Step3:使用底层的 realloc 函数重新分配内存,更新 SDS 的元数据,复制原有内容,并追加新的字符串。
例如,假设当前 SDS 存储的字符串为 "Hello",len 为
5
5
5,free 为
3
3
3,现在要追加字符串 ", World",长度为
7
7
7 字节。
- 由于
free只有 3 3 3 字节,无法容纳 7 7 7 字节的新内容,因此触发内存扩展。 - 追加后的字符串长度为 12 12 12 字节(“Hello, World”)。
- 因为新长度小于
1MB,SDS 采用加倍扩展策略,新的内存大小为 12 × 2 = 24 12 \times 2 = 24 12×2=24 字节。 - 扩展后,SDS 的状态变为:
- len = 12,表示新字符串的长度。
- free = 12,表示还有 12 12 12 字节的可用空间。
- buf =
"Hello, World\0",存储追加后的字符串。
SDS 的惰性空间释放
当字符串缩短时,SDS 不会立即释放多余的内存,而是将其保留在 free 中,以便未来的追加操作使用。这种策略被称为 惰性空间释放。它减少了频繁的内存分配和释放操作,从而提高性能。
例如,将 "Hello, World" 缩短为 "Hello",新的 SDS 状态为:
- len = 5,表示当前使用了 5 5 5 字节。
- free = 19,表示剩余 19 19 19 字节的可用空间。
- 字符串内容
"Hello"保持不变,但未来如果追加内容,可以直接使用free空间,而无需再次分配内存。
二进制安全
SDS 的一个重要特性是 二进制安全。C 语言的字符串必须以 \0 作为结束符,无法存储包含 \0 的二进制数据。而 SDS 通过记录字符串的长度(len),允许字符串中间出现 \0,因此可以安全存储任何二进制数据。
string 的编码策略
根据字符串的具体内容和长度,Redis 会在三种编码方式之间进行自动切换:
- 整数编码
- embstr 编码
- raw 编码。
整数编码
当字符串能够被解析为整数时,Redis 会使用 整数编码。这种方式非常节省内存,且方便进行数值操作。
例如,我们存储字符串 "12345",Redis 会将其转换为整数
12345
12345
12345,并以整数形式存储,而不是存储字符。这样既节省了内存,又可以高效地进行数值操作,比如 INCR 命令。
embstr 编码
embstr 是专门用于存储短字符串(长度小于 44 44 44 字节)的一种优化编码方式。它将 SDS 的元数据和实际字符串内容一次性分配在一块连续的内存中,从而减少内存分配次数。
例如,对于 "Hello" 这种较短的字符串,Redis 会使用 embstr 编码,将 SDS 的结构和字符串内容放在同一个内存块中。这种编码方式非常高效,因为分配和释放内存时只需要一次操作。
raw 编码
raw 编码 用于存储较长的字符串(长度大于 44 44 44 字节)。与 embstr 编码不同,raw 编码将 SDS 的头部和字符串内容分别存储在不同的内存区域。这种方式适合处理较大的字符串。
例如,我们存储一个较长的字符串,比如 "This is a long string for Redis",其长度超过
44
44
44 字节,Redis 会使用 raw 编码。此时,SDS 的头部和字符串内容被分配到不同的内存块中,从而更好地管理大块内存。
编码的动态切换
Redis 会根据字符串的实际情况动态切换编码方式:
- 当字符串是整数时,使用 整数编码。
- 当字符串较短时,使用 embstr 编码。
- 当字符串较长时,使用 raw 编码。
例如,如果一个字符串最初是短的,并且使用了 embstr 编码,当它变得很长时(超过 44 44 44 字节),Redis 会自动将其编码切换为 raw 编码。这样可以在短字符串时提高效率,而在长字符串时灵活管理内存。
小结
Redis 对字符串的存储设计了多种优化策略,通过 SDS 提供了动态扩展、二进制安全和高效内存管理的功能。结合整数编码、embstr 编码和 raw 编码,Redis 能够根据字符串的内容和长度选择最合适的存储方式,从而最大限度地优化内存使用和操作性能。
Redis 中字符串的底层实现不仅解决了 C 字符串的缺点,还提供了更强的灵活性和更高的效率,是 Redis 高效处理数据的核心机制之一。


















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









