




 本文详细介绍了QT中的各种容器,包括顺序容器QList, QLinkedList, QVector, QStack, QQueue和关联容器QMap, QMultiMap, QHash, QMultiHash, QSet。讨论了它们的特性,如隐式共享、迭代器类型、算法复杂度和增长策略。QT容器支持Java风格和STL风格迭代器,其中STL风格在效率上有优势。文章还提到了容器中值类型的限制,如要求类型具有复制构造函数和赋值运算符。此外,还分析了隐式共享的优缺点,提醒在使用STL风格迭代器时需注意容器的复制问题。"
95011811,7294788,Kafka序列化器深度解析:StringSerializer示例,"['Kafka', '序列化', '消息传递', '数据编码', 'Java']
本文详细介绍了QT中的各种容器,包括顺序容器QList, QLinkedList, QVector, QStack, QQueue和关联容器QMap, QMultiMap, QHash, QMultiHash, QSet。讨论了它们的特性,如隐式共享、迭代器类型、算法复杂度和增长策略。QT容器支持Java风格和STL风格迭代器,其中STL风格在效率上有优势。文章还提到了容器中值类型的限制,如要求类型具有复制构造函数和赋值运算符。此外,还分析了隐式共享的优缺点,提醒在使用STL风格迭代器时需注意容器的复制问题。"
95011811,7294788,Kafka序列化器深度解析:StringSerializer示例,"['Kafka', '序列化', '消息传递', '数据编码', 'Java']
目录
1>、顺序容器:QList,QLinkedList,QVector,QStack 和 QQueue
2>、关联容器:QMap,QMultiMap,QHash,QMultiHash 和 QSet
一、前言:
如果想看 STL容器 的优缺点,请查看如下文章:
《C++ STL容器 底层数据结构》 https://blog.youkuaiyun.com/LearnLHC/article/details/89552420?spm=1001.2014.3001.5502
《c++ map、multimap 的使用方法》 https://blog.youkuaiyun.com/LearnLHC/article/details/89536774?spm=1001.2014.3001.5502
《QTL 容器 与 STL(1)- 写时复制》https://blog.youkuaiyun.com/LearnLHC/article/details/91983462
二、QT 容器
2.1、简述
这些类都是 隐式共享 和 可重入 的
隐式共享:仅在被写入时才被拷贝;仅读数据时,多个变量共享一块空间
可重入:首先它意味着这个函数可以被中断,其次意味着它除了使用自己栈上的变量以外不依赖于任何环境(包括static),这样的函数就是可重入,可以允许有多个该函数的副本在运行,由于它们使用的是分离的栈,所以不会互相干扰。反例:全局变量(如:static)
且针对几个方面做了优化:
一是速度,二是较低的内存占用,三是尽可能少的内联代码,减少生成程序的体积。
另外,在所有线程都以只读的方式访问容器时,这些类是线程安全的。
要遍历容器中的元素,你可以使用两种风格迭代器:
Java 风格迭代器和 STL 风格迭代器。
Java 风格迭代器有更好的易用性和更高级的函数,
而 STL 风格迭代器则在效率上会略有优势,并且可以用于 Qt 和 STL 提供的泛型算法中。
Qt 还提供了 foreach 关键字,可以方便地遍历容器。
2.2、容器分类
1>、顺序容器:QList,QLinkedList,QVector,QStack 和 QQueue
对于大多数的应用,QList 是最适用的。虽然其基于数组实现,但支持在头部和尾部快速插入。
如果确实需要一个基于链表的列表,你可以使用 QLinkedList。
如果要求元素以连续内存的形式保存,那么可以使用 QVector。
2>、关联容器:QMap,QMultiMap,QHash,QMultiHash 和 QSet
"Multi" 容器可以方便地支持键值一对多的情形。
“Hash” 容器提供了快速查找的能力,这是通过使用哈希函数代替对有序集合进行二分查找实现的。
2.3、QT 各容器简述
| 类 | 综述 |
|---|---|
| QList | 这是目前使用最普遍的容器类,其保存了一个元素类型为T的列表,支持通过索引访问。QList 内部通过数组实现,以确保基于索引的访问足够快。元素可以通过 QList::append() 和 QList::prepend() 插入到首尾,也可以通过 QList::insert() 插入到列表中间,和其他容器类不同的是,QList 为生成尽可能少的代码做了高度优化。QStringList 继承于 QList<QString>。 |
| QLinkedList) | 这个类和 QList 很像,不同的是这个类使用迭代器进行而不是整形索引对元素进行访问。和 QList 相比,其在中间插入大型列表时其性能更优,而且其具有更好的迭代器语义。(在 QLinkedList 中,指向一个元素的迭代器只要该元素存在,则会一直保持有效,而在 QList 的迭代器则可能会在任意的元素插入或删除后失效。) |
| QVector | 这个类以数组的形式保存给定类型的元素,在内存中元素彼此相邻。在一个 vector 的头部或中部插入可能会相当慢,因为这可能会导致大量元素需要在内存中移动一个位置。 |
| QVarLengthArray<T, Prealloc> | 这个类提供了一个底层的变长数组,在速度极其重要的情况下可以用来代替 QVector |
| QStack | 这个类继承于 QVector,用于为”后进,先出”(LIFO )提供便捷的语义支持。其为 QVector 添加了以下方法:QVector::push(),pop() 和 top() |
| QQueue | 这个类继承于 QVector,用于为”先进,先出”(FIFO )提供便捷的语义支持。其为 QVector 添加了以下方法:QList::enqueue(),dequeue() 和 head() |
| QSet | 这个类提供了一个单值数学集合,支持快速查找 |
| QMap<Key, T> | 这个类提供了一个将类型为Key的键映射到类型为T的值的字典(关联数组)。通常情况下键值是一一对应的。QMap 根据Key进行排序,如果排序无关紧要,使用 QHash 代替速度会更快 |
| QMultiMap<Key, T> | 这个类继承于 QMap,其为诸如键值一对多的多值映射提供了一个友好的接口 |
| QHash<Key, T> | 这个类几乎与 QMap 有完全一致的 API ,但查找效率会有明显的提高。QHash 的数据是无序的。 |
| QMultiHash | 这个类继承于 QMap,其为多值映射提供了一个友好的接口 |
2.4、保存在 容器内的 值的类型 限制
1>、通用限制:
保存在各个容器中的值类型可以是任意 可复制数据类型。
为了满足这一要求,该类型必须提供一个 复制构造函数 和一个 赋值运算符。
某些操作可能还要求类型支持默认构造函数。
对于大多数你想要在容器中保存的类型都满足这些要求,包括基本类型,如 int, double,指针类型,以及 Qt 数据类型,如 QString,QDate 和 QTime
但并不包括 QObject 及其子类(QWidget,QDialog,QTimer 等)。
如果你尝试实例化一个 QList<QWidget>,编译器将会抱怨道 QWidget 的复制构造函数和赋值运算符被禁用了。
例子 - 自定义数据类型
class Employee
{
public:
Employee() {} //默认构造函数;
Employee(const Employee &other); //拷贝构造函数;
Employee &operator=(const Employee &other); //赋值操作符;
private:
QString myName;
QDate myDateOfBirth;
};如果我们没有提供一个复制构造函数或一个赋值运算符,C++ 将会提供一个表现为逐个复制成员的默认实现。
在上面的例子中,默认行为就足够了。
同样的,如果没有提供默认构造函数,C++ 会提供一个默认构造函数,对成员进行默认构造。
尽管没有提供任何的构造函数或赋值运算符,下面的数据类型可以被保存于容器中。
struct Movie
{
int id;
QString title;
QDate releaseDate;
};2>、个别容器 独有的限制:
一些容器对它们所能保存的数据类型有额外的要求。
如:QMap<Key, T> 的键类型 Key 必须提供 operator<() 方法。
这些特殊要求在类的详细描述中有说明。在某些情况下,特定函数会有特定的要求,这在函数的描述中有说明。如果条件不满足,编译器将总是会报错。
Qt容器 提供了 operator<<() 和 operator>>(),因此这些类可以很方便地通过 QDataStream 进行读写。
这意味着存储在容器中的元素类型也必须支持
operator<<()和operator>>()
三、 迭代器类
Qt 容器类提供了两种风格迭代器:
Java 风格迭代器 和 STL 风格迭代器。
注意:
两种迭代器均会在容器中的数据 被修改 或 因调用非 const 成员函数,导致数据从 隐式共享 中分离后失效。
3.1、 Java 风格迭代器
1>、两种方法
对于每一个容器类,同时提供了两种数据类型的 Java 风格迭代器:一种支持只读访问,另一种支持读写访问。
| 容器 | 只读迭代器 | 读写迭代器 |
|---|---|---|
| QList, QQueue | QListIterator | QMutableListIterator |
| QLinkedList | QLinkedListIterator | QMutableLinkedListIterator |
| QVector, QStack | QVectorIterator | QMutableVectorIterator |
| QSet | QSetIterator | QMutableSetIterator |
| QMap<Key, T>, QMultiMap<Key, T> | QMapIterator<Key, T> | QMutableMapIterator<Key, T> |
| QHash<Key, T>, QMultiHash<Key, T> | QHashIterator<Key, T> | QMutableHashIterator<Key, T> |
2>、与 STL 风格迭代器不同①:
Java 风格迭代器 指向 的是元素 间隙 而不是元素本身。
因此,Java 风格迭代器可以指向容器最前(在第一个元素之前),也可以指向容器最后(在最后一个元素之后),还可以指向两个元素之间。
下图用红色箭头展示了一个四个元素的列表容器合法的迭代器位置。
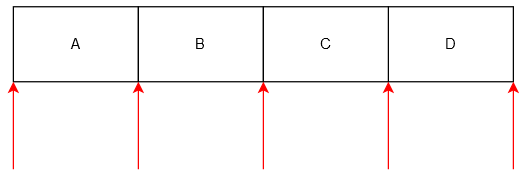
3>、与 STL 迭代器的不同②:
Java 风格迭代器:对 remove() 方法的调用 不会导致迭代器的失效
3.2、 STL 风格迭代器 - 比 Java 风格快
1>、两种方法:
对于每一个容器类,同时提供了两种类型的 STL 风格迭代器:一种支持只读访问,另一种支持读写访问。
| 容器 | 只读迭代器 | 读写迭代器 |
|---|---|---|
| QList, QQueue | QList::const_iterator | QList::iterator |
| QLinkedList | QLinkedList::const_iterator | QLinkedList::iterator |
| QVector, QStack | QVector::const_iterator | QVector::iterator |
| QSet | QSet::const_iterator | QSet::iterator |
| QMap<Key, T>, QMultiMap<Key, T> | QMap<Key, T>::const_iterator | QMap<Key, T>::iterator |
| QHash<Key, T>, QMultiHash<Key, T> | QHash<Key, T>::const_iterator | QHash<Key, T>::iterator |
2>、和 Java 风格迭代器不同
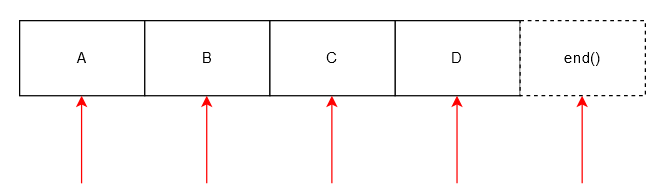
STL 风格迭代器 直接指向元素本身
容器的 begin() 方法会返回一个指向容器第一个元素的迭代器,end() 方法返回的迭代器指向一个虚拟的元素,该元素位于容器最后一个元素的下一个位置。
end() 标记了一个非法的位置,永远不要对其解引用。
其通常被用作循环的结束条件。
对于空列表,begin() 和 end() 是相等的,因此我们永远不会执行循环。
下图用红色箭头展示了一个四个元素的列表容器中合法的迭代器位置。
四、 隐式共享
4.1、优势:
正是因为隐式共享,调用一个返回容器的函数的开销不会很大 (容器间拷贝)。
Qt API 中包含几十个返回值为 QList 或 QStringList 的函数(例如 QSplitter::sizes() )。
如果需要通过 STL 迭代器遍历这些返回值,你应当总是将返回的容器复制一份然后迭代其副本。例如:
// 正确
const QList<int> sizes = splitter->sizes();
QList<int>::const_iterator i;
for (i = sizes.begin(); i != sizes.end(); ++i)
...
// 错误
QList<int>::const_iterator i;
for (i = splitter->sizes().begin();
i != splitter->sizes().end(); ++i)
...
如果函数返回的是一个容器的常量或非常量引用,那么是不存在这个问题的。
4.2、劣势 - 可能出现错误
隐式共享给 STL 风格迭代器带来了另一个后果是:
当一个容器的迭代器 在使用时 你应当避免复制该容器。
迭代器指向了一个内部结构,当你复制容器时你需要特别小心的处理迭代器。比如:
QVector<int> a, b;
a.resize(100000); // 创建一个填充0的大数组.
QVector<int>::iterator i = a.begin();
// 迭代器i的错误用法:
b = a;
/*
现在我们应当小心地使用迭代器`i`,因为 i 指向的是共享的数据。
如果我们执行 *i = 4 那么我们可能改变共享的实例(两个数组共享)
这个行为和 STL 容器是不同的。在 Qt 中不要这样做。
*/
a[0] = 5;
/*
容器 a 现在已经和共享数据脱离,
即使 i 之前是容器 a 的迭代器,但现在它是作为 b 的迭代器而存在。
此时 (*i) == 0
*/
b.clear(); // 此时 i 彻底失效
int j = *i; // 未定义行为!
/*
b 中的数据(即i 指向的)已经被释放,
在 STL 容器中这是有明确定义的((*i) == 5),
但对于 QVector 来说这样做很有可能导致崩溃。
*/五、算法复杂度
5.1、线性容器类的算法复杂度
| 线性查找 | 插入 | 头部追加 | 尾部追加 | |
|---|---|---|---|---|
| QLinkedList | O(n) | O(1) | O(1) | O(1) |
| QList | O(1) | O(n) | Amort. O(1) | Amort. O(1) |
| QVector | O(1) | Amort. O(n) | O(n) | Amort. O(1) |
表中的 “Amort. ” 表示“均摊行为”。
例如,“Amort. O(1)” 表示如果仅调用一次该方法,你可能耗费 O(n) 的时间,但如果多次调用(假设调用 n 次),平均下来复杂度将会是 O(1)。
5.2、关联容器的算法复杂度
| 查找键 | 插入 | |||
|---|---|---|---|---|
| 平均 | 最坏情况 | 平均 | 最坏情况 | |
| QMap<Key, T> | O(log n) | O(log n) | O(log n) | O(log n) |
| QMultiMap<Key, T> | O(log n) | O(log n) | O(log n) | O(log n) |
| QHash<Key, T> | Amort. O(1) | O(n) | Amort. O(1) | O(n) |
| QSet | Amort. O(1) | O(n) | Amort. O(1) | O(n) |
对于 QVector,QHash 和 QSet,在尾部追加元素的时间复杂度均摊下来是 O(log n)。
但如果在插入元素之前以计划插入的元素个数 n 为参数调用 QVector::reserve(), QHash::reserve() 或 QSet::reserve(),复杂度将会降低至 O(1) 。
六、增长策略
6.1、各容器保存数据的方式:
QVector,QString 和 QByteArray 使用 连续内存 保存元素;
QList 维护了一个保存所有元素的指针(除非 T 本身是一个指针类型或一个指针大小的基本类型,这种情况下数组中保存的的是元素本身的值)的数组,用于提供基于索引的快速访问;
QHash<Key, T> 内部有一个和大小元素个数成正比的哈希表。
为了避免每次在尾部添加元素时重新分配内存,这些类通常会分配比实际需要要多的内存。
6.2、增长方式
1>、QString 增长策略
QString onlyLetters(const QString &in)
{
QString out;
for (int j = 0; j < in.size(); ++j) {
if (in[j].isLetter())
out += in[j];
}
return out;
}
我们通过每次追加一个字符的方式动态的构建了一个字符串。
假设我们追加 15000 个字符到这个 QString 字符串,接下来会在已分配内存耗尽时触发 QString 进行 18 次内存重新分配,
分别在已分配量为:4,8,12,16,20,52,116,244,500,1012,2036,4048,6132,8180,10228,12276,14324,16372时。
最后,这个 QString 占用了 16372 个 Unicode 字符的空间,其中 15000 个被实际使用了。
上面的数字可能有些奇怪,这里是分配的指导原则。
1、QString 每次分配 4 个字符指导达到 20 个字符。
2、从 20 到 4084 个字符,每次将当前的大小翻倍。更准确的说,是翻倍后再减去 12。
一些内存分配器在分配刚好两倍的内存时性能较差,因为它们需要使用每块内存块中的一些字节用于登记。
3、从 4084 开始,每次分配将会在原来的基础上增加 2048 个字符大小(4096 字节)。
这么做的意义是现代操作系统在重新分配内存时并不会复制全部的数据,而仅仅是简单地将物理内存页重新排序,只有第一页和最后一页的数据需要复制。
QByteArray 和 QList 使用和 QString 差不多的增长算法。
2>、QVector 增长策略
当数据类型支持通过 memcpy() 在内存中进行移动时(包括基本 C++ 类型,指针类型和 Qt 的隐式共享类),QVector 也使用相同的算法。
但在数据类型只支持通过复制构造函数和析构函数进行移动时则使用不同的算法:
在这种情况下,重新分配的开销会大的多,因此 QVector 将总是会在空间耗尽时直接申请两倍的内存,以减少重新分配的次数。
3>、QHash 增长策略
QHash<Key, T> 则是完全不同。
QHash 内部的哈希表每次增长两倍,每次增长时,保存的元素将会重新分配到一个通过 qHash(key) % QHash::capacity()(簇序号)计算出来的新的簇中。
此说明同样适用于 QSet 和 QCache<Key, T>。
4>、自定义调整 增长策略
对于大部分的应用,Qt 提供的增长策略完全可以满足需要。
如果你需要进行自定义调整,QVector, QHash<Key, T>, QSet, QString 和 QByteArray 提供了一个提供了三个方法用于检查和指定保存元素使用的内存量。
capacity() 用于返回已分配内存的元素个数(对于QHash 和 QSet,返回的是哈希表的簇的个数)。
reserve(size) 用于显式的预分配 size 个元素大小的内存。
squeeze() 用于释放所有没有用来保存元素的内存。
如果预先知道容器要保存元素的大概数量,可以提前调用 reserve() 方法分配内存,最后在填充完容器后,再调用 squeeze() 来释放多余的预分配内存。

















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









